ENVI图像处理(4):主分量变换(主成分分析、PCA)
PCAPCA主成分分析基本概念协方差矩阵特征值和特征向量PCA思想优缺点PCA基本步骤PCA-code(python)ENVI的PCA操作PCA主成分分析特征变换的目的在于使地物集中在几个主要的波谱段上,在保证信息容量最大化的前提下压缩参与分类的数据量,以提高分类速度。此处主要介绍主分量变换,也叫做主成分分析(Principal component analysis,PCA)基本概念首先来介绍一些
PCA主成分分析
特征变换的目的在于使地物集中在几个主要的波谱段上,在保证信息容量最大化的前提下压缩参与分类的数据量,以提高分类速度。
此处主要介绍主分量变换,也叫做主成分分析(Principal component analysis,PCA)
基本概念
首先来介绍一些基本概念
协方差矩阵
方差:针对一维集合,反映了其离散程度。是协方差的一种特殊情况
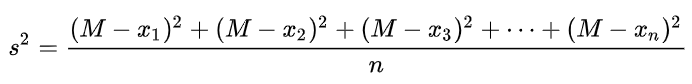
协方差矩阵:针对二维集合时,反映的是两个维度之间的相关性,正相关或负相关或无关
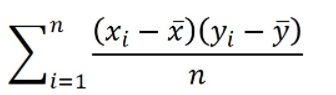
针对三维样本集合时,求出的是各个维度总体的相关性,针对各维度之间的关系,所以二维以上计算协方差,用的就是协方差矩阵
特征值和特征向量
特征值和特征向量:由协方差矩阵的特征值和特征向量
PCA思想
在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴和第一个坐标轴正交且具有最大方差的方向。该特征一直重复,重复次数为原始数据中特征的数目,我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理
方差最大:在此方向上所含的有关原始信息样品间的差异信息是最多的
优缺点
优点:降低数据的复杂性,识别最重要的多个特征
缺点:不一定需要,且可能损失有用信息
PCA基本步骤
PCA算法的基本步骤:
- 去中心化:让所有的点都到坐标原点附件的位置,即每一位特征减去各自的平均值
- 计算协方差矩阵X
- 计算协方差矩阵的特征值和特征向量。特征值表示的是两个特征之间的相关性
- 对特征值进行排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
- 将数据转换到k个特征向量构建的新空间中,即Y=PX。对数据进行旋转使得符合最大方差
PCA-code(python)
来看看相关的python代码(C++用opencv可能好一点,直接用数组太难受了)
def pac(data_mat, N):
# 去中心化
mean_val = mean(data_mat)
mean_removed = data_mat - mean_val
# 计算协方差矩阵X
cov_mat = cov(mean_removed, rowvar=0)
# 计算协方差矩阵的特征值和特征向量
eig_val, eig_vector = linalg.eig(mat(cov_mat))
# 对特征值进行排序
eig_val_ind = argsort(eig_val)
eig_val_ind = eig_val_ind[: -(N+1): -1]
# 对排序后的特征值对应的特征向量
red_eig_val = eig_vector[, :eig_val_ind]
# 新矩阵
low_data_mat = mean_removed * red_eig_val
return low_data_mat
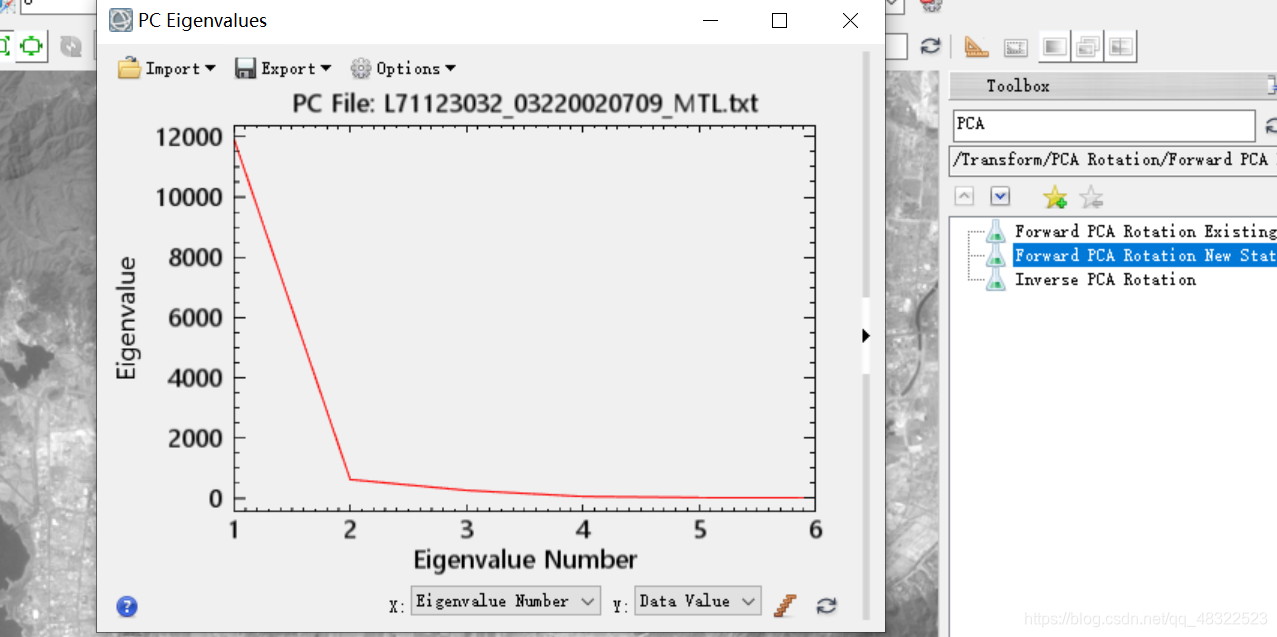
ENVI的PCA操作
toolbox中搜索PCA
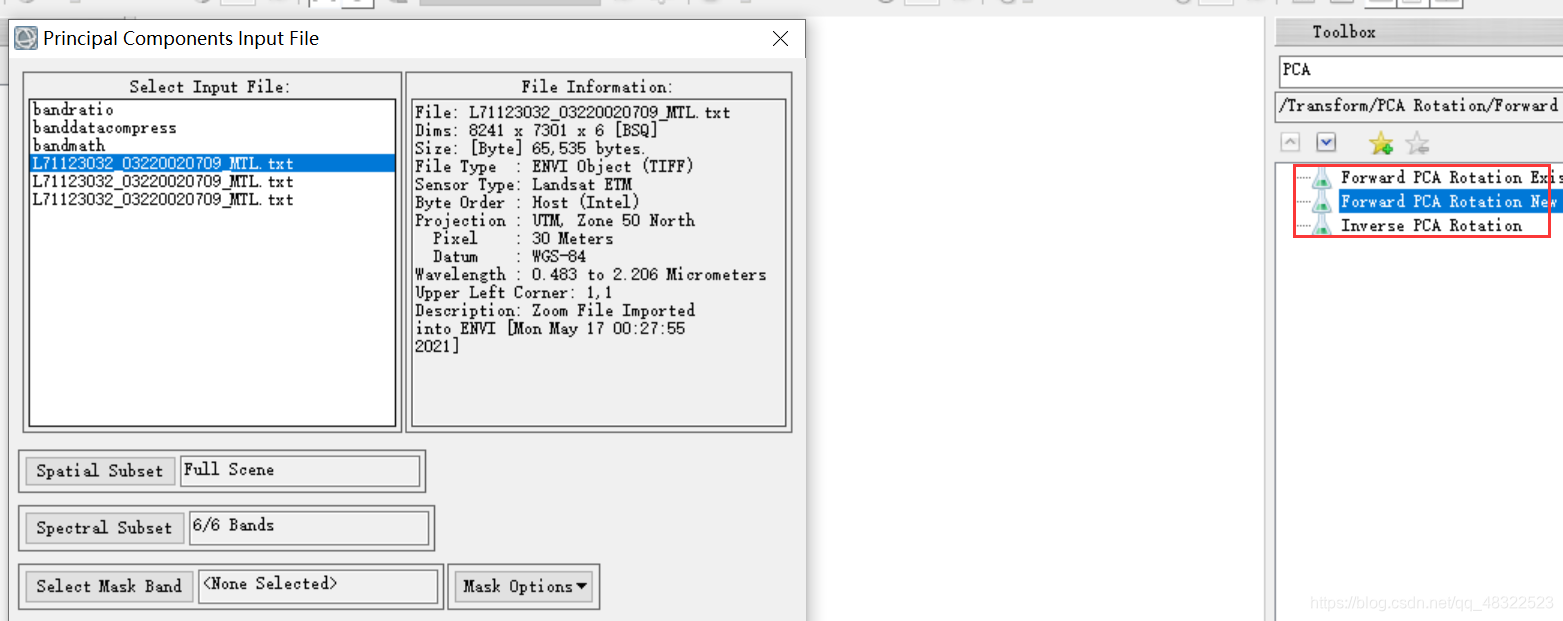
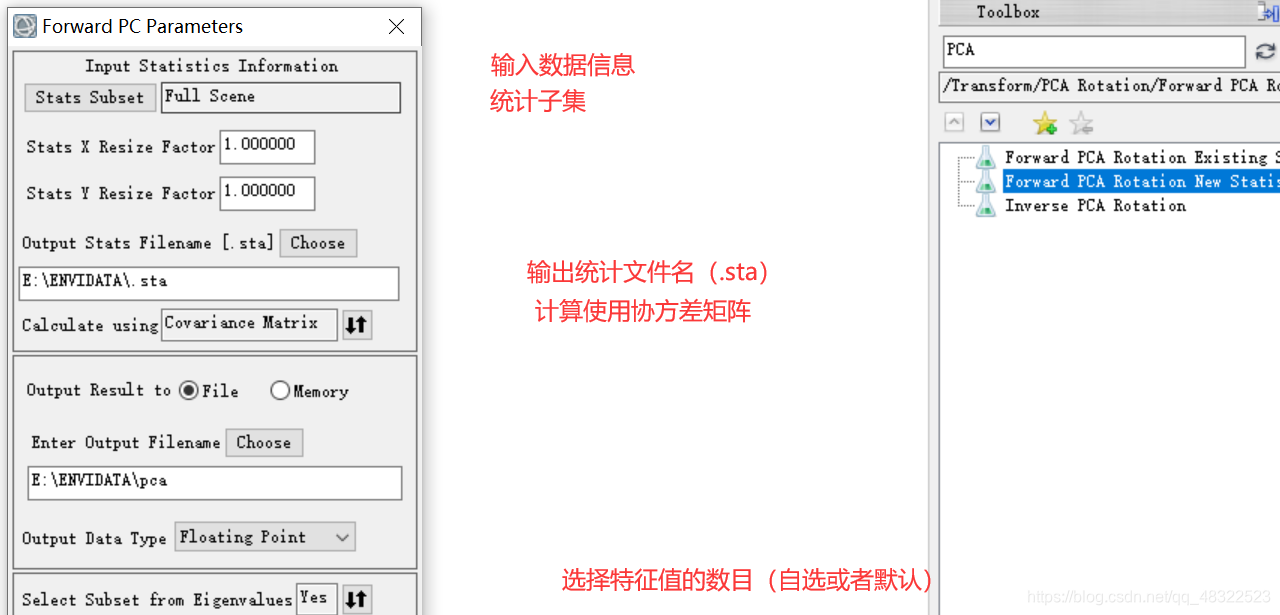
对生成的主分量图像进行比较,大部分信息均已经集中到前面的几个分量图像,后面的分量图像基本上都是噪声。实际应用时,可以舍掉后面的几个分量图像,从而达到减少数据量的目的。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)