
pandas教程03---DataFrame的创建及索引
本文介绍了DataFrame的创建、行索引和列索引、多级索引、添加新列等操作。
文章目录
欢迎关注公众号【Python开发实战】,免费领取Python学习电子书!
工具-pandas
pandas库提供了高性能、易于使用的数据结构和数据分析工具。其主要数据结构是DataFrame,可以将DataFrame看做内存中的二维表格,如带有列名和行标签的电子表格。许多在Excel中可用的功能都可以通过编程实现,例如创建数据透视表、基于其他列计算新列的值、绘制图形等。还可以按照列的值对行进行分组,或者像SQL中那样连接表格。pandas也擅长处理时间序列。
但是介绍pandas之前,需要有numpy的基础,如果还不熟悉numpy,可以查看numpy快速入门教程。
导入pandas
import pandas as pd
Dataframe对象
一个DataFrame对象表示一个电子表格,带有单元格值、列名和行索引标签。可以定义表达式基于其他列计算列的值、创建数据透视表、按行分组、绘制图形等。可以将DataFrame视为Series的字典。
创建Dataframe
- 可以通过传递一个Series对象的字典来创建DataFrame。
people_dict = {
'weight': pd.Series([68, 83, 112], index=['alice', 'bob', 'charles']),
'birthyear': pd.Series([1984, 1985, 1992], index=['bob', 'alice', 'charles'], name='year'),
'children': pd.Series([0, 3], index=['charles', 'bob']),
'hobby': pd.Series(['Biking', 'Dancing'], index=['alice', 'bob']),
}
people = pd.DataFrame(people_dict)
people
输出:

需要注意:
- Series会根据索引自动对齐。
- 缺失值表示为NaN。
- Series的名字会被忽略(即名称year被删除)。
- DataFrame在jupyter notebook中显示的形式很好。
可以根据列名访问DataFrame,会返回Series对象。
people['birthyear']
输出:
alice 1985
bob 1984
charles 1992
Name: birthyear, dtype: int64
也可以一次性访问多列, 会返回一个DataFrame。
people[['birthyear', 'hobby']]
输出:

如果在创建DataFrame时,参数columns和index分别被传入一个列表,则会保证这些列和这些行将按照列表中的顺序存在,不会存在其他的列和行。
d2 = pd.DataFrame(people_dict, columns=['birthyear', 'weight', 'height'], index=['bob', 'alice', 'eugene'])
d2
输出:

- 另一个创建DataFrame的实用方法是传入由所有值组成的ndarray或嵌套列表,并指定列名和行索引标签。
import numpy as np
values = [
[1985, np.nan, 'Biking', 68],
[1984, 3, 'Dancing', 83],
[1992, 0, np.nan, 112],
]
d3 = pd.DataFrame(values, columns=['birthyear', 'children', 'hobby', 'weight'], index=['alice', 'bob', 'charles'])
d3
输出:

对于缺失值,可以使用np.nan,也可以使用numpy的屏蔽数组。
masked_array = np.ma.asarray(values, dtype=np.object)
masked_array[(0, 2), (1, 2)] = np.ma.masked
d4 = pd.DataFrame(masked_array, columns=['birthyear', 'children', 'hobby', 'weight'], index=['alice', 'bob', 'charles'])
d4
输出:

- 还可以传递一个DataFrame对象,而不是传递一个ndarray。
d5 = pd.DataFrame(d4, columns=['hobby', 'children'], index=['alice', 'bob'])
d5
输出:

- 还可以使用字典来创建DataFrame。
people = pd.DataFrame({
'birthyear':{'alice': 1985, 'bob': 1984, 'charles': 1992},
'hobby':{'alice': 'Biking', 'bob': 'Dancing'},
'weight':{'alice': 68, 'bob': 83, 'charles': 112},
'children':{'bob': 1984, 'charles': 0}
})
people
输出:

多级索引
如果所有的列都是大小相同的元组,则会被理解陈给多级列索引。行索引标签也是如此。
d6 = pd.DataFrame(
{
('public', 'birthyear'): {('Paris', 'alice'):1985, ('Paris', 'bob'):1984, ('London', 'charles'): 1992},
('public', 'hobby'): {('Paris', 'alice'):'Biking', ('Paris', 'bob'):'Dancing'},
('private', 'weight'): {('Paris', 'alice'):68, ('Paris', 'bob'):83, ('London', 'charles'): 112},
('private', 'children'): {('Paris', 'alice'):np.nan, ('Paris', 'bob'):3, ('London', 'charles'): 0},
}
)
d6
输出:
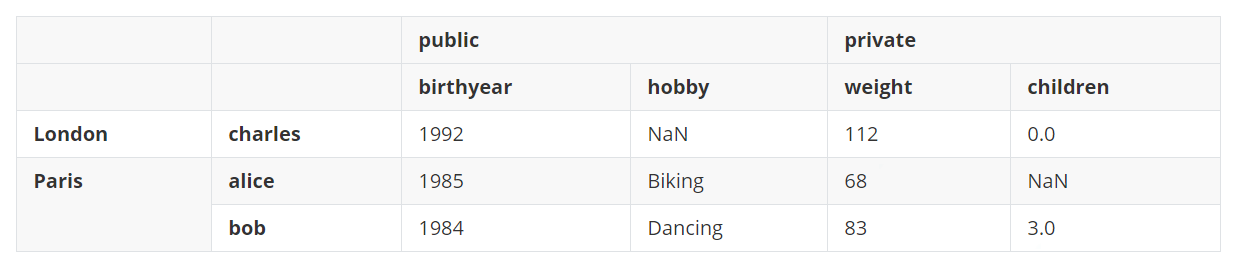
可以非常简单地获取到包含所有public列的DataFrame。
d6['public']
输出:

d6['public', 'hobby'] # 相当于 d6['public']['hobby']
输出:
London charles NaN
Paris alice Biking
bob Dancing
Name: (public, hobby), dtype: object
多级索引降级
d6.columns # 列索引
输出:
MultiIndex(levels=[['private', 'public'], ['birthyear', 'children', 'hobby', 'weight']],
labels=[[1, 1, 0, 0], [0, 2, 3, 1]])
d6.index # 行索引
输出:
MultiIndex(levels=[['London', 'Paris'], ['alice', 'bob', 'charles']],
labels=[[0, 1, 1], [2, 0, 1]])
可以看到d6有两级列索引和行索引,现在可以通过调用droplevel()删除一级列索引(行索引也是如此)。
d6.columns = d6.columns.droplevel(level=0)
d6
输出:

堆叠和拆分多级索引
调用stack()方法会将最低级的列索引放到最低级的行索引之后。
d8 = d7.stack()
d8
输出:
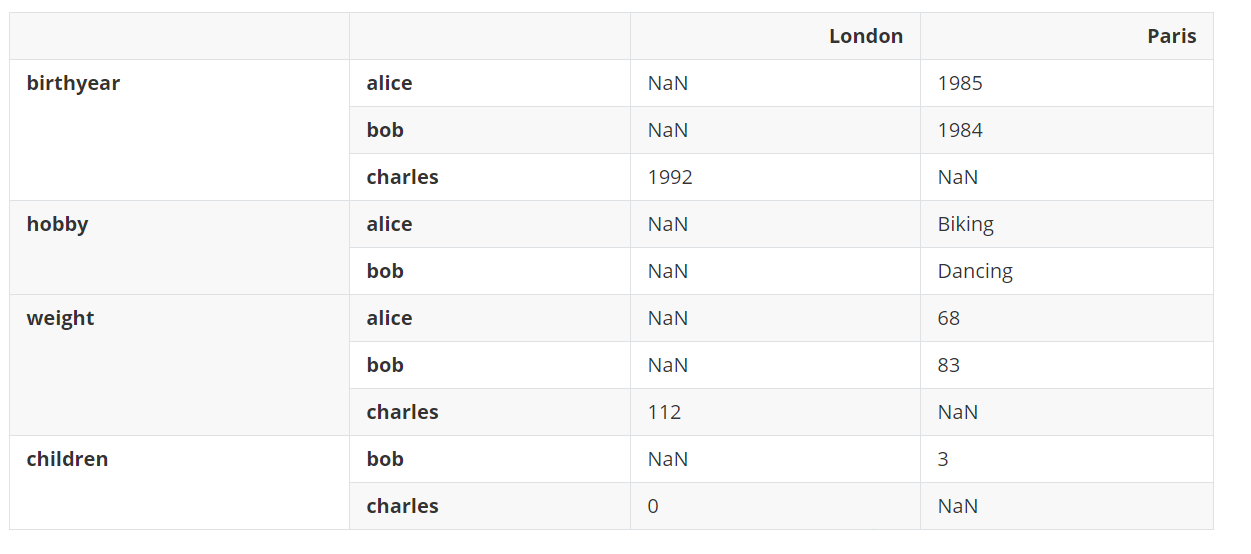
上面的结果中出现了许多NaN值,这是有道理的,因为许多新的组合以前不存在,比如伦敦没有bob。
现在调用unstack()将会实现的相反的效果,也会再次创建许多NaN值。
d9 = d8.unstack()
d9
输出:
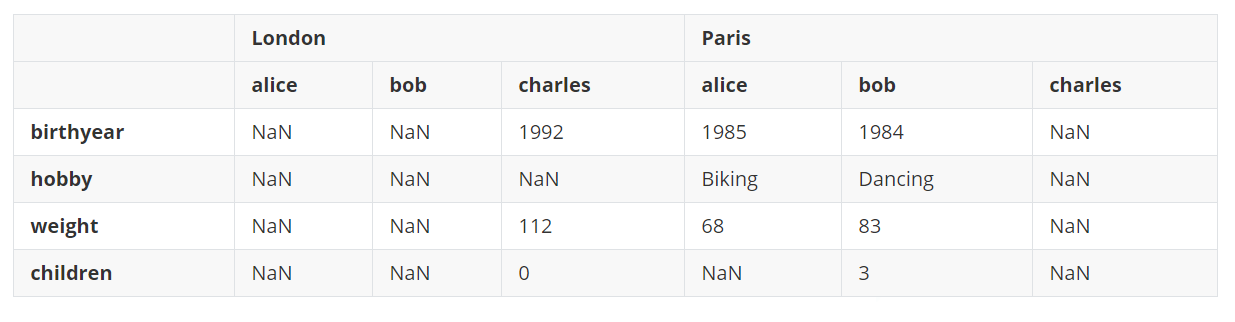
如果在上面的结果上再次调用unstack(),将会得到一个Series对象。
d10 = d9.unstack()
d10
输出:
London alice birthyear NaN
hobby NaN
weight NaN
children NaN
bob birthyear NaN
hobby NaN
weight NaN
children NaN
charles birthyear 1992
hobby NaN
weight 112
children 0
Paris alice birthyear 1985
hobby Biking
weight 68
children NaN
bob birthyear 1984
hobby Dancing
weight 83
children 3
charles birthyear NaN
hobby NaN
weight NaN
children NaN
dtype: object
stack()和unstack()方法可以通过设置level参数来选择想要堆叠和拆分的索引级别,设置可以同时堆叠和拆分多个级别。
d11 = d10.unstack(level=(0, 1))
d11
输出:
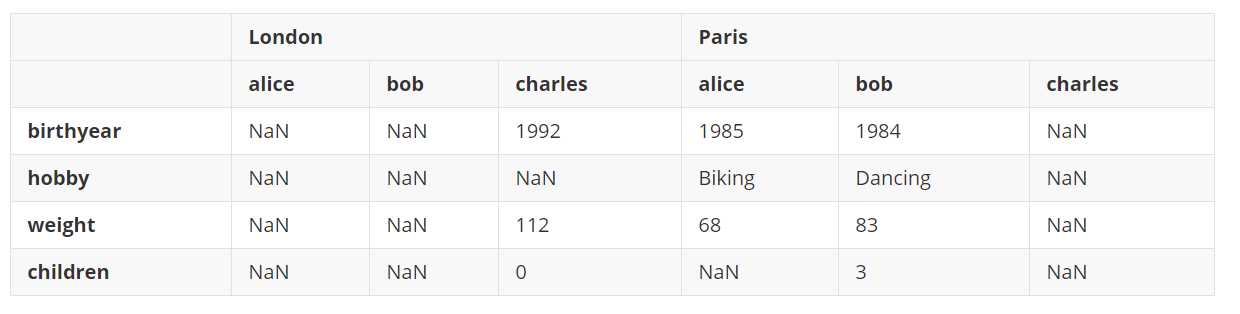
大多数方法返回修改过的副本
从stack()和unstack()的结果已经发现,这些方法不会修改应用的对象,而使处理应用对象的副本并返回这个副本。在pandas中,大多数方法都是这样的。
访问行
people
输出:

loc属性是按行索引访问行,不是按列访问。它的结果是一个Series对象,DataFrame的列名会被映射为Series的行标签。
people.loc['charles']
输出:
birthyear 1992
hobby NaN
weight 112
children 0
Name: charles, dtype: object
iloc属性是按整数位置来访问行。
people.iloc[2]
输出:
birthyear 1992
hobby NaN
weight 112
children 0
Name: charles, dtype: object
对按行进行切片,会返回一个DataFrame对象。
people.iloc[1:3]
输出:

还可以传递一个布尔数组来获得匹配的行,类似于ndarray的布尔索引。
people[np.array([True, False, True])]
输出:

这与布尔表达式(条件运算)结合使用时非常有用。
people[people['birthyear'] < 1990]
输出:

添加和移除列
通常,可以将DataFrame看做是由Series组成的字典,所以下面的方法可以正常运行。
people['age'] = 2022- people['birthyear'] # 添加一个新列age
people['over 30'] = people['age'] > 30 # 添加一个新列 over 30
birthyears = people.pop('birthyear') # 删除birthday列
del people['children'] # 删除children列
people
输出:

birthyears
输出:
alice 1985
bob 1984
charles 1992
Name: birthyear, dtype: int64
在添加一个新列时,其行数必须和DataFrame相同。缺少的行将会用NaN填充,多余的行会被忽略。
people['pets'] = pd.Series({'bob': 0, 'charles': 5, 'eugene': 1}) # alice 缺失 eugene忽略
people
输出:

在添加新列时,默认会添加在末尾 (右端),可以使用insert()方法在其他任何位置插入新列。
people.insert(1, 'height', [172, 181, 185])
people
输出:

布置新列
还可以通过调用assign()方法来创建新列。但是需要注意的是,这个方法会返回一个新的DataFrame对象,原来的DataFrame不会被修改。
people.assign(
body_mass_index=people['weight'] / (people['height'] / 100) ** 2,
has_pets=people['pets'] > 0
)
输出:

需要注意的是,无法访问在同一布置中创建的列。
try:
people.assign(
body_mass_index=people['weight'] / (people['height'] / 100) ** 2,
overweight=people['body_mass_index'] > 25
)
except KeyError as e:
print('KeyError:', e)
输出:
KeyError: 'body_mass_index'
解决上面问题的方案是将上面的布置任务拆分为两个连续的任务。
d12 = people.assign(body_mass_index=people['weight'] / (people['height'] / 100) ** 2)
d12.assign(overweight=d12['body_mass_index'] > 25)
输出:

上面的解决方案中创建了一个临时变量d12,这不是很方便。你可以想链式调用assign,但是不会起作用,因为第一个assign实际上没有修改people对象。
try:
(people
.assign(body_mass_index=people['weight'] / (people['height'] / 100) ** 2)
.assign(overweight=people['body_mass_index'] > 25)
)
except KeyError as e:
print('KeyError:', e)
输出:
KeyError: 'body_mass_index'
简单的解决方案是将一个函数传递给assign()方法,通常是lambda函数,该函数将会把DataFrame作为参数调用。
(people
.assign(body_mass_index=lambda df :df['weight'] / (df['height'] / 100) ** 2)
.assign(overweight=lambda df:df['body_mass_index'] > 25)
)
输出:


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)