【Jmeter】Jmeter响应消息中文显示乱码
Jmeter响应消息中文显示乱码
·
1、现象:
使用Jmeter时,返回的中文字符显示一堆花码。

2、产生原因:
Jmeter的结果处理编码与被测试对象的编码不一致。Jmeter的sampler请求结果的默认编码方式为:ISO-8859-1(不支持中文),Jmeter的sampler请求结果的默认编码方式为:ISO-8859-1(不支持中文)。
对于返回中文乱码又分两种:
返回UTF-8中文字符
返回unicode编码信息
3、返回UTF-8乱码的情况解决办法:
3.1 方法 1:
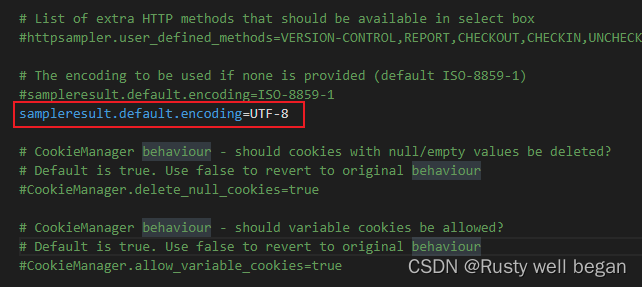
1、打开 jmeter.properties 配置文件,找到 sampleresult.default.encoding,将原来
#sampleresult.default.encoding=ISO-8859-1
修改为
sampleresult.default.encoding=UTF-8
(注意删除前面的#号时修改生效)
重新启动JMeter再次运行Jmeter可以显示中文。
但这样修改以后如果只测试一个项目或者项目返回的都是UTF-8字符则没问题,如果之后检测的系统时其他字符集又会出现这个问题,如:gb2312字符集;
3.2、方法2:
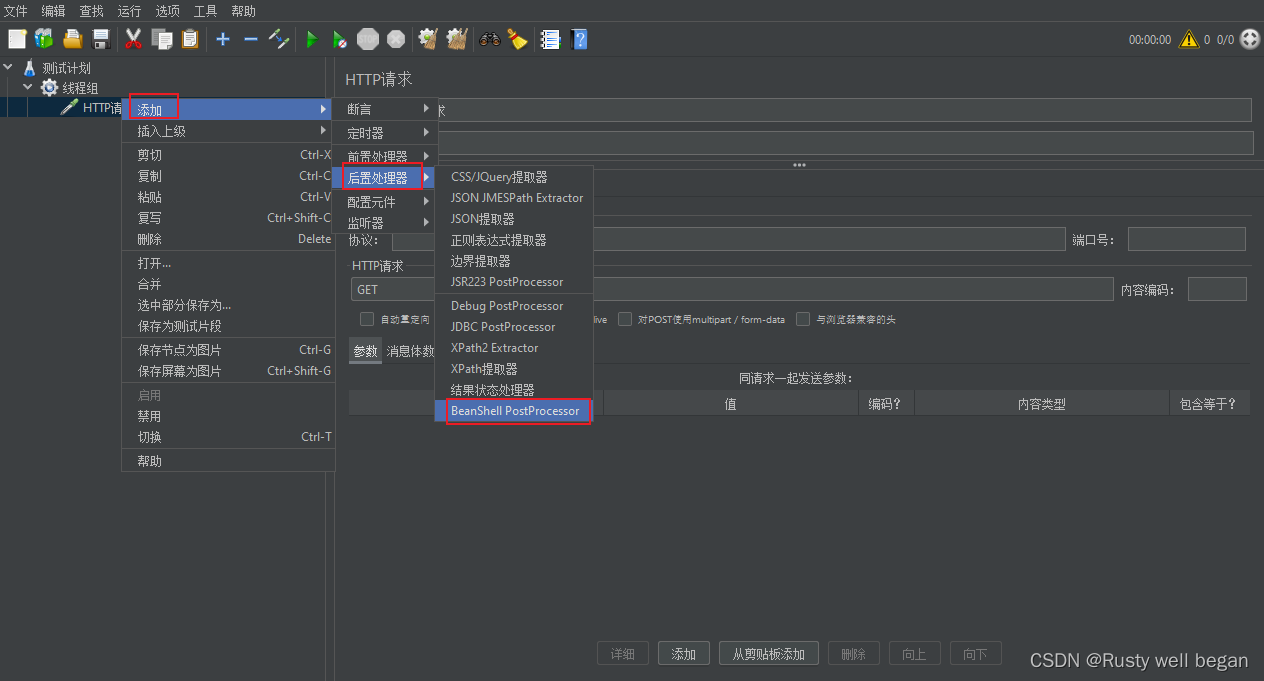
使用后置控制器”BeanShell PostProcessor”来动态修改结果处理编码,使之与被测系统字符集保持一致;
添加BeanShell PostProcessor
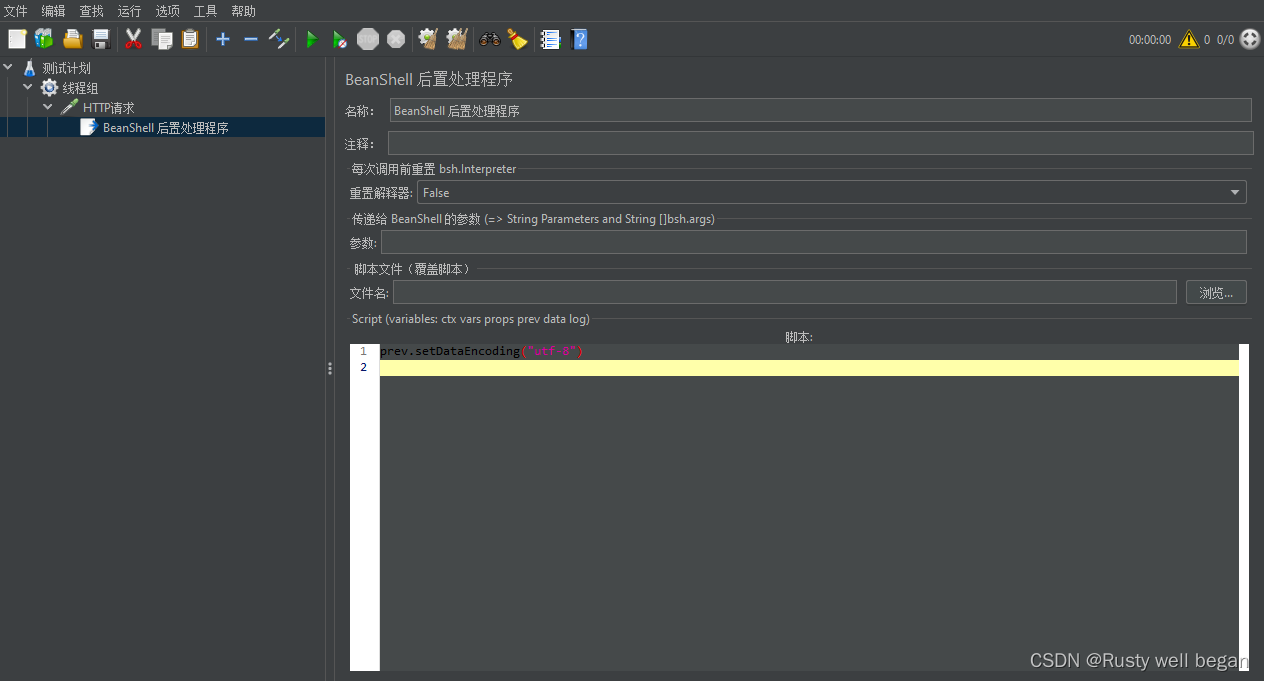
加入如下代码:
prev.setDataEncoding("utf-8")
4、 返回unicode编码的情况
返回 \uxxxx 就是unicode编码内容,这样在 BeanShell PostProcessor 中加入 prev.setDataEncoding(“UTF-8”); 并无任何卵用,因为本身显示的就是英文字符所以无用
1、添加BeanShell PostProcessor
2、加入如下代码
String s=new String(prev.getResponseData(),"UTF-8");
char aChar;
int len= s.length();
StringBuffer outBuffer=new StringBuffer(len);
for(int x =0; x <len;){
aChar= s.charAt(x++);
if(aChar=='\\'){
aChar= s.charAt(x++);
if(aChar=='u'){
int value =0;
for(int i=0;i<4;i++){
aChar= s.charAt(x++);
switch(aChar){
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
value=(value <<4)+aChar-'0';
break;
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
value=(value <<4)+10+aChar-'a';
break;
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
value=(value <<4)+10+aChar-'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");}}
outBuffer.append((char) value);}else{
if(aChar=='t')
aChar='\t';
else if(aChar=='r')
aChar='\r';
else if(aChar=='n')
aChar='\n';
else if(aChar=='f')
aChar='\f';
outBuffer.append(aChar);}}else
outBuffer.append(aChar);}
prev.setResponseData(outBuffer.toString());

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)