二分类神经网络结果准确率50%,loss一直在0.69的解决方法
先参考这篇文章,了解为什么loss是0.69链接:https://www.jianshu.com/p/45c2180cab17这个问题很多人在训练自己或者迁移别的网络的时候都会遇到,特别是二分类这样的简单网络,感觉无处着手,都他妈的是对的,就是Loss不动。到底什么原因了?吐槽的网址很多。比如这里,或者这里。若想知道解决办法,请直接跳到文章最后。0.69是个什么数?一般采用的都是cross ent
先参考这篇文章,了解为什么loss是0.69
链接:https://www.jianshu.com/p/45c2180cab17
这个问题很多人在训练自己或者迁移别的网络的时候都会遇到,特别是二分类这样的简单网络,感觉无处着手,都他妈的是对的,就是Loss不动。到底什么原因了?吐槽的网址很多。比如这里,或者这里。若想知道解决办法,请直接跳到文章最后。
-
0.69是个什么数?
一般采用的都是cross entropy loss value,定义如下:发现就是网络预测给出的二类概率向量为[0.5,0.5],也就是a和1-a都是0.5,不管y取值0/1,整个的平均loss就是-ln(0.5)=0.69.
-
为啥a老是为0.5呢?
a的值是softmax的输出,在二分类的情况下为0.5,表明输入softmax的值x是(近似)相等的。进一步观察发现,x几乎都很小,随着训练的进行,还有进一步变小的趋势,可怕!
-
为啥Conv和Pooling网络的输出一直往0走
这个我是不清楚的,可能是初始化参数太小,可能是Relu形成的Dead node。于是我调整initializer,调整Relu为leaky-Relu。经过这些处理,网络能够保证在前两次Loss不为0.69,后面又回到了这个可怕的0.69。想到的方案统统不起作用,我甚至怀疑我是不是maximize loss 而不是 minimize loss。 -
最终办法
显然不是我的loss写错了,而是数据分布的问题。调整初始化和激活函数无法间接保证与调节数据分布,那我就强上了BN层,即,在网络的最后某个位置加上Batch Normalization层操作,归一化强力保证其分布,果然彻底解决了0.69问题。在此,不得不佩服前人在网络发展过程中的巨大贡献。 -
从VGG-16训练好的模型进行fine-tuning也不发生改变,当在网络中加入初始化参数和
decay_mult以后再次训练网络开始收敛。
我想这才是解决0.69问题的最终办法。选择不同的optimizer或者网络组成,都极有可能失败。
事实上,我的解决方法是换网络,并且修改学习率
原来学习率一直不变,这里用了lr_scheduler.StepLR,能够在每7个epoch下降低0.1倍LR,
最后的loss可以看结果,验证loss前期还是有震荡的,
学习率(Learning rate)的理解以及如何调整学习率 - LLLiuye - 博客园![]() https://www.cnblogs.com/lliuye/p/9471231.html深度神经网络训练过程中为什么验证集上波动很大_一个值得深思的问题?为什么验证集的loss会小于训练集的loss..._weixin_39836726的博客-CSDN博客编辑:zero 关注 搜罗最好玩的计算机视觉论文和应用,AI算法与图像处理 微信公众号,获得第一手计算机视觉相关信息在本教程中,您将学习在训练自己的自定义深度神经网络时,验证损失可能低于训练损失的三个主要原因。我的验证损失低于训练损失!怎么可能呢?我是否意外地将训练和验证loss绘图的标签切换了? 潜在地。 我没有像matplotlib这样的绘图库,因此将丢失日志通过管道传输到CSV文件,然后在E...
https://www.cnblogs.com/lliuye/p/9471231.html深度神经网络训练过程中为什么验证集上波动很大_一个值得深思的问题?为什么验证集的loss会小于训练集的loss..._weixin_39836726的博客-CSDN博客编辑:zero 关注 搜罗最好玩的计算机视觉论文和应用,AI算法与图像处理 微信公众号,获得第一手计算机视觉相关信息在本教程中,您将学习在训练自己的自定义深度神经网络时,验证损失可能低于训练损失的三个主要原因。我的验证损失低于训练损失!怎么可能呢?我是否意外地将训练和验证loss绘图的标签切换了? 潜在地。 我没有像matplotlib这样的绘图库,因此将丢失日志通过管道传输到CSV文件,然后在E...https://blog.csdn.net/weixin_39836726/article/details/110816605
在线程中,Aurélien简洁明了地解释了训练深度神经网络时验证损失可能低于训练损失的三个原因:
- 原因1:在训练期间应用正则化,但在验证/测试期间未进行正则化。如果在验证/测试期间添加正则化损失,则损失值和曲线将看起来更加相似。
- 原因2:训练损失是在每个epoch期间测量的,而验证损失是在每个epoch后测量的。平均而言,训练损失的测量时间是前一个时期的1/2。如果将训练损失曲线向左移动半个epoch,则损失会更好。
- 原因3:您的验证集可能比训练集更容易,或者代码中的数据/错误泄漏。确保您的验证集大小合理,并且是从与您的训练集相同的分布(和难度)中抽取的。
- 奖励:您的模型可能over-regularizing 。尝试减少正则化约束,包括增加模型容量(即通过更多参数使其更深),减少dropout,降低L2权重衰减强度等
有时候我们做训练的时候,会得到测试集的准确率或者验证集的准确率高于训练集的准确率,这是什么原因造成的呢?经过查阅资料,有以下几点原因,仅作参考,不对的地方,请大家指正。
(1)数据集太小的话,如果数据集切分的不均匀,或者说训练集和测试集的分布不均匀,如果模型能够正确捕捉到数据内部的分布模式话,这可能造成训练集的内部方差大于验证集,会造成训练集的误差更大。这时你要重新切分数据集或者扩充数据集,使其分布一样
(2)由Dropout造成,它能基本上确保您的测试准确性最好,优于您的训练准确性。Dropout迫使你的神经网络成为一个非常大的弱分类器集合,这就意味着,一个单独的分类器没有太高的分类准确性,只有当你把他们串在一起的时候他们才会变得更强大。
因为在训练期间,Dropout将这些分类器的随机集合切掉,因此,训练准确率将受到影响
在测试期间,Dropout将自动关闭,并允许使用神经网络中的所有弱分类器,因此,测试精度提高。
原文链接:https://blog.csdn.net/IT_flying625/article/details/105013514
直接使用pytorch官网代码,换成自己的数据集

"C:\Program Files\Python36\python.exe" E:/PycharmProjects/Two_Classifer/transfer_learning/tutorial.py
Epoch 0/24
----------
train Loss: 0.9054 Acc: 0.5021
val Loss: 0.6661 Acc: 0.7623
Epoch 1/24
----------
train Loss: 0.9094 Acc: 0.4604
val Loss: 0.9169 Acc: 0.5000
Epoch 2/24
----------
train Loss: 0.8252 Acc: 0.5375
val Loss: 2.1530 Acc: 0.5000
Epoch 3/24
----------
train Loss: 0.7955 Acc: 0.6083
val Loss: 0.7882 Acc: 0.5000
Epoch 4/24
----------
train Loss: 0.8170 Acc: 0.5833
val Loss: 1.4707 Acc: 0.5000
Epoch 5/24
----------
train Loss: 0.7669 Acc: 0.6188
val Loss: 0.6386 Acc: 0.5984
Epoch 6/24
----------
train Loss: 0.6963 Acc: 0.6896
val Loss: 10.9110 Acc: 0.5000
Epoch 7/24
----------
train Loss: 0.5715 Acc: 0.7688
val Loss: 0.1163 Acc: 0.9590
Epoch 8/24
----------
train Loss: 0.4611 Acc: 0.7896
val Loss: 0.3682 Acc: 0.8852
Epoch 9/24
----------
train Loss: 0.5228 Acc: 0.7646
val Loss: 2.0417 Acc: 0.5164
Epoch 10/24
----------
train Loss: 0.4558 Acc: 0.7833
val Loss: 0.1252 Acc: 0.9672
Epoch 11/24
----------
train Loss: 0.4976 Acc: 0.7896
val Loss: 1.1623 Acc: 0.6311
Epoch 12/24
----------
train Loss: 0.4825 Acc: 0.7937
val Loss: 0.3590 Acc: 0.8852
Epoch 13/24
----------
train Loss: 0.3681 Acc: 0.8479
val Loss: 0.1620 Acc: 0.9508
Epoch 14/24
----------
train Loss: 0.4887 Acc: 0.8208
val Loss: 0.4203 Acc: 0.8689
Epoch 15/24
----------
train Loss: 0.4512 Acc: 0.8083
val Loss: 0.1872 Acc: 0.9426
Epoch 16/24
----------
train Loss: 0.5182 Acc: 0.7708
val Loss: 0.3605 Acc: 0.8770
Epoch 17/24
----------
train Loss: 0.4109 Acc: 0.8458
val Loss: 0.2271 Acc: 0.9016
Epoch 18/24
----------
train Loss: 0.4736 Acc: 0.7958
val Loss: 0.1447 Acc: 0.9590
Epoch 19/24
----------
train Loss: 0.4115 Acc: 0.8125
val Loss: 0.1243 Acc: 0.9672
Epoch 20/24
----------
train Loss: 0.4137 Acc: 0.8354
val Loss: 0.1722 Acc: 0.9508
Epoch 21/24
----------
train Loss: 0.4321 Acc: 0.8292
val Loss: 0.1311 Acc: 0.9672
Epoch 22/24
----------
train Loss: 0.4375 Acc: 0.8271
val Loss: 0.1355 Acc: 0.9672
Epoch 23/24
----------
train Loss: 0.4411 Acc: 0.8146
val Loss: 0.1304 Acc: 0.9672
Epoch 24/24
----------
train Loss: 0.4619 Acc: 0.7958
val Loss: 0.0974 Acc: 0.9836
Training complete in 86m 31s
Best val Acc: 0.983607
Process finished with exit code 0
"C:\Program Files\Python36\python.exe" E:/PycharmProjects/Two_Classifer/transfer_learning/Resnet18.py
Epoch 0/19
----------
train Loss: 0.8820 Acc: 0.5292
val Loss: 1.0538 Acc: 0.5000
Epoch 1/19
----------
train Loss: 0.8375 Acc: 0.4688
val Loss: 0.7579 Acc: 0.5000
Epoch 2/19
----------
train Loss: 0.8743 Acc: 0.4792
val Loss: 1.0728 Acc: 0.5000
Epoch 3/19
----------
train Loss: 0.9315 Acc: 0.5125
val Loss: 0.7233 Acc: 0.5000
Epoch 4/19
----------
train Loss: 0.8266 Acc: 0.4646
val Loss: 0.6914 Acc: 0.5000
Epoch 5/19
----------
train Loss: 0.7754 Acc: 0.5000
val Loss: 0.6860 Acc: 0.6148
Epoch 6/19
----------
train Loss: 0.7230 Acc: 0.5708
val Loss: 1.0753 Acc: 0.5000
Epoch 7/19
----------
train Loss: 0.6208 Acc: 0.6521
val Loss: 1.4363 Acc: 0.5000
Epoch 8/19
----------
train Loss: 0.5947 Acc: 0.6687
val Loss: 1.5106 Acc: 0.5000
Epoch 9/19
----------
train Loss: 0.5319 Acc: 0.7250
val Loss: 1.1239 Acc: 0.5000
Epoch 10/19
----------
train Loss: 0.5537 Acc: 0.7271
val Loss: 1.6192 Acc: 0.5000
Epoch 11/19
----------
train Loss: 0.5698 Acc: 0.6833
val Loss: 0.8167 Acc: 0.5902
Epoch 12/19
----------
train Loss: 0.5458 Acc: 0.7333
val Loss: 0.3677 Acc: 0.8033
Epoch 13/19
----------
train Loss: 0.5539 Acc: 0.7250
val Loss: 1.4953 Acc: 0.5000
Epoch 14/19
----------
train Loss: 0.5552 Acc: 0.7104
val Loss: 0.2276 Acc: 0.9590
Epoch 15/19
----------
train Loss: 0.5146 Acc: 0.7271
val Loss: 0.3536 Acc: 0.8689
Epoch 16/19
----------
train Loss: 0.5237 Acc: 0.7292
val Loss: 0.2213 Acc: 0.9590
Epoch 17/19
----------
train Loss: 0.5173 Acc: 0.7458
val Loss: 0.2517 Acc: 0.9508
Epoch 18/19
----------
train Loss: 0.4920 Acc: 0.7688
val Loss: 0.3298 Acc: 0.8934
Epoch 19/19
----------
train Loss: 0.5555 Acc: 0.7375
val Loss: 0.5069 Acc: 0.7541
Training complete in 80m 7s
Best val Acc: 0.959016
AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。专注AI技术发展与AI工程师成长的求知平台https://www.yanxishe.com/TextTranslation/1587?from=zhihu
比较两次的结果,不难发现,验证loss经常发生突然上升和下降,甚至最后一次的结果表现并不好
中间出现了很多验证只有50%的准确率情况
对于二分类问题常用的评价指标是精确率和召回率。通常以关注的类为正类,其他类为负类,分类器在数据集上的预测或者正确或者不正确,我们有4中情况,在混淆矩阵中表示如下:
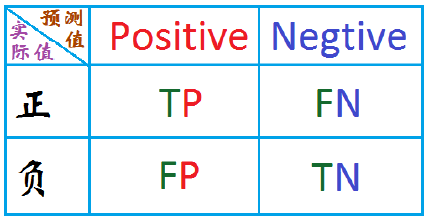
精确率 :P = TP / (TP + FP)
召回率: R = TP / (TP + FN)
F1: 精确率和召回率的调和平均。 即: 2/F1 = 1/P + 1/R
直观上来解释精确率和召回率。
精确率表示我现在有了这么的预测为正的样本,那么这些样本中有多少是真的为正呢?
召回率表示我现在预测为正的这些值中,占了所有的正的为正的样本的多大比例呢?

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)