机器学习模型训练全流程
机器学习模型训练全流程
·
一.机器学习模型训练全流程

1.获得原始数据集
同时包含X和Y——可以用于监督学习(回归或分类);只包含X——无监督学习。
若Y包含定量值,那么数据集(由X和Y组成)用于回归;若Y包含定性值,那么数据集(由X和Y组成)用于分类。
2.探索性数据分析(EDA)
通常使用的三大EDA方法:
1)描述性统计:平均数、中位数、模式、标准差。
2)数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
3)数据整形:对数据进行透视、分组、过滤等。
3.数据预处理
数据清洗、数据整理、删除冗余数据,例如数据无量纲化(归一化 压缩到某一区间、标准化 服从N(0,1) )、缺失值、分类数据处理(编码,文字型转换为数值型;名义变量用哑变量;独热编码)、连续数据处理(设阈值二值化、分箱)
4.数据分割
- 分割为训练集+测试集(80%+20%)。训练集建立预测模型,然后将这种训练好的模型应用于测试集(即作为新的、未见过的数据)上进行预测。根据模型在测试集上的表现来选择最佳模型,为了获得最佳模型,还可以进行超参数优化。
- 分割为训练集+验证集+测试集(60%+20%+20%)。训练集用于建立预测模型,同时对验证集进行评估,据此进行预测,可以进行模型调优(如超参数优化),并根据验证集的结果选择性能最好的模型。测试集可以真正充当新的、未知的数据。
- 交叉验证
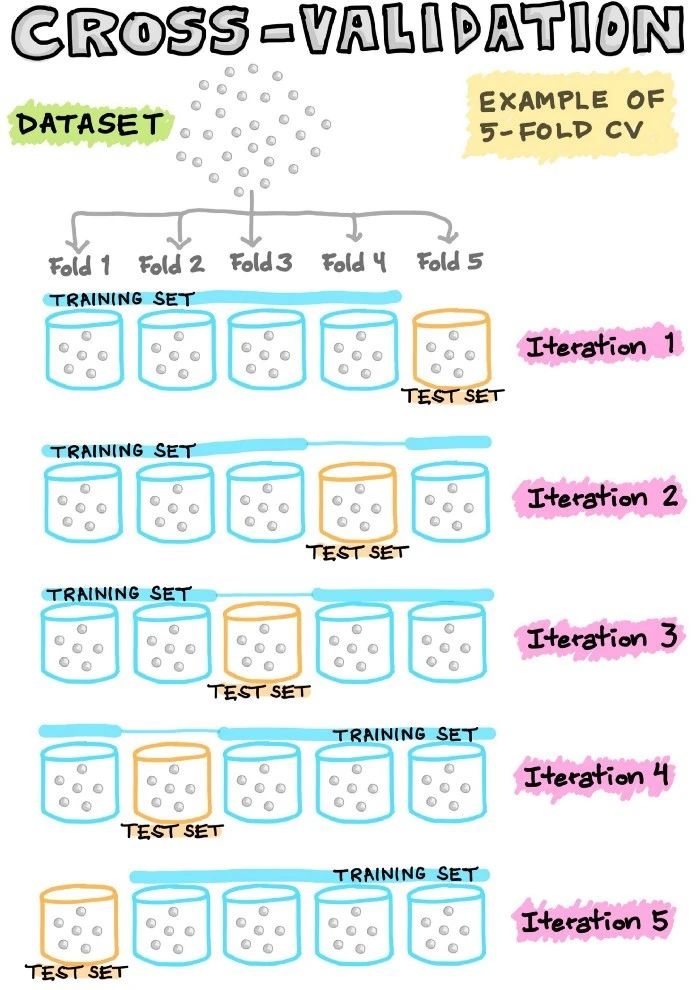
5.模型建立
- 学习算法:
监督学习:是一种机器学习任务,建立输入X和输出Y变量之间的数学(映射)关系。这样的X、Y对构成了用于建立模型的标签数据,以便学习如何从输入中预测输出。
无监督学习:是一种只利用输入X变量的机器学习任务。这种 X 变量是未标记的数据,学习算法在建模时使用的是数据的固有结构。
强化学习:是一种决定下一步行动方案的机器学习任务,它通过试错学习来实现这一目标,努力使回报最大化。 - 超参数调优:超参数本质上是机器学习算法的参数。
- 特征选择:过滤法(方差过滤、相关性过滤法(卡方过滤、F检验(线性关系)、互信息法(任意关系))、嵌入法、包装法
6.机器学习任务
在监督学习中,两个常见的机器学习任务包括分类和回归。
一个分类模型的过程示意图: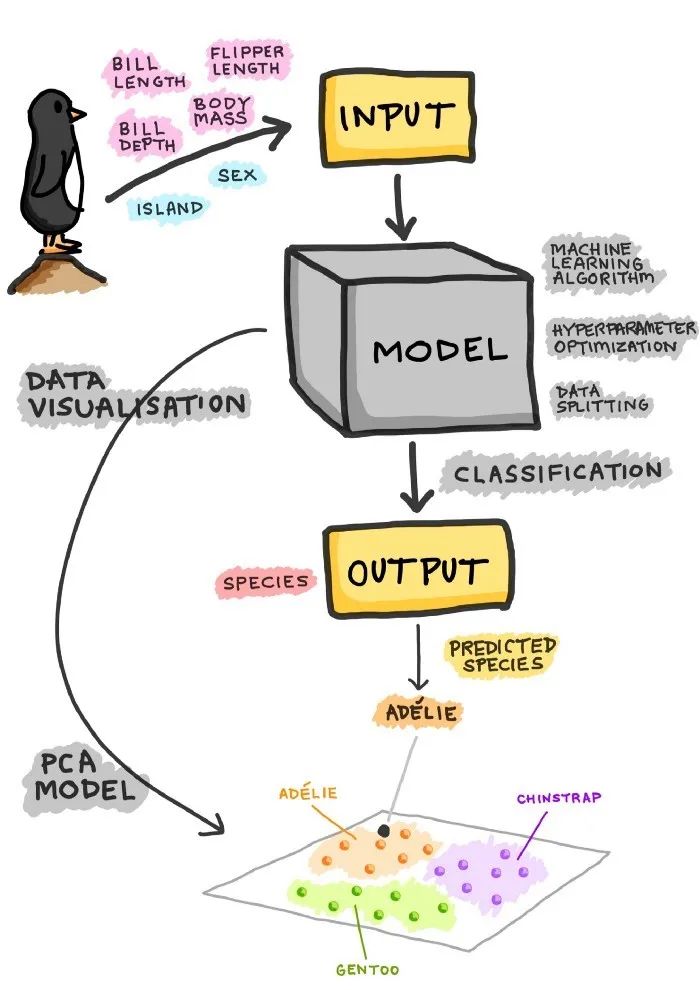
模型评价指标:
- 分类
准确率(Ac)、灵敏度(Sn)、特异性(Sp)、马太相关系数(MCC)
其中TP、TN、FP和FN分别表示真阳性、真阴性、假阳性和假阴性的实例。应该注意的是,MCC的范围从-1到1,其中MCC为-1表示最坏的可能预测,而值为1表示最好的可能预测方案。此外,MCC为0表示随机预测。 - 回归
Y = f(X) 以实际值为x轴,以预测值为y轴,做一个简单的散点图。
确定系数(R²):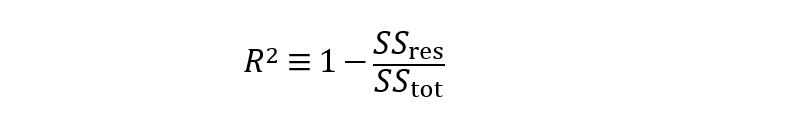
从公式中可以看出,R²实质上是1减去残差平方和(SSres)与总平方和(SStot)的比值。简单来说,可以说它代表了解释方差的相对量度。例如,如果R²=0.6,那么意味着该模型可以解释60%的方差(即60%的数据符合回归模型),而未解释的方差占剩余的40%。
均方误差(MSE)、均方根误差(RMSE) 也是衡量残差或预测误差的常用指标: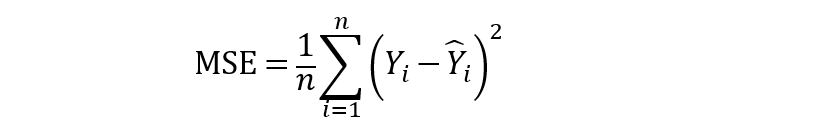
从上面的公式可以看出,MSE顾名思义是很容易计算的,取平方误差的平均值。此外,MSE的简单平方根可以得到RMSE。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)