购物篮分析( Apriori算法)—零售数据实战
系列文章目录【开题】在我从事零售行业的期间,曾拜读过"啤酒与尿布"一书,对于沃尔玛的购物篮分析模型产生极大的兴趣。由于网上对Aprioro算法介绍的内容较少,故而本人不得已回去复习了概率论,并自学了一段时间的购物篮分析基础知识,终于弄懂了购物篮分析模型基本的指标和计算等知识。由于本文参考了很多大佬写的文章,故而以@jiaxin_Jasmine(案例教程:https://blog.csdn.net/
购物篮分析( Apriori算法)—零售数据实战
【开题】在我从事零售行业的期间,曾拜读过"啤酒与尿布"一书,对于沃尔玛的购物篮分析模型产生极大的兴趣。由于网上对Aprioro算法介绍的内容较少,故而本人不得已回去复习了概率论,并自学了一段时间的购物篮分析基础知识,终于弄懂了购物篮分析模型基本的指标和计算等知识。由于本文参考了很多大佬写的文章,故而以@jiaxin_Jasmine(案例教程:https://blog.csdn.net/weixin_43962871/article/details/89160752)和@不论如何未来很美好(案例教程:https://blog.csdn.net/qq_36523839/article/details/83960195)为框架,构建业务数据上购物篮分析模型
前言
由于购物篮分析有较多的指标,如频繁集、支持度、置信度等概念,而本文仅作为一个业务数据实操性的讲解,故而相关的概念给出以下链接,请各位同学自行查阅:
1、@数据小斑马:关联算法①——《啤酒与尿布》购物篮分析
https://blog.csdn.net/cindy407/article/details/95242734
2、@qq924178473:关联规则——关联分析
https://blog.csdn.net/h_jlwg6688/article/details/107793274
提示:网上有较多的讲解,可多看
一、数据源介绍
首先要声明,本文数据源已做处理,仅用于教学讲解目的,不会泄露或侵犯到任何公司或个人利益,如有侵权行为,请咨询相关法律人士。
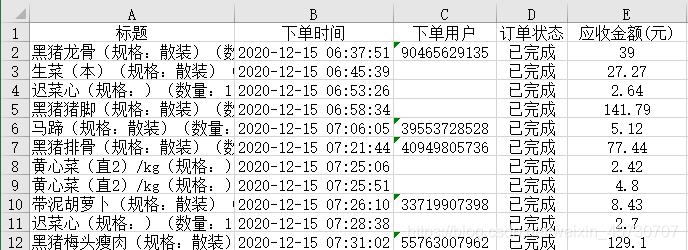
字段解释:标题(顾客购买商品明细)、下单时间、下单用户(有ID号的为注册会员、空值为普通顾客)、订单状态(成功交易、退款交易等)、应收金额(顾客付款金额)
时间范围:2020年12月15日~12月31日,半个月
此外提醒各位同学,对零售行业购物篮分析的数据尽可能时间范围缩短,因为零售行业有比较多的促销活动,会导致某一时段内,某些促销组合商品出现的频次比日常销售时段多,额外还会受到某些环境因素的影响等种种原因,故而本文选择半个月的交易清单作为数据源,尽量降低环境和促销因素的影响。
二、Apriori模型构建
1.数据导入和清洗
本次使用数据分析最常用的pandas和numpy库,还有最核心的mlxtend机器学习包
代码如下(示例):
#百香果店购物篮分析模型
import pandas as pd
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
#显示输出数据对齐设置,仅为数据输出好看一些
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
本次原始数据源共5个字段,8938条记录,其中下单用户非空行数1910条(注册会员ID交易记录),下单时间为string字符型,下单用户为float浮点型。
代码如下(示例):
#读取数据,建议使用短期正常销售数据,减少促销活动等因素影响
df_all = pd.read_excel('C:\\Users\\ASUS\\Desktop\\百香果店1215~1231订单.xlsx')
>>> df_all.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8938 entries, 0 to 8937
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 标题 8938 non-null object
1 下单时间 8938 non-null object
2 下单用户 1910 non-null float64
3 订单状态 8938 non-null object
4 应收金额(元) 8938 non-null float64
dtypes: float64(2), object(3)
memory usage: 349.3+ KB
本次数据源主要使用“标题”(商品明细)和有效“订单状态”两个字段。
首先,我们先抽取有效“订单状态”字段,选取已完成状态下的交易清单。
详情见下图
代码如下(示例):
#清洗数据
df = df_all.loc[(df_all['订单状态'] == '已完成'),:] #抽取已完成的订单

接着我们清洗“标题”(商品明细)字段
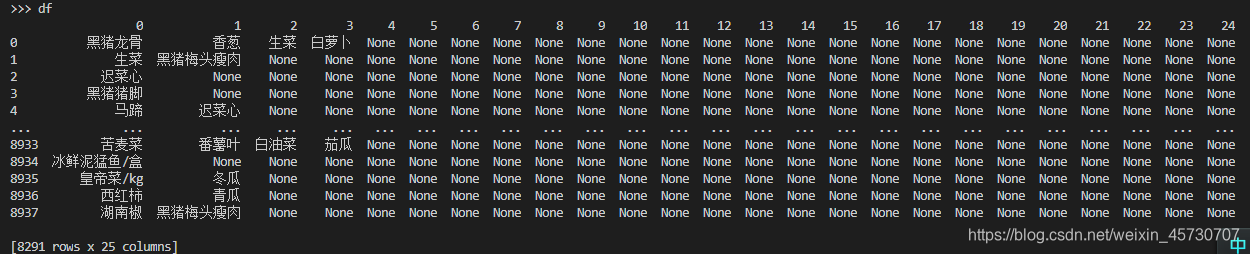
先以“,”为分隔符分割单个交易记录的商品明细,然后再剔除部分无效文本。
由于某些交易记录购买了25个商品,导致本文数据源出现[8291 rows x 25 columns]条数据,也就意味着某些只购买一个商品的交易记录仅占1列,其余列数以None填充。因此我们可以构建一个空数组,剔除空值,并追加逐行的数据组(详见dataset)
代码如下(示例):
df = df['标题'] #抽取商品明细
df = df.str.split(',',expand=True) #拆分商品明细
df.replace('\(.*\)','',inplace=True,regex=True) #剔除多余文本
dateset = [] #构建空数组,剔除None值
for i in range(len(df.values)):
dateset.append(list(filter(None,df.values[i])))
>>> dateset[0:5]
[['珍珠苦瓜(规格:散装)(数量:1)'], ['白馒头60g*6(规格:60g*6)(数量:2)'], ['腐皮kg(规格:)(数量:1)', '腐皮kg(规格:)(数量:1)', '黑猪梅头瘦肉(规格:散
装)(数量:1)', '黄心白(规格:散装)(数量:1)', '油面250g(规格:250g)(数量:1)', '细拉面250g(规格:250g)(数量:1)'], ['鲈鱼(HS) /盒(规格:250g-300g)(数量
:1)'], ['五指毛桃(规格:150g)(数量:2)']]
2.数据建模
经过上述操作,基本完成了模型必要的数据格式。
接着我们根据Apriori库必要数据格式转换数据源。
数据输出结果如下图所示,可见顾客总体购买的单品总数为391个
代码如下(示例):
#定义模型,转换数据格式
te = TransactionEncoder()
df_tf = te.fit(dateset).transform(dateset)
df_1 = pd.DataFrame(df_tf,columns=te.columns_) #单品转换

由于整体购买单品总数为391个,故我们需要测试不同支持度下的单品或组合商品比例。
为了节省时间,我们直接选择支持度最低阈值是0.5%。
即只要单个或组合商品占总体比例超过0.5%,即可出现在测试集里面。
有下面数据输出集可知,超过0.5%支持度的数据有151条,其中支持度平均数是1.3%,中位数为1.42%。
组合长度仅有1个单品和2两个单品。
代码如下(示例):
#计算支持度
#由于不重复商品共计391个,故组合商品支持度会偏低,测试用0.5%支持度为下限计算
df_2 = apriori(df_1,min_support=0.01,use_colnames=True)
df_2['lenght'] = df_2['itemsets'].apply(lambda x:len(x))
>>> df_2.describe()
support lenght
count 151.000000 151.000000
mean 0.013074 1.033113
std 0.011241 0.179526
min 0.005066 1.000000
25% 0.006754 1.000000
50% 0.010131 1.000000
75% 0.014172 1.000000
max 0.097455 2.000000
由于我们仅考虑组合商品,故我们提取≥2单品组合数的记录。
经过反复的支持度调试,我们最后选择支持度0.5%的组合商品。
(为什么会出现这么低的组合商品支持度呢?我唯一可解释的是,该门店可供给客户购买的商品较少,且大多数顾客仅购买一个促销单品,无法形成有效关联性交易,说白点就是,顾客仅购买促销单品后不再购买其他商品,故而促销单品的占比高)
由下面代码可见,顾客购买香葱和香菜的人偏多,其次是香菜和瘦肉、瘦肉和红萝卜、五花肉和瘦肉、排骨和瘦肉。
额,相信你们看到这里,肯定无法相信有人会买香葱接着买香菜,说实在话,我也不相信。但回去看了业务系统销售商品订单量在前10的排行榜,才发现瘦肉、香菜、香葱都在榜首,说明该店香葱和香菜可能比隔壁店便宜一点,才会这么多人顺手买。
代码如下(示例):
#计算组合单品大于1,支持度>0.005
df_3 = df_2.loc[(df_2['lenght'] > 1) & (df_2['support'] > 0.005),:].reset_index()
df_3.drop(['index'],axis=1)
>>> df_3.drop(['index'],axis=1)
support itemsets lenght
0 0.006272 (黑猪梅头瘦肉, 胡萝卜) 2
1 0.007719 (香葱, 香菜) 2
2 0.006272 (香葱, 黑猪梅头瘦肉) 2
3 0.005428 (黑猪五花肉, 黑猪梅头瘦肉) 2
4 0.005548 (黑猪排骨, 黑猪梅头瘦肉) 2
接着我们把测试集df_2(支持度≥0.5%)进行置信度的计算,发现买香葱和香菜的组合提升度是最高的,其次是买排骨和瘦肉的组合。
最后由于门店存在一定不合理操作情况,故而导致原数据存在偏低的支持度和置信度。因此我们不再往深程度进行分析,这也同时说明了,实际销售情况往往和理想状态不相符,现实总能给你惊喜!
代码如下(示例):
#计算置信度
>>> df_4
antecedents consequents antecedent support consequent support support confidence lift leverage conviction
0 (胡萝卜) (黑猪梅头瘦肉) 0.037752 0.097455 0.006272 0.166134 1.704726 0.002593 1.082362
1 (香葱) (香菜) 0.056447 0.022313 0.007719 0.136752 6.128713 0.006460 1.132568
2 (香菜) (香葱) 0.022313 0.056447 0.007719 0.345946 6.128713 0.006460 1.442623
3 (香葱) (黑猪梅头瘦肉) 0.056447 0.097455 0.006272 0.111111 1.140127 0.000771 1.015363
4 (黑猪五花肉) (黑猪梅头瘦肉) 0.032324 0.097455 0.005428 0.167910 1.722952 0.002277 1.084673
5 (黑猪排骨) (黑猪梅头瘦肉) 0.027620 0.097455 0.005548 0.200873 2.061189 0.002856 1.129414
总结
由于个人时间和精力有限,本文仅简略地介绍了一下Apriori算法模型的构建和分析,还有很多需要补充的细节,待各位同学自行去挖掘。最后感谢互联网上各位大佬的案例和讲解,若没有他们的文章,我们难以站在大佬的肩膀上看到这个世界。
*本文不提供数据源,请自行查找数据源进行操作

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)