【全网最详细yolov6】yoloV6调试记录(含训练自己的数据集及常见报错及解决方法)--持续更新ing
本文手把手教你如何调试最新的yolov6,复现运行COCO2017及训练自己的数据集,目前该项目刚发布,BUG会比较多,调起来一般不会那么顺利,本文含windows+ubuntu,并给出了一些常见问题和解决方法:目录1.项目简介2.注意和推荐3.项目配置(含COCO数据集配置)4.训练自己的数据:5.踩坑小记与解决方法:6.自己训练的尝试和tips(供大家参考)最近由美团发布了yoloV6,声称达
本文手把手教你如何调试最新的yolov6,复现运行COCO2017及训练自己的数据集,目前该项目刚发布,BUG会比较多,调起来一般不会那么顺利,本文含windows+ubuntu,并给出了一些常见问题和解决方法:
目录
1.项目简介
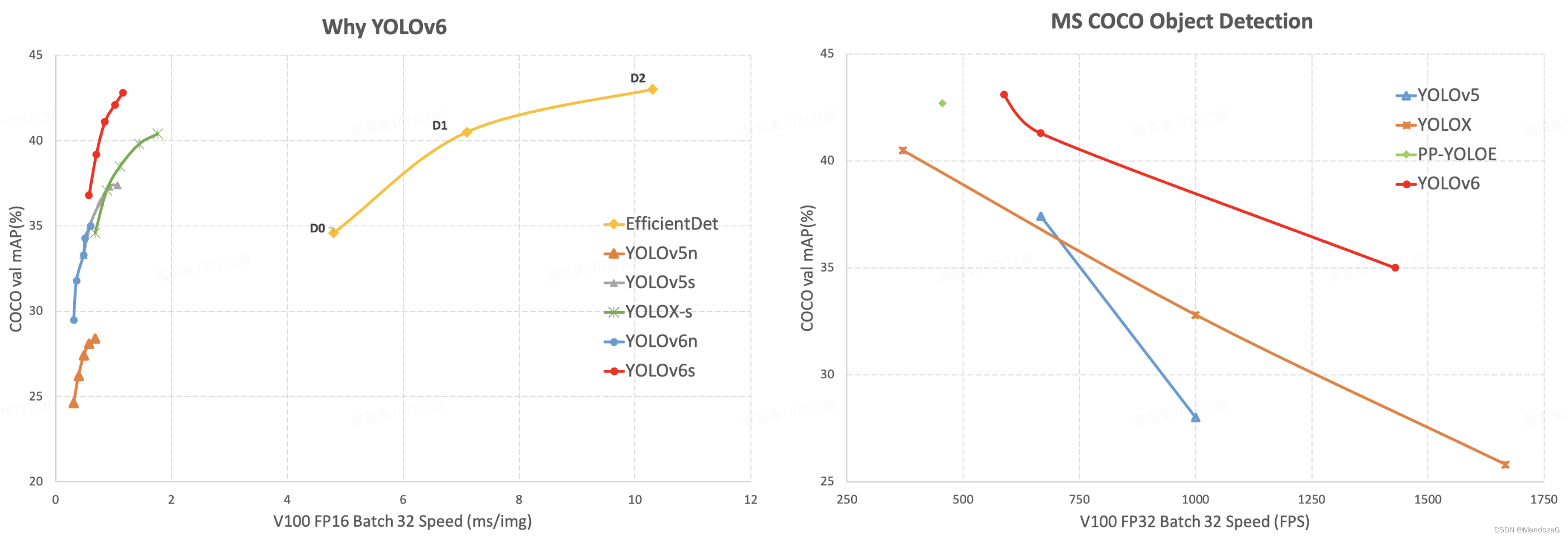
最近由美团发布了yoloV6,声称达到了如下的效果:

其中YOLOv6-nano在COCO val2017数据集上达到了35.0 mAP, YOLOv6-s在同样的数据集上达到了43.1 mAP。
目前由于工程是近期发布的,有一定的问题,而且GIthub中的说明也不是很详细,特此写一篇关于调试的文章。
---------------------------------------------------------------------------------------------------------
2.注意和推荐
由于该工程较新,bug还是非常多的,建议大家多去github上看看自己的issue是否有出现,这几天代码修改的也比较勤,大家尽量保持更新,会有bug fixed。现在更多的问题表现在训练自己的数据集上。
-------------------------------------------------------------------------------------------------------
写在最前面:
经过测试该工程不适合笔记本(测试电脑为r9000p 2021)及普通台式机,适合运行在性能较好的电脑或者服务器上,本文为windows上的配置,供大家参考学习!
2022 7.1更新服务器运行,新版本工程加入了end2end
----------------------------------------------------------------------------------------------------------
3.项目配置(含COCO数据集配置)
本部分是重现作者的效果,即在COCO上尝试运行该程序。
以下开始windows上的配置:
从requirement.txt可以看出该工程依赖于以下:

注意:请勿安装最新版本的torch(1.11.0)+torchvison(0.12)会出现问题!
我的成功运行的环境供大家参考:python 3.8.13 torchvision 0.11.1+cu113 torch 1.10.0+cu113 numpy 1.21.5 opencv-python 4.6.0.66 opencv-python-headless 4.5.5.64 addict 2.4.0 pyyaml 6.0 等等
此处省略安装torch配套的cuda和cudnn过程。
--------------------------------------------------------------------------------------------------------
说明:本调试完成与windows10+pycharm,但仍然强烈推荐在服务器(linux)上完成调试
首先第一步克隆工程
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt先加载一下预训练模型(测试):(下载地址)

先将这三个文件下载下来,放入weights文件夹(需要自行创建)下。
若要在pycharm中运行则需要,在其终端下的command Prompt而非windows的powershell,否则会报错(使用虚拟环境的话会找不到例如torch等库)

然后运行inference模型:
python tools/infer.py --weights yolov6s.pt
yolov6n.pt(此处可替换别的模型)imagedir保持默认即可,该路径存在 ,可选项如下:

可以看到测试推断结果:



看起来效果不错。
----------------------------------------------------------------------------------------------------
测试完毕后到训练阶段:
准备工作:下载COCO数据集(可能需要科学上网),并在yaml文件中更改相应路径
COCO - Common Objects in Context https://cocodataset.org/#home建议下载2017
https://cocodataset.org/#home建议下载2017

如果json格式的annotations没有成功转化并且报错说没有labels那么可以下载下面的转化好的laebls并放入labels文件夹下(文件夹结构如下图)
下载链接:https://pan.baidu.com/s/12AIzhR-4wWdFrsjW7RSX0g?pwd=8e2t
提取码:8e2t
在项目文件中创建data文件夹,布局如下:

images文件夹:

labels文件夹:

annotations文件夹:

按照此结构部署的COCO数据集coco.yaml应修改为:
# COCO 2017 dataset http://cocodataset.org
train: ./data/coco/images/train2017 # 118287 images
val: ./data/coco/images/val2017 # 5000 images
test: ./data/coco/images/test2017
anno_path: ./data/coco/annotations/instances_val2017.json
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]
至此COCO数据集部署完毕,在windows下训练还需要修改一处(否则会因为正反斜杠混用,报路径错误):
在yolov6->data->datasets.py中第184行:
label_dir = osp.join(osp.dirname(osp.dirname(img_dir)), 'labels', osp.basename(img_dir))
改为:
label_dir = osp.join(osp.dirname(osp.dirname(img_dir)), 'labels', osp.basename(img_dir)).replace('\\','/')接下来开始训练:
单个GPU:
python tools/train.py --batch 32 --conf configs/yolov6s.py --data data/coco.yaml --device 0
configs/yolov6s.py处可以更换models中的其他模型。
多个GPU(推荐使用DDP)
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 256 --conf configs/yolov6s.py --data data/coco.yaml --device 0,1,2,3,4,5,6,7评估:
重现该模型在COCO val2017的mAP
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val
装载:
性能测试:略,见github原地址。
Benchmark:

4.训练自己的数据:
本部分为新更新的部分,训练自己的数据集bug比较多,建议大家及时下载(更新)最新的代码。
本部分尝试分别在windows上和服务器上运行。
训练自己的数据集官方说明:
https://github.com/meituan/YOLOv6/blob/main/docs/Train_custom_data.mdhttps://github.com/meituan/YOLOv6/blob/main/docs/Train_custom_data.md首先就是准备数据集阶段,值得注意的是本项目使用的是YOLO格式的数据集,别的格式的数据集需要经过转换
label(txt)的样例
# class_id center_x center_y bbox_width bbox_height
0 0.300926 0.617063 0.601852 0.765873
1 0.575 0.319531 0.4 0.551562准备好的数据集需要这么放置:(test可选,注意必须按照图中形式放置)
custom_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ ├── val
│ │ ├── val0.jpg
│ │ └── val1.jpg
│ └── test
│ ├── test0.jpg
│ └── test1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
├── val
│ ├── val0.txt
│ └── val1.txt
└── test
├── test0.txt
└── test1.txt另外这里有个坑,数据集的名称推荐使用纯数字的(如000000,jpg 000000.txt经过测试没问题),如果有“.”等特殊符号会读取错误或者找不到labels。
data.yaml配置:
# 数据集路径
train: ../custom_dataset/images/train # train images
val: ../custom_dataset/images/val # val images
test: ../custom_dataset/images/test # test images (可选的)
# 是否是COCO格式的数据集,用YOLO的话设置为False即可
is_coco: False
# 类别
nc: 20 # 类的个数
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # 类名config文件:自己配置好放到configs文件夹下,默认我们使用提供的配置文件如configs文件夹下的:yolov6n_finetune.py
## YOLOv6s Model config file
model = dict(
type='YOLOv6s',
pretrained='./weights/yolov6s.pt', # download pretrain model from YOLOv6 github if use pretrained model
depth_multiple = 0.33,
width_multiple = 0.50,
...
)
solver=dict(
optim='SGD',
lr_scheduler='Cosine',
...
)
data_aug = dict(
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
...
)准备好了开始训练:
Train:
单个GPU:(根据设备情况设置batch、workers并选择data.yaml)
python tools/train.py --batch 16 --conf configs/yolov6s_finetune.py --data data/xxx.yaml --device 0 --workers x --epochs x多个GPU:(推荐)
python -m torch.distributed.launch --nproc_per_node 4 tools/train.py --batch 64 --conf configs/yolov6s_finetune.py --data data/xxx.yaml --device 0,1,2,3 --epochs x --workers 16上面多个方法有可能出现如下训练就卡住不动 (如何修改未知):
Using 4 GPU for training...
Initializing process group...
这时候可以尝试不推荐的指令:(即直接追加device)
python tools/train.py --batch 16 --conf configs/yolov6s_finetune.py --data data/xxx.yaml --device 0,1,2,3 --workers x --epochs xwindows下尝试跑了5个epochs(成功)

val:
Evaluation:
python tools/eval.py --data data/data.yaml --weights output_dir/name/weights/best_ckpt.pt --device 0Inference推断效果:(目前只能推断图片)
python tools/infer.py --weights output_dir/name/weights/best_ckpt.pt --source img.jpg --device 0结果默认指向data/images中的那三张图,这里需要替换为你的路径或将你的图片放入文件夹中
训练10个epochs推断结果:


Deployment:
1.输出为 ONNX 格式:
python deploy/ONNX/export_onnx.py --weights output_dir/name/weights/best_ckpt.pt --device 02.输出为OpenVINO格式:
python deploy/OpenVINO/export_openvino.py --weights output_dir/name/weights/best_ckpt.pt --device 0ubunbtu服务器:
这里的data.yaml中数据集的地址推荐设置为绝对路径,相对路径可能会找不到,配置依赖见前面windows配置,建议创建conda环境进行配置。
按照报错7(下文中常见报错7)的方式修改文件或者如果有linux pycharm等编译器的设置YOLOv6文源文件夹。
在terminal中(conda环境下的)输入与上面相同的指令进行训练即可。
目前BUG还是非常多的。欢迎讨论!
使用服务器跑了200个epochs(batchsize 128)

val
-------------------------------------------------------------------------------------------------------------------
5.踩坑小记与解决方法:
1.AttributeError: 'NoneType' object has no attribute '_free_weak_ref'
这是pytorch版本问题 我第一次已安装:torch1.11.0 torchvision 0.12.0不支持
解决办法:
第一步:卸载,打开conda环境,pip list查看安装的包 使用 pip uninstall torch torchvision 卸载
再进行:pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
(以上方法测试成功)
或pip install --upgrade --force-reinstall torch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0(强制重新安装)
2.RuntimeError: DataLoader worker (pid(s) 2244, 652) exited unexpectedly
原因多线程的使用造成内存不足,将workers调整至不会出错的数目,如若仍然报错,让workers为0即不使用多线程。
解决方法更改训练指令(添加 --workers x(x为能接受的数目,默认为8)):
python tools/train.py --batch 32 --conf configs/yolov6s.py --data data/coco.yaml --device 0 --workers 0 3.OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
这是因为你的环境中安装了多个libiomp5md.dll库,
解决办法:到你的环境搜索libiomp5md.dll删除多出来的库(仅保留一个)。
4.训练时使用GPU训练但出现 ------------CPU Mode for This Batch-------------
可以看到这里抛出了异常:OOM RuntimeError is raised due to the huge memory cost during label assignment. CPU mode is applied in this batch. If you want to avoid this issue,try to reduce the batch size or image size.
这是由于内存不够导致的,需要缩减Batch_size(但应当大于8)或者减小图片尺寸(若使用COCO数据集则不建议修改)使用torch.cuda.empty_cache()释放未占用缓存。
解决方法:缩小batch_size(如下改为16)
python tools/train.py --batch 16 --conf configs/yolov6s.py --data data/coco.yaml --device 0 5.RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
![]() 原因:显卡显存不够,调小batch_size或者降低workers即可。
原因:显卡显存不够,调小batch_size或者降低workers即可。
warning:UserWarning: torch.meshgrid: in an upcoming release, it will be requ
ired to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:2157.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
是因为:下个版本 VF.meshgrid(tensors, **kwargs) 改为修改为return _VF.meshgrid(tensors, **kwargs, indexing = ‘ij’)
解决方法:使用return _VF.meshgrid(tensors, **kwargs, indexing = ‘ij’) # type: ignore[attr-defined] 解除警告
此外由于对于性能要求比较高,从而会出现: “OSError: [WinError 1455]页面文件太小,无法完成操作”的问题,这是由于内存不足造成的

解决方法:增大虚拟内存或者更换更大的内存条。增大虚拟内存的方法这里就不在赘述了。
6.module没有xxx,一般是由于库的版本问题,调整到适合的版本即可。
7.在自己训练数据集时,找不到tools.xxx等module 例如AttributeError: module 'tools.eval' has no attribute 'run'
一般是项目目录设置错误,导致找不到,在windows端使用pycharm等编译器时将源目录设置为yolov6,若使用ubuntu直接通过terminal调用,因为读不到系统sys路径,所以会找不到。这里需要进行如下调整(解决方法之一):
在YOLOv6/tools/目录下创建__init__.py,并调整train.py的内容:
#原
ROOT = os.getcwd()
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT))
#替换为
ROOT = os.getcwd()
if str(ROOT) not in sys.path:
sys.path.insert(0,str(ROOT))8.COCOEval Error
验证时出错,是老版本bug,更新到新版即可。
9.路径xxx/mages(你设置的数据集相对路径)不存在
将data.yaml中的数据集路径设置为绝对路径。
10.多GPU训练,使用分布式(distributed)出现:No rendezvous handler for env://
检查是否自己是在windows中使用,windows不支持nccl,将torch的distributed_c10d.py中的backend = "nccl"改为backend = "gloo"
如是在ubuntu下运行,则更改tcp(附加):
--dist_url tcp://localhost:1001若都不能解决可以尝试上面的不推荐的方法运行。
python tools/train.py --batch 16 --conf configs/yolov6s_finetune.py --data data/xxx.yaml --device 0,1,2,3 --workers x --epochs x未解决的问题:(有小伙伴遇到了解决了欢迎留言!!!)
分布式训练卡在:
Using 4 GPU for training...
Initializing process group...
---------------------------------------------------------------------------------------------
6.自己训练的尝试和tips(供大家参考)
tips:因为该项目对于硬件要求较高,有时候会出现上述第四个的显卡“爆显存”的问题,使用下面的代码段(在cmd控制台中输入)来监控显卡状态并每秒更新。
nvidia-smi -l
(是l不是1,每秒显示一次)
可以看到我的3060laptop显卡也只有6G的显存,所以很容易就爆显存了。
供大家参考:
在我的r9000p 2021中GPU可跑动的train运行方式为:
python tools/train.py --batch 24 --conf configs/yolov6s.py --data data/coco.yaml --device 0 --workers 3
注:没有继续尝试了,batch_size 32会爆显存,worker 8(默认)会内存不足(已添加30G虚拟内存)。再微调batch和workers效果不大,每个epoch需要约50分钟,一共400个epoch,是不可接受的。还是在服务器上跑比较合适!

花两个小时跑两个epoch感受一下:
epoch 0:


epoch 1:

打开tensorboard:(指定路径到train文件夹下,而非命名的name,如exp文件夹下)
tensorboard ==logdir=xxx/runs/trainTensorBoard:(仅两个epoch,仅供参考)


-------------更新 5 epochs----------------
loss

mAP



----------------------------------------------------------------------------------------------
训练自己的数据集时(windows10个epochs,batch_size 16)
loss

val

验证:(Inference)


对比:yolov5 200epochs


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)