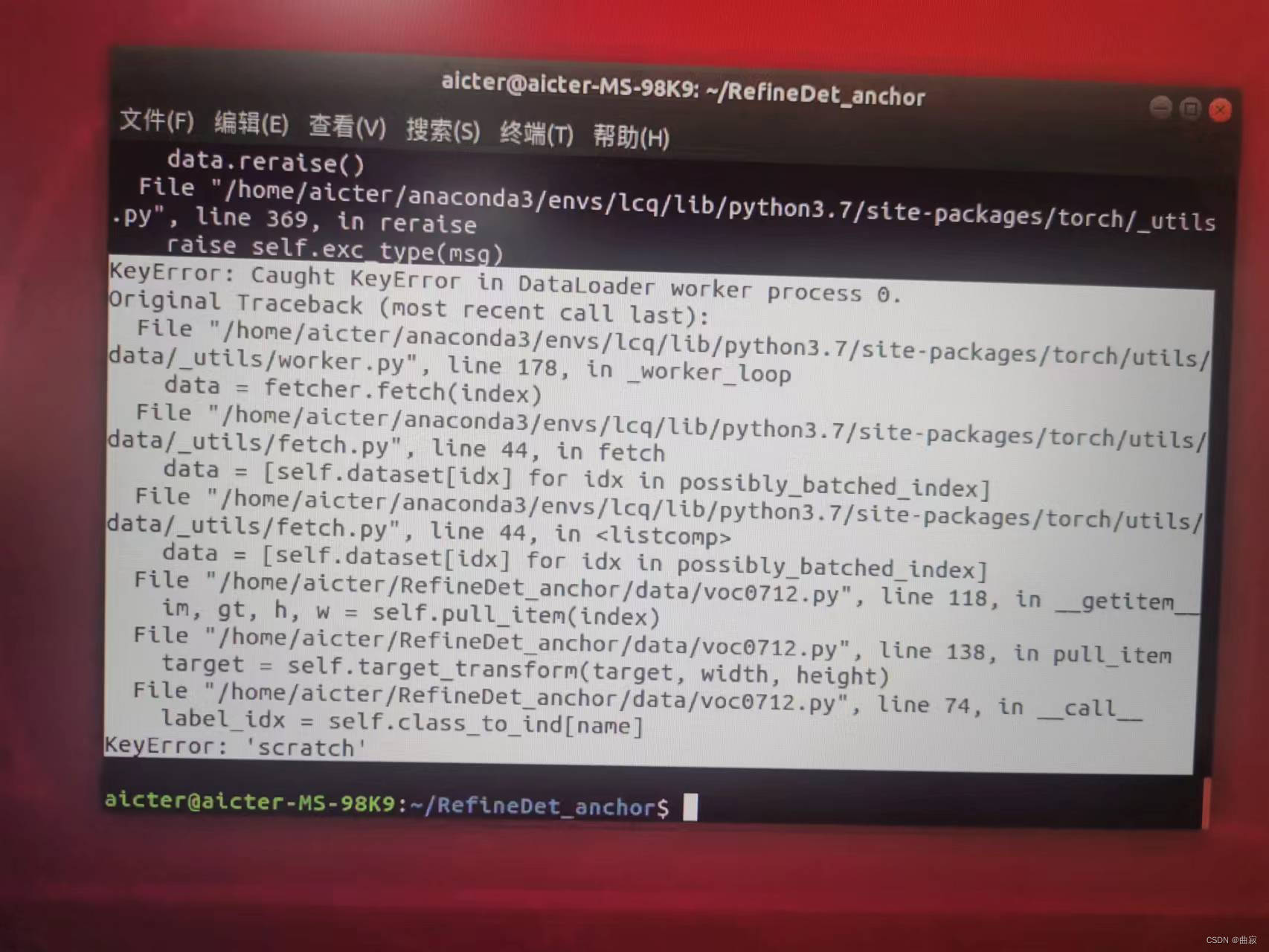
【KeyError:Caught KeyError in Dataloader worker process 0. KeyError:‘标签’】
用RefineDet训练单类别数据集时出现了两个错误。第一个KeyError是数据集加载相关的;第二个KeyError是使用了不存在的字典键值,即没读到图片标注的标签(scratch)。出现类似问题,建议先直接解决第二个,因为第一个很多时候是附带出错。
训练单类别数据集时出现的错误解决方案
这几天在用RefineDet训练单类别数据集(划痕)时出现了如下图的错误。第一个KeyError是数据集加载相关的;第二个KeyError是使用了不存在的字典键值,即没读到图片标注的标签(scratch)。出现类似这种两个错误的,建议先直接解决第二个,因为第一个很多时候是附带出错。
具体问题具体分析
首先,保证我们的模型是已经用别的数据集跑得通的。我的模型之前已经用VOC2007的部分数据集(人、猫、狗、车四类)跑通过一遍。比较两次跑数据集的操作,排除了 " 数据集加载路径(可不可以出现中文,我的是可以,也没有空格)、Ubuntu解压方式有没有对xml标注文件造成影响(我的各项都对齐了,当然也没漏给标签)" 等原因。
根据报错回溯,合理怀疑voc0712.py(这是用于解析xml文件位置坐标和类别的)出错,而不是Pytorch多线程环境什么的。**最后发现其实是,多类别改成单类别时,python元组没有加逗号。**如下图:
VOC_CLASSES = ('scratch',) # 要保留逗号
#VOC_CLASSES = ('person','cat','dog','car') # 原先多类别的数据标签
因为我的voc0712.py代码第138行报错回溯里的target_transform()最早可回溯到VOCAnnotationTransform类中,其中就用到了len(VOC_CLASSES)。而python中,如果元组(tuple)只有一个元素,则这个元素后面必须要有", ",否则元素就还是原来的类型。看下图:
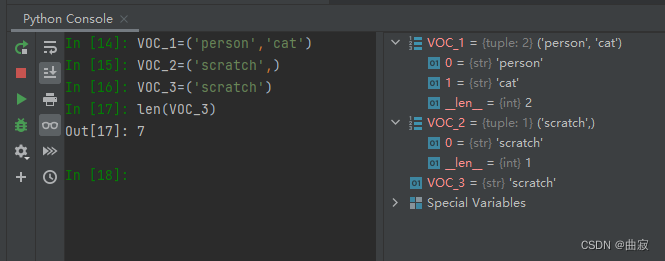
很基础的错误,说白了,还是没学python的原因;这点和C++还是很不一样的。
类似问题总结
出现此类问题的时候,网上查到过把num_worker改成=0,还有什么len -1。个人觉得,还是要具体问题具体分析,debug的大方向都是围绕数据集系列操作而引起的。
比如我之前还遇到过 “两个AttributeError” ," 两个IndexError且DataLoader worker process 0 可能随机变为 2、3" 的问题。前者是因为Annotations文件夹中多出了.txt文件并分入了训练集中;后者是某张图片标注的时候给了diffcult并且那张图只有单个标签存在。 第一次写博客,一点思路分享。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)