【Pandas库】(3) DataFrame的创建方法及基本操作
各位同学好,今天给大家介绍一下Pandas库中DataFrame类型数据的创建方法和基本操作。文章内容如下:(1)使用字典类创建。字典类有:①数组、列表、元组构成的字典;②Series构造的字典;③字典构造的字典。(2)使用列表类创建。列表类有:①二维数组;②字典构造的列表;③Series构成的列表(3)基本操作。①查看索引;②指定索引;③转置操作;④通过索引获取数据;⑤追加一列;⑥删除列首先,我
各位同学好,今天给大家介绍一下Pandas库中DataFrame类型数据的创建方法和基本操作。
文章内容如下:
(1)使用字典类创建。
字典类有:①数组、列表、元组构成的字典;②Series构造的字典;③字典构造的字典。
(2)使用列表类创建。
列表类有:①二维数组;②字典构造的列表;③Series构成的列表
(3)基本操作。
①查看索引;②指定索引;③转置操作;④通过索引获取数据;⑤追加一列;⑥删除列
首先,我简单介绍一下DataFrame:
① DataFrame数据结构可以理解为python版的excel表格。
② 是表格型数据结构,它包含一组有序的列,每列可以是不同类型的值。
③ DataFrame既有行索引,又有列索引。每列数据可以是不同类型。
④ 可以看作是由Series组成的字典,共用一个索引,数据以二维结构存放。
1. 创建方法--字典类
1.1 使用数组、列表或元组构成的字典构造DataFrame
创建方法: pd.DataFrame(字典名)
创建后,列索引对应的是字典中的标签名,行索引对应默认值。
import pandas as pd
# 数组、列表或元组构成的字典构造dataframe
a1 = {"a":[1,2,3,4],"b":(5,6,7,8),"c":np.arange(9,13)} #建立字典
frame1 = pd.DataFrame(a1) # 构造dataframe
1.2 使用Series构造的字典构造DataFrame
创建方法同 pd.DataFrame(字典名),展示如下。
字典中标签'a'和'b'对应的值为Series类型。np.arange(3)是利用numpy库创建一个数组[0,1,2];通过pd.Series(数组)将其转化为Series类型的[0,1,2]。
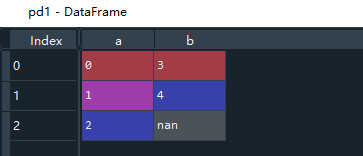
# series构造的字典构造dataframe
pd1 = pd.DataFrame({"a":pd.Series(np.arange(3)),"b":pd.Series(np.arange(3,5))})
1.3 使用字典构造的字典(字典嵌套)来构造DataFrame
创建方法同 pd.DataFrame(字典名),展示如下。
外层字典的标签名为'a','b','c',且标签'a'对应的值是一个字典类型,标签名为'apple','banana',值分别为3.6,5.7。因此a5可看成是由两层字典构成,其本身是一个字典类型,标签对应的值也是字典类型。
# 通过字典构造的字典(字典嵌套)来构造dataframe
a5 = {"a":{"apple":3.6,"banana":5.7},"b":{"apple":2.1,"banana":8.2},"c":{"apple":5.2}}
pd2 = pd.DataFrame(a5)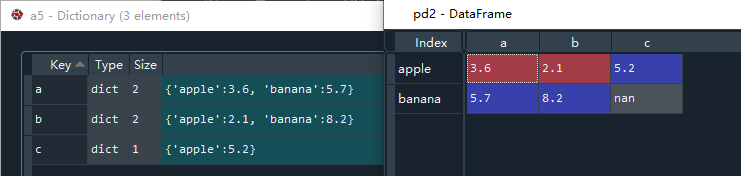
2. 创建方法--列表类
2.1 使用二维数组构造DataFrame
创建方法: pd.DataFrame(列表)
arr1是利用numpy库产生的由1到12的一维数组,通过reshape(行数,列数)改变数组形状,要求改变后数组的元素个数与原始数组的元素个数相同。
import numpy as np
# 二维数组构造dataframe
arr1 = np.arange(1,13).reshape(4,3)
frame4 = pd.DataFrame(arr1)
# 指定行列索引,必须与原来的列表,行数和列数相同
2.2 使用字典构造的列表创建DataFrame
创建方法同上:pd.DataFrame(列表)
列表l1是由三个字典构成。创建后,字典内部的key变成列索引。一定要和由字典嵌套创建的DataFrame区分开来。
# 字典构造的列表构造dataframe
l1 = [{"apple":3.6,"banana":5.0},{"apple":2,"banana":8},{"apple":1.8}]
pd3 = pd.DataFrame(l1)
2.3 使用Series构成的列表构造DataFrame
创建方法同上:pd.DataFrame(列表)
列表l2由两个Series类型数据构成。np.random.rand(n)表示随机生成n个0到1之间的数,构成数组,再通过pd.Series()转换成Series类型数据。
# series构成的列表构造dataframe
l2 = [pd.Series(np.random.rand(3)),pd.Series(np.random.rand(2))]
pd4 = pd.DataFrame(l2)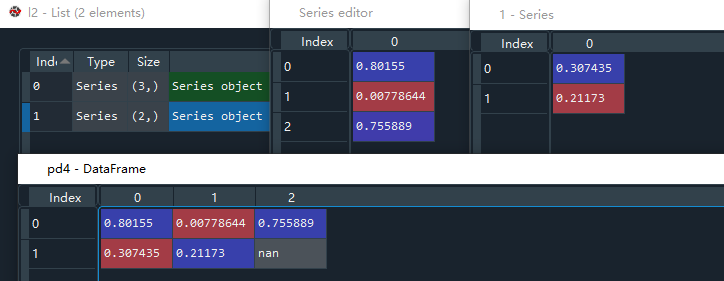
3. 基本操作
3.1 查看索引
查看行索引: 变量名.index
查看列索引: 变量名.columns
查看值: 变量名.values
a2 = frame1.index # 查看行索引
a3 = frame1.columns # 查看列索引
a4 = frame1.values # 查看value值
3.2 创建时指定索引排序
指定行索引: pd.DataFrame(字典,index=[索引名])
指定列索引: pd.DataFrame(字典,index=[索引名],columns=[索引名])
此处指定的列索引名必须是原字典中存在的索引,如果不存在,则该列索引名对应的值是nan
a1 = {"a":[1,2,3,4],"b":(5,6,7,8),"c":np.arange(9,13)}
frame1 = pd.DataFrame(a1)
# 指定index行索引
frame2 = pd.DataFrame(a1,index=["Alex","Block","Cici","Dalin"])
# 指定columns列索引
frame3 = pd.DataFrame(a1,index=["Alex","Block","Cici","Dalin"],columns=["a","b","c","d"])

3.3 转置操作
方法:变量名.T # 行和列互换位置
pd5 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","c","b"],columns=["A","B","C"])
# 转置操作,行与列转置,和numpy一样
a6 = pd5.T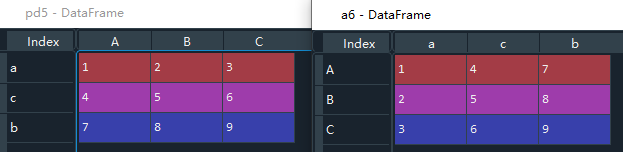
3.4 通过索引获取列数据
方法:变量名[列索引名]
获取索引名所在列的数据,返回结果是Series类型。对行操作涉及高级索引,本文章只介绍基本操作,其余后续再介绍。
pd5 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","c","b"],columns=["A","B","C"])
# 通过索引获取列数据
gt = pd5["A"]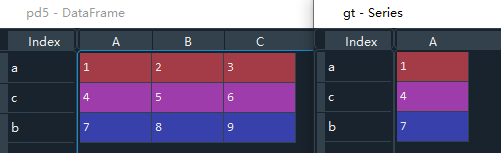
3.5 追加一列
方法: 变量名[列索引名]=自定义值
此处的列索引名为原DataFrame中不存在的索引名,才能在原数据最后一列追加一组值。如果此处的索引名和原数据中的索引名重复,则会更改原数据中的值。
pd5 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","c","b"],columns=["A","B","C"])
# 追加一列
pd5["D"] = 9 #该列所有数都是9
pd5["E"] = [1,2,3] #该列上各行分别是1,2,3
pd5['A'] = [999,888,777] #更改原pd5上'A'列的值
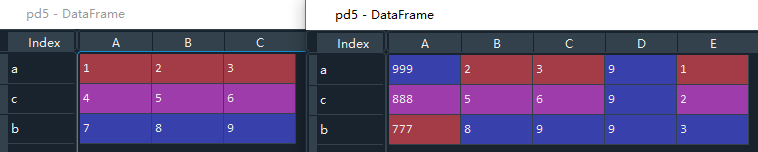
3.6 删除一列
方法: del(变量名[列索引名]) # 删除指定列的所有数据
# 删除列
del(pd5["D"])

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)