CS188 Project 2: Multi-agents吃豆人
CS188 Project 2: Multi-agentspacman用吃豆人表示,ghost用幽灵表示1. Question 2: Minimax题目描述:在multiAgents.py的MinimaxAgent中实现; minimax 代理必须可以处理任意数量的幽灵,所以对于每个最大层,最小最大树将有多个最小层(每个幽灵一个);在环境中运行的实际幽灵可能会部分随机地行动;要求:将博弈树扩展到任
CS188 Project 2: Multi-agents
pacman用吃豆人表示,ghost用幽灵表示
吃的是豆吗?吃的是我的心啊!!
1. Question 2: Minimax
题目描述:在multiAgents.py的MinimaxAgent中实现; minimax 代理必须可以处理任意数量的幽灵,所以对于每个最大层,最小最大树将有多个最小层(每个幽灵一个);在环境中运行的实际幽灵可能会部分随机地行动;
要求:将博弈树扩展到任意深度;重要提示:搜索的单个级别被认为是一个吃豆子移动和所有鬼魂的响应,因此深度 2 搜索将涉及吃豆子和每个鬼魂移动两次。评分:检查代码以确定它是否探索了正确数量的游戏状态。自动分级器会要求GameState.getNextState的调用次数。
解答:
由Minimax树的特性可知,遍历起点必定为吃豆人;
getgetLegalActions(agentIndex):agentIndex=0表示吃豆人,>=1表示幽灵,因为幽灵不止一个,此函数记录了大家的合法动作;getNextState()表示对每一个合法的动作生成对应的状态;
所以需要在所有合法动作中找出最优解,即进行minimax搜索遍历,对每一步幽灵取得的最小值中,选取最大的一个;
所以还需设计能使吃豆人取得最大值的getMax函数和幽灵让吃豆人取得最小利益的getMin函数:
getMax:如果到达叶节点或者无合法行为则返回,否则遍历计算所有幽灵的min值,记录其中的最大值;
getMin:如果到达叶节点或者无合法行为则返回,否则在吃豆人提供的最大值和其他幽灵的最小值中记录最小值。
那为什么吃豆人在游戏空间特别大的时候会冲向最近的幽灵呢?
因为当吃豆人发现它将不可避免地死亡时,它会尝试尽快结束游戏;其实这时假定幽灵出错会有一线生机但 Minimax智能体会毫不犹豫地"自杀",因为它是悲观的。
代码如下:
class MinimaxAgent(MultiAgentSearchAgent):
"""
Your minimax agent (question 2)
"""
def getAction(self, gameState):
"""
Returns the minimax action from the current gameState using self.depth
and self.evaluationFunction.
Here are some method calls that might be useful when implementing minimax.
gameState.getLegalActions(agentIndex):
Returns a list of legal actions for an agent
agentIndex=0 means Pacman, ghosts are >= 1
gameState.getNextState(agentIndex, action):
Returns the successor game state after an agent takes an action
gameState.getNumAgents():
Returns the total number of agents in the game
gameState.isWin():
Returns whether or not the game state is a winning state
gameState.isLose():
Returns whether or not the game state is a losing state
"""
"*** YOUR CODE HERE ***"
maxVal = -float('inf') # 初始化最大值为负无穷
bestAction = None # 初始化为空
for action in gameState.getLegalActions(0):
# 进行树遍历
value = self.getMin(gameState.getNextState(0, action), 0, 1)
# 取大值
if value > maxVal:
maxVal = value
bestAction = action
# 最后返回最优解
return bestAction
# 吃豆人得到max
def getMax(self, gameState, depth=0, agentIndex=0):
# 达到搜索深度
if depth == self.depth:
return self.evaluationFunction(gameState)
# 不合法
if len(gameState.getLegalActions(agentIndex)) == 0:
return self.evaluationFunction(gameState)
# 获得吃豆人的所有合法操作,并进行遍历
maxVal = -float('inf')
for action in gameState.getLegalActions(agentIndex):
# 计算幽灵
value = self.getMin(gameState.getNextState(agentIndex, action), depth, agentIndex + 1)
if value > maxVal:
maxVal = value
return maxVal
# 幽灵getmin
def getMin(self, gameState, depth=0, agentIndex=1):
# 达到搜索深度
if depth == self.depth:
return self.evaluationFunction(gameState)
# 不合法
if len(gameState.getLegalActions(agentIndex)) == 0:
return self.evaluationFunction(gameState)
# 获得当前鬼怪的所有合法操作,并进行遍历
minVal = float('inf')
for action in gameState.getLegalActions(agentIndex):
# 如果最后一个幽灵,那么接下来就要去计算吃豆人,否则就去计算下一个幽灵
if agentIndex == gameState.getNumAgents() - 1:
# 计算吃豆人
value = self.getMax(gameState.getNextState(agentIndex, action), depth + 1, 0)
else:
# 并没有计算完所有幽灵
value = self.getMin(gameState.getNextState(agentIndex, action), depth, agentIndex + 1)
if value < minVal:
minVal = value
return minVal
# util.raiseNotDefined()
2.Question 3: Alpha-Beta Pruning
题目描述:在minimax基础上进行Alpha-Beta剪枝以提高效率。
解答:
Alpha:最大下界 Beta:最小上界
所以剪枝操作在大于最大下界和小于最小上界时发生,根据提示可知,直接在minimax算法中将所得值与alpha、beta比较即可。
class AlphaBetaAgent(MultiAgentSearchAgent):
"""
Your minimax agent with alpha-beta pruning (question 3)
"""
def getAction(self, gameState):
"""
Returns the minimax action using self.depth and self.evaluationFunction
"""
"*** YOUR CODE HERE ***"
maxVal, bestAction = self.getMax(gameState)
return bestAction
def getMax(self, gameState, depth=0, agentIndex=0, alpha=-float('inf'), beta=float('inf')):
if depth == self.depth:
return self.evaluationFunction(gameState), None
if len(gameState.getLegalActions(agentIndex)) == 0:
return self.evaluationFunction(gameState), None
maxVal = -float('inf')
bestAction = None
for action in gameState.getLegalActions(agentIndex):
value = self.getMin(gameState.getNextState(agentIndex, action), depth, agentIndex + 1, alpha, beta)[0]
if value > maxVal:
maxVal = value
bestAction = action
# 剪枝操作
if value > beta:
return value, action
alpha = value if value > alpha else alpha
return maxVal, bestAction
def getMin(self, gameState, depth=0, agentIndex=1, alpha=-float('inf'), beta=float('inf')):
if depth == self.depth:
return self.evaluationFunction(gameState), None
if len(gameState.getLegalActions(agentIndex)) == 0:
return self.evaluationFunction(gameState), None
minVal = float('inf')
bestAction = None
for action in gameState.getLegalActions(agentIndex):
if agentIndex == gameState.getNumAgents() - 1:
value = self.getMax(gameState.getNextState(agentIndex, action), depth + 1, 0, alpha, beta)[0]
else:
value = \
self.getMin(gameState.getNextState(agentIndex, action), depth, agentIndex + 1, alpha, beta)[0]
if value < minVal:
minVal = value
bestAction = action
# 剪枝操作
if value < alpha:
return value, action
beta = value if value < beta else beta
return minVal, bestAction
3. Question 4 : Expectimax
题目分析:Minimax 和 alpha-beta 都假设对手永远做出最佳决策。所以本题就是在ExpectimaxAgent中假设幽灵的决策不是最优的,那此时则不可以用minimax树进行搜索,不是求幽灵决策的最小值,而是求决策的期望值;因为现在幽灵行动随机,各幽灵采取同一决策的概率相同,所以只需对其求平均即可。
解答:
它和minimax写法不同之处在于minimax的幽灵取最小值,而此时取平均。
class ExpectimaxAgent(MultiAgentSearchAgent):
"""
Your expectimax agent (question 4)
"""
INF = 100000.0
def getAction(self, gameState):
"""
Returns the expectimax action using self.depth and self.evaluationFunction
All ghosts should be modeled as choosing uniformly at random from their
legal moves.
"""
"*** YOUR CODE HERE ***"
maxValue = -self.INF
maxAction = Directions.STOP
for action in gameState.getLegalActions(agentIndex=0):
sucState = gameState.getNextState(action=action, agentIndex=0)
sucValue = self.getExp(sucState, currentDepth=0, agentIndex=1)
if sucValue > maxValue:
maxValue = sucValue
maxAction = action
return maxAction
#吃豆人
def getMax(self, gameState, currentDepth):
#如果达到搜索深度或者走向绝路就返回
if currentDepth == self.depth or gameState.isLose() or gameState.isWin():
return self.evaluationFunction(gameState)
maxValue = -self.INF
for action in gameState.getLegalActions(agentIndex=0):
sucState = gameState.getNextState(action=action, agentIndex=0)
sucValue = self.getExp(sucState, currentDepth=currentDepth, agentIndex=1)
if sucValue > maxValue:
maxValue = sucValue
return maxValue
#幽灵
def getExp(self, gameState, currentDepth, agentIndex):
if currentDepth == self.depth or gameState.isLose() or gameState.isWin():
return self.evaluationFunction(gameState)
numAction = len(gameState.getLegalActions(agentIndex=agentIndex))
totalValue = 0.0
numAgent = gameState.getNumAgents()
for action in gameState.getLegalActions(agentIndex=agentIndex):
sucState = gameState.getNextState(agentIndex=agentIndex, action=action)
if agentIndex == numAgent - 1:
sucValue = self.getMax(sucState, currentDepth=currentDepth + 1)
else:
sucValue = self.getExp(sucState, currentDepth=currentDepth, agentIndex=agentIndex + 1)
#这里把原来的取最小改成加和最后取平均即可
totalValue += sucValue
return totalValue / numAction
4.Question 5 : Evaluation Function
题目描述:在提供的函数中为吃豆人编写一个更好的评估函数betterEvaluationFunction。评估函数应该评估状态,而非动作;吃豆人获胜时的平均得分在 1000 分左右;
解答:
- 第一问的评价函数只考虑了①吃完豆②躲避幽灵③得高分,没有考虑吃掉大豆让幽灵恐慌然后反杀,所以本题关键是考虑大豆的作用以修正评价函数;
- 所以可以维护三个值:豆、幽灵、惊吓的幽灵对吃豆人决策的影响值;豆正反馈,幽灵负反馈,惊吓状态的幽灵正反馈,当然要注意惊吓时间,否则吃豆人冲向幽灵但幽灵恢复正常态则会死掉;
- 在基础得分的基础之上分别加上三种得分即为最后的评价值。
def betterEvaluationFunction(currentGameState):
"""
Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable
evaluation function (question 5).
"""
"*** YOUR CODE HERE ***"
#获取吃豆人的位置、豆子的位置和幽灵的状态
newPos = currentGameState.getPacmanPosition()
newFood = currentGameState.getFood()
newGhostStates = currentGameState.getGhostStates()
# 维护豆、幽灵、惊吓状态的幽灵三个值,以达到评价效果
INF = 100000000.0
WEIGHT_FOOD = 10.0 # 豆基础值
WEIGHT_GHOST = -10.0 # 幽灵基值
WEIGHT_SCARED_GHOST = 100.0 # 惊吓状态的幽灵基础值
# 当然所有得分建立在基础分的基础上
score = currentGameState.getScore()
#计算最近的豆的影响
distancesToFoodList = [util.manhattanDistance(newPos, foodPos) for foodPos in newFood.asList()]
if len(distancesToFoodList) > 0:
score += WEIGHT_FOOD / min(distancesToFoodList)
else:
score += WEIGHT_FOOD
# 评价幽灵的影响
for ghost in newGhostStates:
distance = manhattanDistance(newPos, ghost.getPosition())
if distance > 0:
#分正常状态和惊吓状态
#这里要考虑惊吓剩余时间
if ghost.scaredTimer > 0: #如果幽灵属于惊吓状态(可以吃掉幽灵)则增加权重
score += WEIGHT_SCARED_GHOST / distance
else:
score += WEIGHT_GHOST / distance
else:
return -INF #吃豆人死掉了
return score
5.运行结果

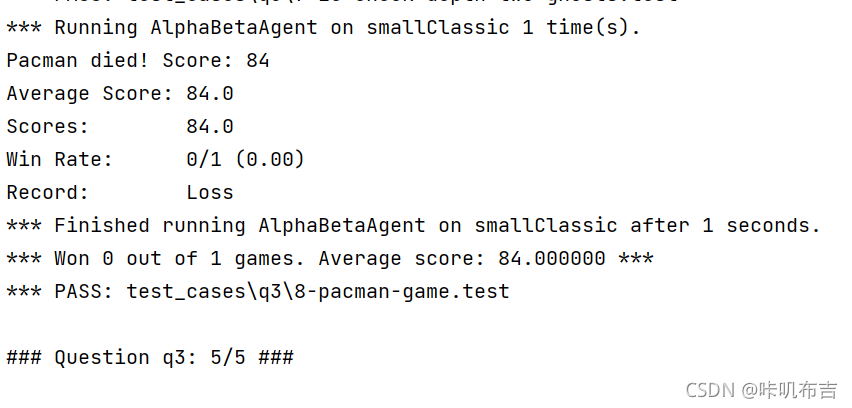

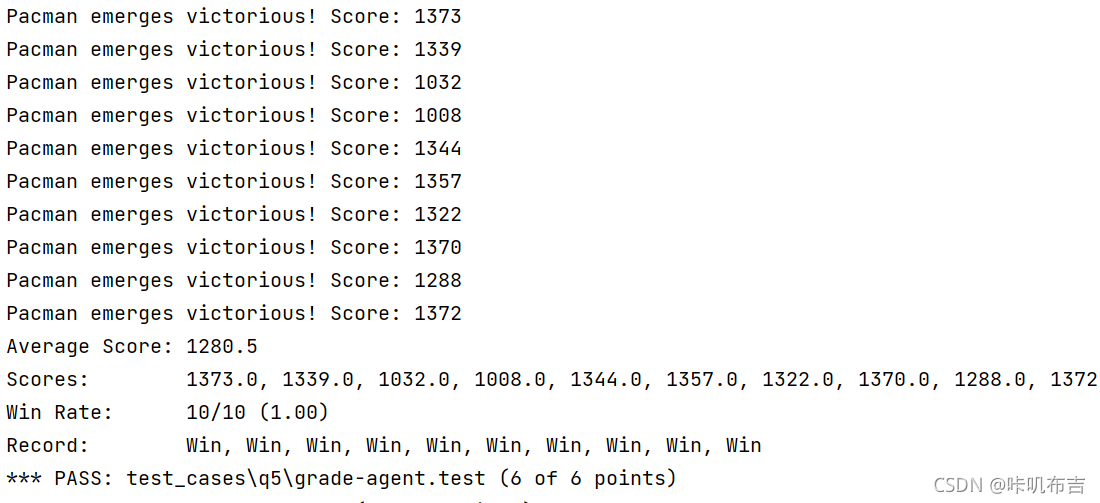
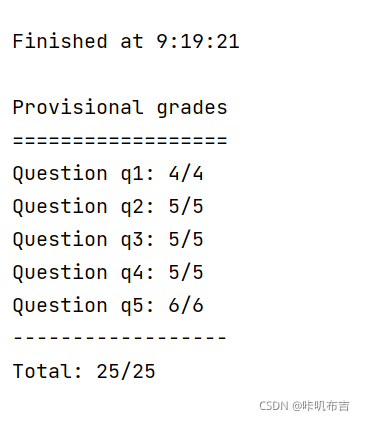
6.总结
Alpha-Beta 剪枝能在与Minimax 得出同样结果情况下大大减少需要展开的结点数,提高搜索效率,但是两者都假设了对面总做出最好的选择,因此限制了自己所能采取的步骤,最后在某些情况下悲观赴死以维护高分。而Expectimax 能比较好地处理幽灵不总是能做出最优决策的情况,但是相比Alpha-Beta 剪枝所消耗的资源就多了些。除了智能体本身的设计外,评价函数对智能体的表现起了至关重要的作用,设计评价函数时要考虑“趋利避害”之间的平衡,什么是好的,要如何做。
首先对于我来讲,上手就是一件很难的事情,从分析理解题目,到看代码,这个过程就极度痛苦,最后写代码,找资料,这是个痛苦的过程也是个历练身心的过程。因为看着吃豆人由最开始的随机乱动,到后来可以吃豆子、躲避幽灵,再根据minimax算法实现决策,能很好地表现,虽然悲剧的根深植其中;alpha-beta剪枝让它能更快做出决策,Expectimax改变它的悲剧性,由假定幽灵能做出最好决策到知晓幽灵可以出错,算法的完善让吃豆人成长,也让我感受颇深。
老师一直强调人工智能能教会我们什么,我想,它人工智能是把人的智慧、思维、决策过程具化形式化成了具体可见的算法,学习实现算法的过程也是自我感知看见自己的过程,它让我们以旁观者的角度观看自己,你的心性、你的格局,都在算法的每一步,决策的每一种可能中体现。改善算法,也是改变自己。
放张我男朋友压压惊



为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)