FedAvg源码学习
代码来源:github包含:简介:data、models、save、utils封装了main_fed.py与main_nn.py所需的函数,main_fed.py来运行fedavg,main_nn.py来运行普通的NN。各部分代码及注释:(main_nn.py后续再补充)相关知识补充:matpltlib.use(‘agg’)argparse,argparse_argumenttorch.devic
-
本文旨在对FedAvg源码进行注释,以此实现FedAvg算法
-
代码来源:github
-
包含:

-
简介:data、models、save、utils封装了main_fed.py与main_nn.py所需的函数,main_fed.py来运行fedavg,main_nn.py来运行普通的NN。
-
各部分代码及注释:(main_nn.py后续再补充----已补)
-
相关知识补充:
matpltlib.use(‘agg’)
argparse , argparse_argument
torch.device() , torch.device()
copy(),deepcopy()
PyTorch state_dict
F.cross_entropy -
代码各部分及注释(Python3.6,Pycharm 2020.3.2(Edu))
0.main_nn.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torch.optim as optim
from torchvision import datasets, transforms
from utils.options import args_parser
from models.Nets import MLP, CNNMnist, CNNCifar
# 运行测试集并输出准确率与Loss大小(交叉熵函数,适用于多标签分类任务)
def test(net_g, data_loader):
# testing
net_g.eval()
test_loss = 0
correct = 0
l = len(data_loader)
for idx, (data, target) in enumerate(data_loader):
data, target = data.to(args.device), target.to(args.device)
log_probs = net_g(data)
test_loss += F.cross_entropy(log_probs, target).item()
y_pred = log_probs.data.max(1, keepdim=True)[1]
correct += y_pred.eq(target.data.view_as(y_pred)).long().cpu().sum()
test_loss /= len(data_loader.dataset)
print('\nTest set: Average loss: {:.4f} \nAccuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(data_loader.dataset),
100. * correct / len(data_loader.dataset)))
return correct, test_loss
# 与main_fed.py中的main函数相比,不调用fed.py即可
if __name__ == '__main__':
# parse args
args = args_parser()
args.device = torch.device('cuda:{}'.format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')
torch.manual_seed(args.seed)
# load dataset and split users
if args.dataset == 'mnist':
dataset_train = datasets.MNIST('./data/mnist/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
img_size = dataset_train[0][0].shape
elif args.dataset == 'cifar':
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset_train = datasets.CIFAR10('./data/cifar', train=True, transform=transform, target_transform=None, download=True)
img_size = dataset_train[0][0].shape
else:
exit('Error: unrecognized dataset')
# build model
if args.model == 'cnn' and args.dataset == 'cifar':
net_glob = CNNCifar(args=args).to(args.device)
elif args.model == 'cnn' and args.dataset == 'mnist':
net_glob = CNNMnist(args=args).to(args.device)
elif args.model == 'mlp':
len_in = 1
for x in img_size:
len_in *= x
net_glob = MLP(dim_in=len_in, dim_hidden=64, dim_out=args.num_classes).to(args.device)
else:
exit('Error: unrecognized model')
print(net_glob)
# training
optimizer = optim.SGD(net_glob.parameters(), lr=args.lr, momentum=args.momentum)
train_loader = DataLoader(dataset_train, batch_size=64, shuffle=True)
list_loss = []
net_glob.train()
for epoch in range(args.epochs):
batch_loss = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(args.device), target.to(args.device)
optimizer.zero_grad()
output = net_glob(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
batch_loss.append(loss.item())
loss_avg = sum(batch_loss)/len(batch_loss)
print('\nTrain loss:', loss_avg)
list_loss.append(loss_avg)
# plot loss
plt.figure()
plt.plot(range(len(list_loss)), list_loss)
plt.xlabel('epochs')
plt.ylabel('train loss')
plt.savefig('./log/nn_{}_{}_{}.png'.format(args.dataset, args.model, args.epochs))
# testing
if args.dataset == 'mnist':
dataset_test = datasets.MNIST('./data/mnist/', train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = DataLoader(dataset_test, batch_size=1000, shuffle=False)
elif args.dataset == 'cifar':
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset_test = datasets.CIFAR10('./data/cifar', train=False, transform=transform, target_transform=None, download=True)
test_loader = DataLoader(dataset_test, batch_size=1000, shuffle=False)
else:
exit('Error: unrecognized dataset')
print('test on', len(dataset_test), 'samples')
test_acc, test_loss = test(net_glob, test_loader)
1.main_fed.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
# 下面是自带库
import matplotlib
matplotlib.use('Agg') # 可理解为令pycharm不产生图片
import matplotlib.pyplot as plt
import copy
import numpy as np
from torchvision import datasets, transforms
import torch
# 下面是自建库
from utils.sampling import mnist_iid, mnist_noniid, cifar_iid # 引入了三种 iid 与 non-iid 数据库类型
from utils.options import args_parser # 导入程序运行对应选项,在终端cd到对应文件夹即可以所需方式运行程序,如:python main_fed.py --dataset mnist --num_channels 1 --model cnn --epochs 50 --gpu -1
from models.Update import LocalUpdate
from models.Nets import MLP, CNNMnist, CNNCifar
from models.Fed import FedAvg
from models.test import test_img
if __name__ == '__main__':
# parse args 解析参数
args = args_parser()
# 将torch.Tensor()进行分配到设备,来选择cpu还是gpu进行训练
args.device = torch.device('cuda:{}'.format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')
# load dataset and split users 加载数据集并进行用户分组
if args.dataset == 'mnist': # 如果用mnist数据集
# 数据集的均值与方差
trans_mnist = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
dataset_train = datasets.MNIST('../data/mnist/', train=True, download=True, transform=trans_mnist) # 训练集
dataset_test = datasets.MNIST('../data/mnist/', train=False, download=True, transform=trans_mnist) # 测试集
# sample users
if args.iid: # 如果是iid的mnist数据集
dict_users = mnist_iid(dataset_train, args.num_users) # 为用户分配iid数据
else:
dict_users = mnist_noniid(dataset_train, args.num_users) # 否则为用户分配non-iid数据
elif args.dataset == 'cifar': # 如果用cifar数据集
# 数据集均值与方差
trans_cifar = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset_train = datasets.CIFAR10('../data/cifar', train=True, download=True, transform=trans_cifar)
dataset_test = datasets.CIFAR10('../data/cifar', train=False, download=True, transform=trans_cifar)
if args.iid: # 如果是iid的cifar数据集
dict_users = cifar_iid(dataset_train, args.num_users) # 为用户分配iid数据
else: # cifar未设置non-iid数据
exit('Error: only consider IID setting in CIFAR10')
else:
exit('Error: unrecognized dataset')
# 设置图像的size
img_size = dataset_train[0][0].shape
# build model 选择模型
if args.model == 'cnn' and args.dataset == 'cifar':
net_glob = CNNCifar(args=args).to(args.device)
elif args.model == 'cnn' and args.dataset == 'mnist':
net_glob = CNNMnist(args=args).to(args.device)
elif args.model == 'mlp':
len_in = 1
for x in img_size:
len_in *= x
net_glob = MLP(dim_in=len_in, dim_hidden=200, dim_out=args.num_classes).to(args.device)
else:
exit('Error: unrecognized model')
print(net_glob)
net_glob.train()
# copy weights
w_glob = net_glob.state_dict()
# training
loss_train = []
cv_loss, cv_acc = [], []
val_loss_pre, counter = 0, 0
net_best = None
best_loss = None
val_acc_list, net_list = [], []
if args.all_clients: # 选择利用所有用户进行聚合
print("Aggregation over all clients")
w_locals = [w_glob for i in range(args.num_users)] # 每一个local的w与全局w相等
for iter in range(args.epochs):
loss_locals = [] # 对于每一个epoch,初始化worker的损失
if not args.all_clients: # 如果不是用所有用户进行聚合
w_locals = [] # 此时worker的w与全局w并不一致
m = max(int(args.frac * args.num_users), 1) # 此时,在每一轮中,在所有worker中选取C-fraction(C∈(0,1))部分进行训练,m为选取的worker总数
idxs_users = np.random.choice(range(args.num_users), m, replace=False) # 在所有的worker中(0,1,2...num_workers-1)选取m个worker(m = all_workers * C_fraction),且输出不重复
for idx in idxs_users: # 对于选取的m个worker
local = LocalUpdate(args=args, dataset=dataset_train, idxs=dict_users[idx]) # 对每个worker进行本地更新
w, loss = local.train(net=copy.deepcopy(net_glob).to(args.device)) #
if args.all_clients: # 如果选择全部用户
w_locals[idx] = copy.deepcopy(w)
else: # 并行
w_locals.append(copy.deepcopy(w))
loss_locals.append(copy.deepcopy(loss))
# update global weights
w_glob = FedAvg(w_locals) # 利用选取的局部w对全局w进行聚合更新,w_glob即为全局聚合更新后的值
# copy weight to net_glob
net_glob.load_state_dict(w_glob)
# print loss
loss_avg = sum(loss_locals) / len(loss_locals)
print('Round {:3d}, Average loss {:.3f}'.format(iter, loss_avg))
loss_train.append(loss_avg)
# plot loss curve 绘制损失函数曲线
plt.figure()
plt.plot(range(len(loss_train)), loss_train)
plt.ylabel('train_loss')
# plt.xlabel('epoch')
# plt.savefig('./save/fed_{}_{}_{}_C{}_iid{}.png'.format(args.dataset, args.model, args.epochs, args.frac, args.iid))
plt.savefig('C:\\Users\\xiaobingnan0224\\Desktop\\fed_mnist_CNN_non-iid_epochs50.png'.format(args.dataset, args.model, args.epochs, args.frac, args.iid))
# testing 在测试集上进行测试
net_glob.eval()
acc_train, loss_train = test_img(net_glob, dataset_train, args)
acc_test, loss_test = test_img(net_glob, dataset_test, args)
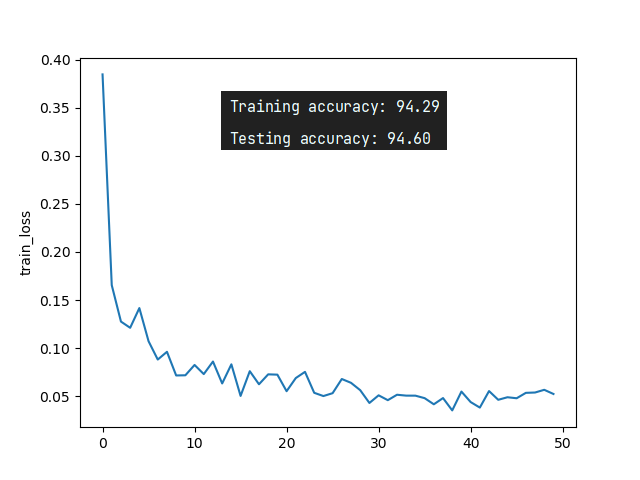
print("Training accuracy: {:.2f}".format(acc_train))
print("Testing accuracy: {:.2f}".format(acc_test))
2.options.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import argparse
'''
argparse 模块是 Python 内置的一个用于命令项选项与参数解析的模块,argparse 模块可以让人轻松编写用户友好的命令行接口。
通过在程序中定义好我们需要的参数,然后 argparse 将会从 sys.argv 解析出这些参数。
argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
'''
'''
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
'''
def args_parser():
parser = argparse.ArgumentParser() # 创建ArgumentParser()对象
# 调用add_argument()方法添加参数(定义如何解析命令行参数)
# federated arguments
parser.add_argument('--epochs', type=int, default=10, help="rounds of training")
parser.add_argument('--num_users', type=int, default=100, help="number of users: K")
parser.add_argument('--frac', type=float, default=0.1, help="the fraction of clients: C")
parser.add_argument('--local_ep', type=int, default=5, help="the number of local epochs: E")
parser.add_argument('--local_bs', type=int, default=10, help="local batch size: B")
parser.add_argument('--bs', type=int, default=128, help="test batch size")
parser.add_argument('--lr', type=float, default=0.01, help="learning rate")
parser.add_argument('--momentum', type=float, default=0.5, help="SGD momentum (default: 0.5)")
parser.add_argument('--split', type=str, default='user', help="train-test split type, user or sample")
# model arguments
parser.add_argument('--model', type=str, default='mlp', help='model name')
parser.add_argument('--kernel_num', type=int, default=9, help='number of each kind of kernel')
parser.add_argument('--kernel_sizes', type=str, default='3,4,5',
help='comma-separated kernel size to use for convolution') # 卷积核大小可选3、4、5
parser.add_argument('--norm', type=str, default='batch_norm', help="batch_norm, layer_norm, or None")
parser.add_argument('--num_filters', type=int, default=32, help="number of filters for conv nets")
parser.add_argument('--max_pool', type=str, default='True',
help="Whether use max pooling rather than strided convolutions") # 默认max_pooling
# other arguments
parser.add_argument('--dataset', type=str, default='mnist', help="name of dataset")
parser.add_argument('--iid', action='store_true', help='whether i.i.d or not') # 若输入--iid即选择iid数据,不填则默认是non-iid数据
'''
parser.add_argument('-c', action='store_true', default=false)
#python test.py -c => c是true(因为action)
#python test.py => c是false(default)
'''
parser.add_argument('--num_classes', type=int, default=10, help="number of classes")
parser.add_argument('--num_channels', type=int, default=3, help="number of channels of images")
parser.add_argument('--gpu', type=int, default=0, help="GPU ID, -1 for CPU") # 输入-1即默认选用CPU训练,没显卡的我眼泪掉下来
parser.add_argument('--stopping_rounds', type=int, default=10, help='rounds of early stopping')
parser.add_argument('--verbose', action='store_true', help='verbose print')
parser.add_argument('--seed', type=int, default=1, help='random seed (default: 1)')
parser.add_argument('--all_clients', action='store_true', help='aggregation over all clients')
args = parser.parse_args() # 使用parse_args()解析添加的函数
return args
3.Nets.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
# 模型结构设计
import torch
from torch import nn
import torch.nn.functional as F
# MLP模型
class MLP(nn.Module):
def __init__(self, dim_in, dim_hidden, dim_out): # 输入维度 隐层维度 输出维度
super(MLP, self).__init__()
self.layer_input = nn.Linear(dim_in, dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.layer_hidden = nn.Linear(dim_hidden, dim_out)
def forward(self, x):
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
x = self.layer_input(x)
x = self.dropout(x)
x = self.relu(x)
x = self.layer_hidden(x)
return x
# 用CNN训练mnist
class CNNMnist(nn.Module):
def __init__(self, args):
super(CNNMnist, self).__init__()
self.conv1 = nn.Conv2d(args.num_channels, 10, kernel_size=5) # num_channels,num_classes在options.py中定义
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, args.num_classes)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, x.shape[1]*x.shape[2]*x.shape[3]) # 进行reshape
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return x
class CNNCifar(nn.Module):
def __init__(self, args):
super(CNNCifar, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, args.num_classes) # num_classes在options.py中定义
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
4.Fed.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import copy
import torch
from torch import nn
def FedAvg(w): # main中将w_locals赋给w,即worker计算出的权值
w_avg = copy.deepcopy(w[0])
for k in w_avg.keys(): # 对于每个参与的设备:
for i in range(1, len(w)): # 对本地更新进行聚合
w_avg[k] += w[i][k]
w_avg[k] = torch.div(w_avg[k], len(w))
return w_avg
# import copy
#
# origin = [1, 2, [3, 4]]
# cop1 = copy.copy(origin)
# cop2 = copy.deepcopy(origin)
# cop3=origin
#
# print(origin)
# print(cop1)
# print(cop2)
# print(cop3)
#
# origin[2][0] = "hey!" #改变
# print("##################")
#
# print(origin)
# print(cop1)
# print(cop2) # 深度拷贝不变
# print(cop3)
#
# [1, 2, [3, 4]]
# [1, 2, [3, 4]]
# [1, 2, [3, 4]]
# [1, 2, [3, 4]]
# ##################
# [1, 2, ['hey!', 4]]
# [1, 2, ['hey!', 4]]
# [1, 2, [3, 4]]
# [1, 2, ['hey!', 4]]
5.sampling.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import numpy as np
from torchvision import datasets, transforms
def mnist_iid(dataset, num_users):
"""
Sample I.I.D. client data from MNIST dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset)/num_users) # 每个用户数据量
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users): # 对于每个用户
# set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False)) # 从all_idxs中采样,生成 单用户数据量的无重复的 一个字典,作为dict_users的第(i+1)个元素
all_idxs = list(set(all_idxs) - dict_users[i]) # 取差集,删去已经被分配好的数据,直至每个用户都被分配了等量的iid数据
return dict_users
def mnist_noniid(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset
:param dataset:
:param num_users:
:return:
"""
num_shards, num_imgs = 200, 300
idx_shard = [i for i in range(num_shards)]
dict_users = {i: np.array([], dtype='int64') for i in range(num_users)} # 初始化字典dict_users
idxs = np.arange(num_shards*num_imgs)
labels = dataset.train_labels.numpy()
# sort labels
idxs_labels = np.vstack((idxs, labels))
# 沿着第一个轴堆叠数组。
# 语法格式:numpy.vstack(tup)
# 参数:
# tup:ndarrays数组序列,如果是一维数组进行堆叠,则数组长度必须相同;除此之外,其它数组堆叠时,除数组第一个轴的长度可以不同,其它轴长度必须一样。
# y = x.argsort() 将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y
idxs_labels = idxs_labels[:,idxs_labels[1,:].argsort()]
idxs = idxs_labels[0,:]
# divide and assign
for i in range(num_users):
rand_set = set(np.random.choice(idx_shard, 2, replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
# concatenate进行矩阵拼接
dict_users[i] = np.concatenate((dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0)
return dict_users
def cifar_iid(dataset, num_users):
"""
Sample I.I.D. client data from CIFAR10 dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset)/num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_users
if __name__ == '__main__':
dataset_train = datasets.MNIST('../data/mnist/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
num = 100
d = mnist_noniid(dataset_train, num)
6.test.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @python: 3.6
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
def test_img(net_g, datatest, args):
net_g.eval()
# testing
test_loss = 0
correct = 0
data_loader = DataLoader(datatest, batch_size=args.bs) # bs:test batch_size
l = len(data_loader)
for idx, (data, target) in enumerate(data_loader):
if args.gpu != -1:
data, target = data.cuda(), target.cuda()
log_probs = net_g(data)
# sum up batch loss
test_loss += F.cross_entropy(log_probs, target, reduction='sum').item() # 使用交叉熵损失
# get the index of the max log-probability
y_pred = log_probs.data.max(1, keepdim=True)[1]
correct += y_pred.eq(target.data.view_as(y_pred)).long().cpu().sum()
test_loss /= len(data_loader.dataset)
accuracy = 100.00 * correct / len(data_loader.dataset)
if args.verbose:
print('\nTest set: Average loss: {:.4f} \nAccuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(data_loader.dataset), accuracy))
return accuracy, test_loss
7.Update.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Python version: 3.6
import torch
from torch import nn, autograd
from torch.utils.data import DataLoader, Dataset
import numpy as np
import random
from sklearn import metrics
# 数据分组
class DatasetSplit(Dataset):
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = list(idxs)
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
return image, label
class LocalUpdate(object):
def __init__(self, args, dataset=None, idxs=None):
self.args = args
self.loss_func = nn.CrossEntropyLoss()
self.selected_clients = []
self.ldr_train = DataLoader(DatasetSplit(dataset, idxs), batch_size=self.args.local_bs, shuffle=True)
def train(self, net):
net.train()
# train and update
optimizer = torch.optim.SGD(net.parameters(), lr=self.args.lr, momentum=self.args.momentum)
epoch_loss = []
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.ldr_train):
images, labels = images.to(self.args.device), labels.to(self.args.device)
net.zero_grad()
log_probs = net(images)
loss = self.loss_func(log_probs, labels)
loss.backward()
optimizer.step()
if self.args.verbose and batch_idx % 10 == 0:
print('Update Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
iter, batch_idx * len(images), len(self.ldr_train.dataset),
100. * batch_idx / len(self.ldr_train), loss.item()))
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return net.state_dict(), sum(epoch_loss) / len(epoch_loss)
-
FedAvg算法流程:(图源:Communication-Efficient Learning of Deep Networks from Decentralized Data,这也是FL的开创性文章)

其中在每一个通信轮,随机选取一部分本地用户进行更新(系统中共有K个用户,0<C<1表示所选取用户的比例);被选中的用户执行本地SGD更新后将模型参数返还给服务器,服务器随后对其进行聚合更新(每个用户的聚合权重为各自本地数据所占总数据的比例) -
下面是运行代码得到的一些可视化结果:
-
epoch = 50

- epoch = 10


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)