协同过滤算法及python实现
协同过滤算法及python实现1.算法简介协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由: ●根据和你有共同喜好的人给你推荐 ●根据你喜欢的物品给你推荐相似物品 ●根据以上条件综合推荐 因此可以得出常用的协同过滤算法分为两种,基于用户
协同过滤算法及python实现
1.算法简介
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由:
●根据和你有共同喜好的人给你推荐
●根据你喜欢的物品给你推荐相似物品
●根据以上条件综合推荐
因此可以得出常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。
2.基于用户(User-Based)的协同过滤算法
- 算法简介
基于用户的 CF 就是从用户出发,基于用户对物品的偏好找到和目标用户兴趣相似的用户集合;然后找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。找到的用户集合中的用户可以是一个,也可以是多个,一般默认为一个用户,也就是默认只找到找到一个最相似用户。
2.相似度计算
根据用户-商品评分矩阵计算用户之间的相似度。计算相似度常用的方法有余弦算法、修正余弦算法、皮尔逊算法等等(这里以余弦算法为例)。余弦算法公式如图1所示:
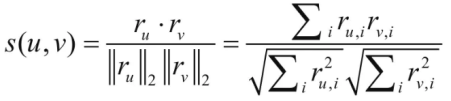
3.计算用户u对未评分商品的预测分值
首先根据上一步中的相似度计算,寻找用户u的邻居集N∈U,其中N表示邻居集,U表示用户集。然后,结合用户评分数据集,预测用户u对项i的评分,计算公式如下所示:
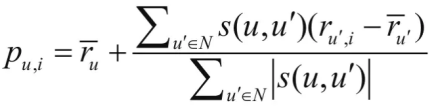
预测用户u对项i的评分; N是最近邻集合;u’是任意一个最近邻居。
其中,s(u,u’)表示用户u和用户u’的相似度。
表示最近邻u’和目标用户u的相似度乘以最近邻u’对项目i的评分。得到预测评分后按照评分高低进行降序推荐。
4.算法流程
1.计算其他用户的相似度,可以使用反查表除掉一部分用户
2.根据相似度找到与你最相似的K个用户
3.在这些邻居喜欢的物品中,根据与你的相似度算出每一件物品的推荐度
4.根据相似度推荐物品
5.具体实施
1.根据用户历史行为信息构建用户-商品评分矩阵,用户历史行为信息包括商品评分、浏览历史、收藏历史、喜好标签等,本文以单一的商品评分为例,后期介绍其他行为信息和混合行为信息,用户-商品评分矩阵如表1所示:
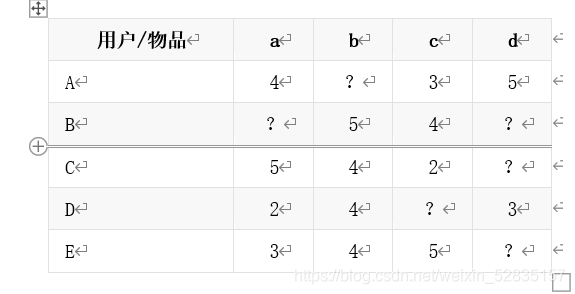
2.目标:向用户x推荐可能感兴趣的商品。(这里以用户C为例
3.算法实现:
数据描述 数据为用户,以及用户购买的商品,评分。
6.python 代码
import numpy as np
from math import sqrt
def pex(ls_1,ls_2,M): #求余弦相似度的函数、可用不同字母表示两用户(ls_1表示用户u、ls_2表示用户v)、M表示评分矩阵的每一行
fenzi=0#余弦相似度分子
fenmu=0#分母
abs_1=0#分母左边绝对值里的值
abs_2=0#分母右边绝对值里的值
for i in range(M):
fenzi += ls_1[i] * ls_2[i]#用户u、v对同一商品的评分积的和
abs_1 += pow(ls_1[i],2)#用户u所有评分的平方再开根号
abs_2 += pow(ls_2[i],2)
fenmu=sqrt(abs_1*abs_2)
return fenzi/fenmu#ls_1,ls_2用户相关系数
def yuping(lst_u,R,u_u,M,N,n):#求预测评分函数,lst_[i]表示u用户对i的评分, u_u表示用户间的相似度,M:行长,N:列长,n:另一用户
#初始化
fenzi=0
fenmu=0
aver_1=0#平均值
aver_2=0
#求平均值 需要知道总个数和总评分
a=0#当前u用户购买物品数量
b=0
for i in range(M):
if lst_u[i]!=0:#lst_[i]表示u用户对i的评分
a+=1#用户u购买的总数量
aver_1 +=lst_u[i]#用户u对所购买商品的总评分
aver_1=aver_1/a#u用户的商品平均分
#用户v对商品的平均分计算
for o in range(N):
if R[o][m]!=0:
for i in range(M):
if R[o][i]!=0:
b+=1#用户v购买的总数量
aver_2 +=R[o][i]
aver_2=aver_2/b
fenzi+=u_u[n][o]*(R[o][m]-aver_2)#两用户u,v(n,o)间的相似度*(用户o对某商品的评分-用户o的平均值)
fenmu+=abs(pex(lst_u,R[o],M))
return aver_1+fenzi/fenmu#预测公式
R=np.array([[4,0,3,5],#生成原始矩阵R
[0,5,4,0],
[5,4,2,0],
[2,4,0,1],
[3,4,5,0]])
N=len(R)#列长
M=len(R[0])#行长
u_u=np.zeros((N,N))#建立用户与用户之间相关性矩阵u_u
for n in range(N):#建立一个对R的循环筛选未评分item并进行预测评分
for m in range(N):
if n<m:
u_u[n][m]=pex(R[n],R[m],M)
u_u[m][n]=u_u[n][m]
print("得到的用户-用户相似度矩阵:")
print(u_u)#打印用户与用户相关系数矩阵
user=['A','B','C','D','E']#用户集合
items=['p1','p2','p3','p4']#商品集合
for n in range(N):#建立一个对R循环寻找未评分项并且对未评分项进行预测
for m in range(M):
if R[n][m]==0:
R[n][m]=yuping(R[n],R,u_u,M,N,n)
if R[n][m]>3:
print("将商品{:}推荐给用户{:}".format(items[m],user[n]))
print("评分预测矩阵R^:")
print("{:}".format(R))
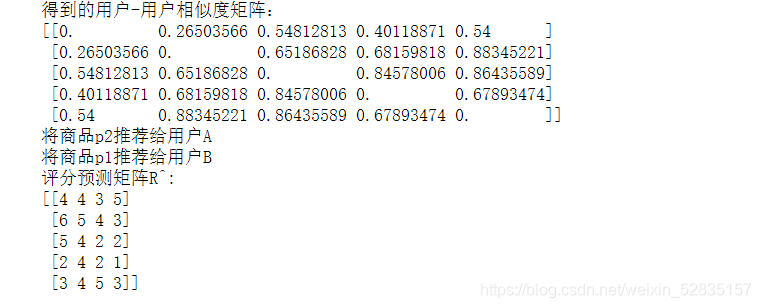
7.实验结果
3. 基于物品(Item-Based)的协同过滤算法
1.算法流程
1.构建用户–>物品的倒排;
2.构建物品与物品的共现矩阵;
3.计算物品之间的相似度,即计算相似矩阵;
4.根据用户的历史记录,给用户推荐物品;
2.具体实施
行表示用户,列表示物品,用户访问商品下:
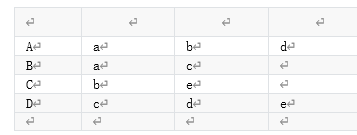
1.构建用户–>物品的倒排 :
| 物品a | 用户A | 用户B |
| 物品b | 用户A | 用户C |
| 物品c | 用户B | 用户D |
| 物品d | 用户A | 用户D |
| 物品e | 用户C | 用户D |
2.构建物品与物品的共现矩阵
共现矩阵C表示都访问两个物品的用户数,是根据用户物品倒排表计算出来的。如根据上面的用户物品倒排表可以计算出如下的共现矩阵C:

3.计算物品之间的相似度,即计算相似矩阵两个物品之间的相似度 :
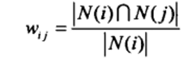
|N(i)|表示喜欢物品i的用户数,|N(i)⋂N(j)|表示同时喜欢物品i,j的用户数.
当物品j是一个很热门的商品时,人人都喜欢,那么wij就会很接近于1,即(1)式会让很多物品都和热门商品有一个很大的相似度,所以可以改进一下公式 :
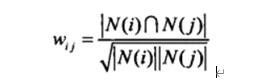
矩阵N(用于计算分母)表示喜欢某物品的用户数(是总的用户数),矩阵N如下所示:

4.计算物品之间的余弦相似矩阵如下 :

5.根据用户的历史记录,给用户推荐物品;最终推荐的是什么物品,是由预测兴趣度决定的。

通俗的说就是:用户u物品j预测兴趣度=用户喜欢的物品i的兴趣度×物品i和物品j的相似度。(S ( j , k ) 表示和物品j 最相似的K 个物品集合、N ( u ) 表示用户喜欢的物品集合。由于i∈N(u)∩S(j,K)很难理解,引入另一种计算方式。
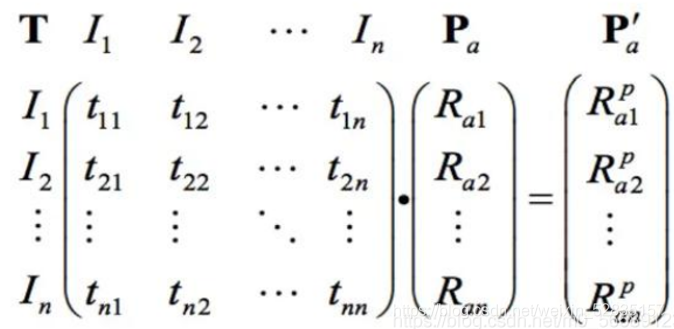
T表示原本的共现评分矩阵,Pa表示新用户对不同商品的评分Ra1 Ra2…Ran。
结果 = T的每一行每个数分别于Pa的每个数相乘的和

如 有新用户E访问了a,d,e。预测其他相似度是:

结果1:0.5 = 01+0.50+0.50+0.51+0*1
Python实现
import numpy as np
from math import sqrt
def pex(ls_1,ls_2,M): #求余弦相似度的函数
fenzi=0#余弦相似度分子
fenmu=0#分母
abs_1=0#分母左边绝对值里的值
abs_2=0#分母右边绝对值里的值
for i in range(M):
fenzi += ls_1[i] * ls_2[i]
abs_1 += pow(ls_1[i],2)
abs_2 += pow(ls_2[i],2)
fenmu=sqrt(abs_1*abs_2)
return fenzi/fenmu#ls_1,ls_2用户相关系数
def yuping(lst_u,R,u_u,M,N,n):#求预测评分函数
fenzi=0
fenmu=0
aver_1=0#平均值
aver_2=0
a=0#当前用户购买物品数量
b=0
for i in range(M):
if lst_u[i]!=0:
a+=1
aver_1 +=lst_u[i]
aver_1=aver_1/a
for o in range(N):
if R[o][m]!=0:
for i in range(M):
if R[o][i]!=0:
b+=1
aver_2 +=R[o][i]
aver_2=aver_2/b
fenzi+=u_u[n][o]*(R[o][m]-aver_2)
fenmu+=abs(pex(lst_u,R[o],M))
return aver_1+fenzi/fenmu
R=np.array([[4,0,3,5],#生成原始矩阵R
[0,5,4,0],
[5,4,2,0],
[2,4,0,1],
[3,4,5,0]])
N=len(R)#列长
M=len(R[0])#行长
u_u=np.zeros((N,N))#建立用户与用户之间相关性矩阵u_u
for n in range(N):#建立一个对R的循环筛选未评分item并进行预测评分
for m in range(N):
if n<m:
u_u[n][m]=pex(R[n],R[m],M)
u_u[m][n]=u_u[n][m]
print("得到的用户-用户相似度矩阵:")
print(u_u)#打印用户与用户相关系数矩阵
user=['A','B','C','D','E']#用户集合
items=['a','b','c','d']#商品集合
for n in range(N):#建立一个对R循环寻找未评分项并且对未评分项进行预测
for m in range(M):
if R[n][m]==0:
R[n][m]=yuping(R[n],R,u_u,M,N,n)
if R[n][m]>3:
print("将商品{:}推荐给用户{:}".format(items[m],user[n]))
print("评分预测矩阵R^:")
print("{:}".format(R))

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)