sklearn中特征的方差过滤法:VarianceThreshold()简述
sklearn中特征的方差过滤法:VarianceThreshold()简述
在某些分析情形下,若数据维度较高,并且需要剔除一些特征,那么依据每个特征所携带的信息熵进行过滤是一种简便快速的特征筛选方法。
sklearn.feature_selection.VarianceThreshold概述
VarianceThreshold是sklearn库中feature_selection类中的一个函数,其特征选择原理只关心特征变量X,而不需要数据中的输出结果y,因此可以被用于无监督学习。
VarianceThreshold的参数、属性
| 类别 | 元素 | 解释 |
|---|---|---|
| 参数 | threshold(float, default = 0) | 唯一的参数,是VarianceThreshold进行过滤的标准,当被导入特征的方差小于threshold值时,该特征将会被过滤。 |
| 属性 | variances_(array, shape(n_feayures,)) | 每个被导入特征的方差值。 |
| 属性 | n_features_in_(int) | 模型拟合时用到的特征数量。 |
| 属性 | feature_names_in_(ndarray of shape(n_features_in_)) | 在拟合过程中被使用特征的名称。只有在x特征名完全由字符串组成时才会被生成。 |
VarianceThreshold的方法
模型的方法与sklearn中其他方法类似,见官方文档。sklearn.feature_selection.VarianceThreshold
VarianceThreshold使用实例
下面是一份关于乙醇工业制烯烃的试验数据。
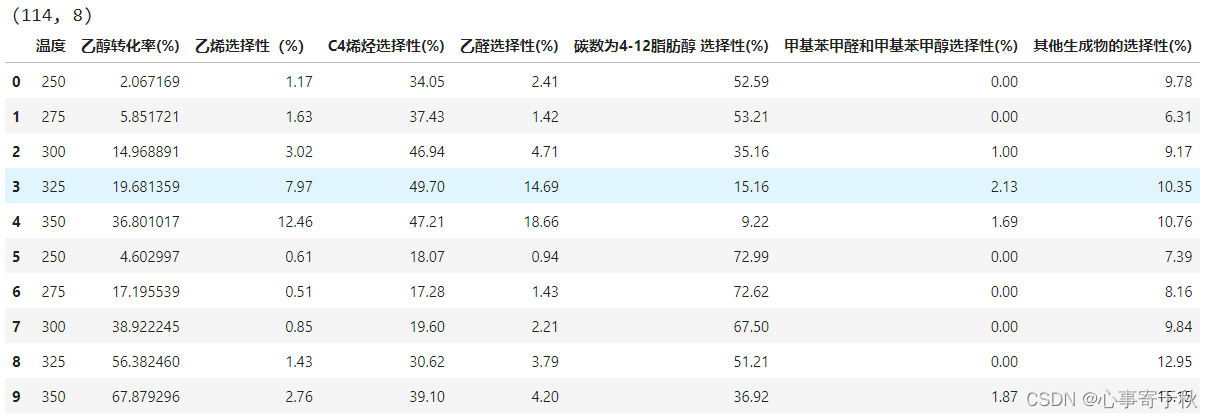
这里希望对除温度、乙醇转换率、C4烯烃选择性、碳数为4-12脂肪醇选择性四个主要特征之外的5项特征进行方差过滤。
将五项特征提取出来,使用VarianceThreshold方法拟合。
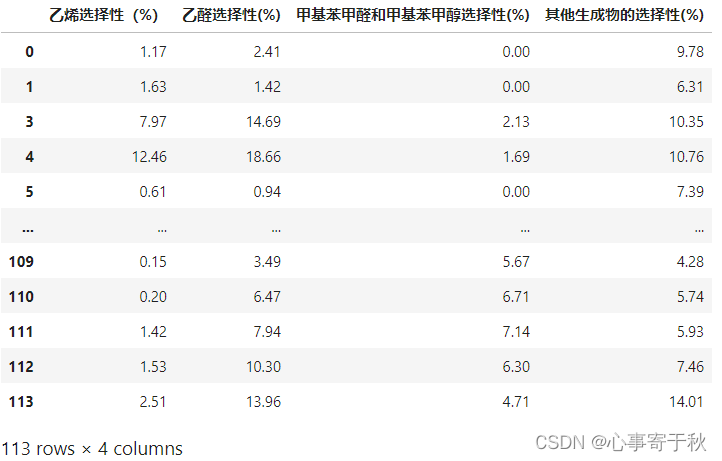
将该dataframe中的所有列作为特征导入VarianceThreshold方法中。
from sklearn.feature_selection import VarianceThreshold
var = VarianceThreshold(threshold=feature_variance.var().mean()) #这里让方差阀值等于四项特征的方差平均值
var.fit(feature_variance)
var.transform(feature_variance) #返回被留下的特征列
模型计算的结果及一系列属性已经保存在了训练好的模型中,现在来查看各个特征的方差值,以及留下了哪些特征。
var.feature_names_in_ #查看模型拟合时导入的特征名称
var.get_feature_names_out() #查看被留下特征的字符名称
var.variances_ #每个特征对应的方差值

可以发现,只有乙醛选择性这一特征的方差大于平均值,被保留了下来。
回顾
上述的方差过滤方法使用起来十分简便,可以结合matplotlib中的可视化方法进行解释,说明特征筛选的依据。
但要注意的是,本文在VarianceThreshold模型拟合前并没有对需要筛选的特征数据进行预处理(如标准化、归一化等),这会使VarianceThreshold计算出的方差受到数据尺度、量纲等因素干扰。因此,在进行VarianceThreshold拟合前应当对数据进行预处理。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)