Python保存和读取csv文件
一、保存csv文件1.1np.savetxt()函数讲解np.savetxt(frame, array, fmt='%.18e', delimiter=None)* frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件* array : 存入文件的数组* fmt : 写入文件的格式,例如:%d %.2f %.18e* delimiter : 分割字符串,默认是任何空格1.2案例实
·
一、保存csv文件
1.1np.savetxt()函数讲解
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
* frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
* array : 存入文件的数组
* fmt : 写入文件的格式,例如:%d %.2f %.18e
* delimiter : 分割字符串,默认是任何空格1.2案例实操
import numpy as np
scores=np.random.randint(0,100,size=(20,2))
#执行命令之前,这个保存到文件要关闭
np.savetxt("scores2.csv",scores,delimiter=",",header='英语,数学',comments="")
# 保存文件的名字 保存的数组名 分割符 表的头部,与分隔符一致 注释默认是#

np.savetxt("scores3.csv",scores,delimiter=",",header='英语,数学',comments="",fmt='%d')
#保存数据的格式默认是科学计数法,这里我们改成整型
1.3函数介绍help(np.savetxt)
Help on function savetxt in module numpy.lib.npyio:
savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
Save an array to a text file.
Parameters
----------
fname : filename or file handle
If the filename ends in ``.gz``, the file is automatically saved in
compressed gzip format. `loadtxt` understands gzipped files
transparently.
X : 1D or 2D array_like
Data to be saved to a text file.
fmt : str or sequence of strs, optional
A single format (%10.5f), a sequence of formats, or a
multi-format string, e.g. 'Iteration %d -- %10.5f', in which
case `delimiter` is ignored. For complex `X`, the legal options
for `fmt` are:
* a single specifier, `fmt='%.4e'`, resulting in numbers formatted
like `' (%s+%sj)' % (fmt, fmt)`
* a full string specifying every real and imaginary part, e.g.
`' %.4e %+.4ej %.4e %+.4ej %.4e %+.4ej'` for 3 columns
* a list of specifiers, one per column - in this case, the real
and imaginary part must have separate specifiers,
e.g. `['%.3e + %.3ej', '(%.15e%+.15ej)']` for 2 columns
delimiter : str, optional
String or character separating columns.
newline : str, optional
String or character separating lines.
.. versionadded:: 1.5.0
header : str, optional
String that will be written at the beginning of the file.
.. versionadded:: 1.7.0
footer : str, optional
String that will be written at the end of the file.
.. versionadded:: 1.7.0
comments : str, optional
String that will be prepended to the ``header`` and ``footer`` strings,
to mark them as comments. Default: '# ', as expected by e.g.
``numpy.loadtxt``.
.. versionadded:: 1.7.0
encoding : {None, str}, optional
Encoding used to encode the outputfile. Does not apply to output
streams. If the encoding is something other than 'bytes' or 'latin1'
you will not be able to load the file in NumPy versions < 1.14. Default
is 'latin1'.
.. versionadded:: 1.14.0
See Also
--------
save : Save an array to a binary file in NumPy ``.npy`` format
savez : Save several arrays into an uncompressed ``.npz`` archive
savez_compressed : Save several arrays into a compressed ``.npz`` archive
Notes
-----
Further explanation of the `fmt` parameter
(``%[flag]width[.precision]specifier``):
flags:
``-`` : left justify
``+`` : Forces to precede result with + or -.
``0`` : Left pad the number with zeros instead of space (see width).
width:
Minimum number of characters to be printed. The value is not truncated
if it has more characters.
precision:
- For integer specifiers (eg. ``d,i,o,x``), the minimum number of
digits.
- For ``e, E`` and ``f`` specifiers, the number of digits to print
after the decimal point.
- For ``g`` and ``G``, the maximum number of significant digits.
- For ``s``, the maximum number of characters.
specifiers:
``c`` : character
``d`` or ``i`` : signed decimal integer
``e`` or ``E`` : scientific notation with ``e`` or ``E``.
``f`` : decimal floating point
``g,G`` : use the shorter of ``e,E`` or ``f``
``o`` : signed octal
``s`` : string of characters
``u`` : unsigned decimal integer
``x,X`` : unsigned hexadecimal integer
This explanation of ``fmt`` is not complete, for an exhaustive
specification see [1]_.
References
----------
.. [1] `Format Specification Mini-Language
<http://docs.python.org/library/string.html#
format-specification-mini-language>`_, Python Documentation.
Examples
--------
>>> x = y = z = np.arange(0.0,5.0,1.0)
>>> np.savetxt('test.out', x, delimiter=',') # X is an array
>>> np.savetxt('test.out', (x,y,z)) # x,y,z equal sized 1D arrays
>>> np.savetxt('test.out', x, fmt='%1.4e') # use exponential notation二、读取csv文件
2.1 np.loadtxt
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
* frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件。
* dtype:数据类型,可选。
* delimiter:分割字符串,默认是任何空格。
* skiprows:跳过前面x行。
* usecols:读取指定的列,用元组组合。
* unpack:如果True,读取出来的数组是转置后的2.2案例
b=np.loadtxt("scores3.csv",dtype=np.int,delimiter=',')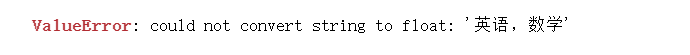
因为第一行是string,不能转化为我们想要的float类型,故跳过第一行
b=np.loadtxt("scores3.csv",dtype=np.int,delimiter=',',skiprows=1)
b
2.3函数介绍 help(np.loadtxt)
Help on function loadtxt in module numpy.lib.npyio:
loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes')
Load data from a text file.
Each row in the text file must have the same number of values.
Parameters
----------
fname : file, str, or pathlib.Path
File, filename, or generator to read. If the filename extension is
``.gz`` or ``.bz2``, the file is first decompressed. Note that
generators should return byte strings for Python 3k.
dtype : data-type, optional
Data-type of the resulting array; default: float. If this is a
structured data-type, the resulting array will be 1-dimensional, and
each row will be interpreted as an element of the array. In this
case, the number of columns used must match the number of fields in
the data-type.
comments : str or sequence of str, optional
The characters or list of characters used to indicate the start of a
comment. None implies no comments. For backwards compatibility, byte
strings will be decoded as 'latin1'. The default is '#'.
delimiter : str, optional
The string used to separate values. For backwards compatibility, byte
strings will be decoded as 'latin1'. The default is whitespace.
converters : dict, optional
A dictionary mapping column number to a function that will parse the
column string into the desired value. E.g., if column 0 is a date
string: ``converters = {0: datestr2num}``. Converters can also be
used to provide a default value for missing data (but see also
`genfromtxt`): ``converters = {3: lambda s: float(s.strip() or 0)}``.
Default: None.
skiprows : int, optional
Skip the first `skiprows` lines; default: 0.
usecols : int or sequence, optional
Which columns to read, with 0 being the first. For example,
``usecols = (1,4,5)`` will extract the 2nd, 5th and 6th columns.
The default, None, results in all columns being read.
.. versionchanged:: 1.11.0
When a single column has to be read it is possible to use
an integer instead of a tuple. E.g ``usecols = 3`` reads the
fourth column the same way as ``usecols = (3,)`` would.
unpack : bool, optional
If True, the returned array is transposed, so that arguments may be
unpacked using ``x, y, z = loadtxt(...)``. When used with a structured
data-type, arrays are returned for each field. Default is False.
ndmin : int, optional
The returned array will have at least `ndmin` dimensions.
Otherwise mono-dimensional axes will be squeezed.
Legal values: 0 (default), 1 or 2.
.. versionadded:: 1.6.0
encoding : str, optional
Encoding used to decode the inputfile. Does not apply to input streams.
The special value 'bytes' enables backward compatibility workarounds
that ensures you receive byte arrays as results if possible and passes
'latin1' encoded strings to converters. Override this value to receive
unicode arrays and pass strings as input to converters. If set to None
the system default is used. The default value is 'bytes'.
.. versionadded:: 1.14.0
Returns
-------
out : ndarray
Data read from the text file.
See Also
--------
load, fromstring, fromregex
genfromtxt : Load data with missing values handled as specified.
scipy.io.loadmat : reads MATLAB data files
Notes
-----
This function aims to be a fast reader for simply formatted files. The
`genfromtxt` function provides more sophisticated handling of, e.g.,
lines with missing values.
.. versionadded:: 1.10.0
The strings produced by the Python float.hex method can be used as
input for floats.
Examples
--------
>>> from io import StringIO # StringIO behaves like a file object
>>> c = StringIO(u"0 1\n2 3")
>>> np.loadtxt(c)
array([[ 0., 1.],
[ 2., 3.]])
>>> d = StringIO(u"M 21 72\nF 35 58")
>>> np.loadtxt(d, dtype={'names': ('gender', 'age', 'weight'),
... 'formats': ('S1', 'i4', 'f4')})
array([('M', 21, 72.0), ('F', 35, 58.0)],
dtype=[('gender', '|S1'), ('age', '<i4'), ('weight', '<f4')])
>>> c = StringIO(u"1,0,2\n3,0,4")
>>> x, y = np.loadtxt(c, delimiter=',', usecols=(0, 2), unpack=True)
>>> x
array([ 1., 3.])
>>> y
array([ 2., 4.])三、numpy独有的保存和读取文件的方法(只能存储统一数据类型的数据,save-load函数匹配使用,可以存储多维数组,上面的savetxt只能存储二维数组)
numpy中还有一种独有的存储解决方案。文件名是以.npy或者npz结尾的。以下是存储和加载的函数。




为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)