【sklearn】详解classification_report的分类报告计算
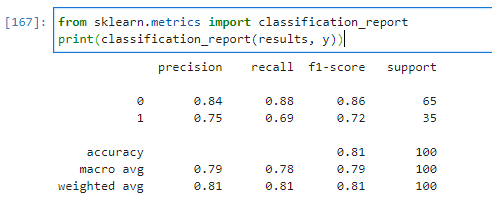
简介说来惭愧,好久不写博客,让我动笔的竟然是sklearn一个小小的api功能,以前评价模型用的都是总体的准确率,第一次用sklearn提供的分类报告功能竟然搞不懂是怎么计算的,怎么还分类别。就像下面这样:嗯,这都啥呀?老实说第一次看我只看懂了准确率即accuracy是怎么计算的。。。计算首先results是我们模型预测出的结果,y是真实标签,它们分别如下:yarray([0, 0, 0, 0,
简介
说来惭愧,好久不写博客,让我动笔的竟然是sklearn一个小小的api功能,以前评价模型用的都是总体的准确率,第一次用sklearn提供的分类报告功能竟然搞不懂是怎么计算的,怎么还分类别。就像下面这样:
嗯,这都啥呀?老实说第一次看我只看懂了准确率即accuracy是怎么计算的。。。
计算
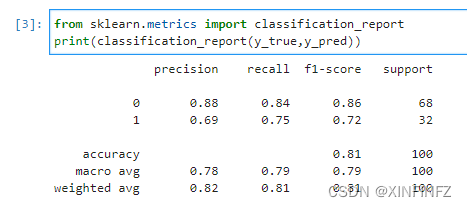
首先y_true是真实结果,y_pred是预测出的标签,它们分别如下:
y_true
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
y_pred
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,
0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1])
闲着没事干的可以自己数数,这边统计出来的结果是:
实际情况中,前68个样本为0类别,后32个样本为1类别。
预测中,前68个样本中有11个被预测为了1类别,后32个样本中有8个被预测为了0类别。
那么我们先说分类报告中最右边的support为什么是68和32。
support意思为支持,也就是说真实结果中有多少是该类别。那么有68个为0类别,32个为1类别。
在左边的召回率里,分母为support个数。
那么0类别里召回率即recall的计算为:
(68-11)/68=0.8382,保留两位小数为0.84。
同理1类别中:
(32-8)/32=0.75。
意思为 实际为x的类别中,有多少预测为x。
而精准率即precision的区别在于分母不同:
此时的分母为预测样本分类。
0类别:
57/65=0.8769,保留两位小数为0.88。
1类别:
24/35=0.6857,保留两位小数为0.69。
意思为 预测为x的样本中,有多少被正确预测为x。
解决了这两个,剩下的就很好懂了。
F1分数=2 * precision * recall /(precision+recall)。
accuracy=(100-11-8)/100。
注:准确率(accuracy)即全部样本里被分类正确的比例。
macro avg = 上面类别各分数的直接平均
注:如精准率的macro avg=(0.88+0.69)/2约等于0.78。
weighted avg=上面类别各分数的加权(权值为support)平均
注:如精准率的weighted avg=(0.88x68+0.69*32)/100约等于0.82。
总结:纸上得来终觉浅,很多理论知识学了就忘,其实还是缺乏实践。
实践是发现问题的最好途径。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)