利用python批量下载NOAA历史气候数据
本文利用python批量下载NOAA的历史气象数据,需要用到的库如下:import refrom bs4 import BeautifulSoupimport urllib.requestimport ssl第一步,进入NOAA下载网站,NOAA历史气象数据下载链接:https://www1.ncdc.noaa.gov/pub/data/paleo/;第二步,选择所需要的数据,本文下载亚洲区域的树
·
本文利用python批量下载NOAA的历史气象数据,需要用到的库如下:
import re
from bs4 import BeautifulSoup
import urllib.request
import ssl第一步,进入NOAA下载网站,NOAA历史气象数据下载链接:https://www1.ncdc.noaa.gov/pub/data/paleo/;
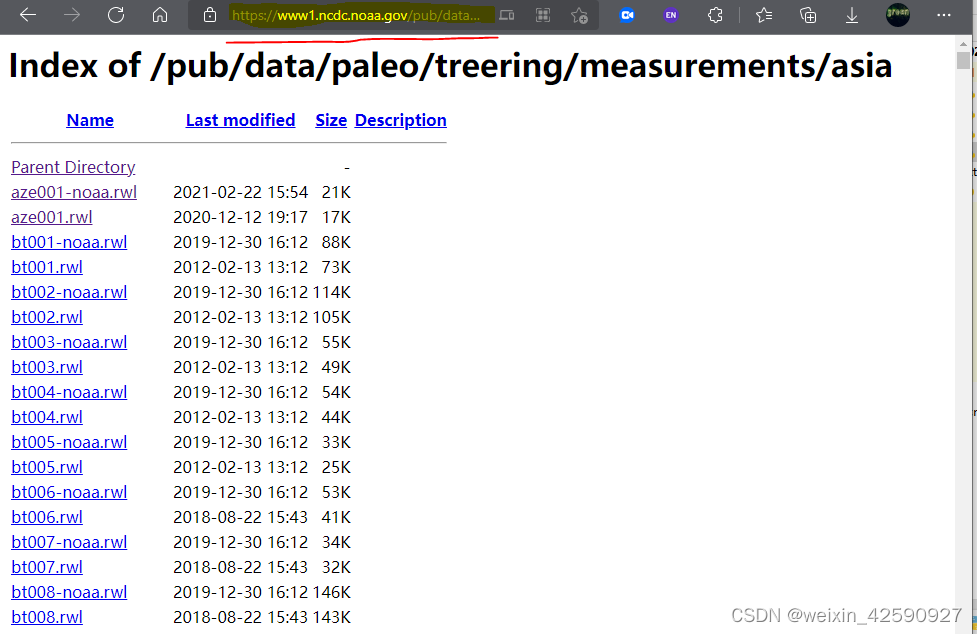
第二步,选择所需要的数据,本文下载亚洲区域的树轮原始测量数据,复制所需批量下载数据的网页链接;
第三步,请求获取链接响应,并以ASCII编码方式读取该链接的响应文件;
my_url = urlib.request.urlopen().read().decode(‘ascii’)第四步,使用Bs4解析所获取的响应文件;
soup =BeautifulSoup(my_url, ‘lxml’)第五步,查看网页源代码,搜寻网页源代码中所需的信息,例如本文需要获取所有的.rwl文件的超链接,做如下搜寻:
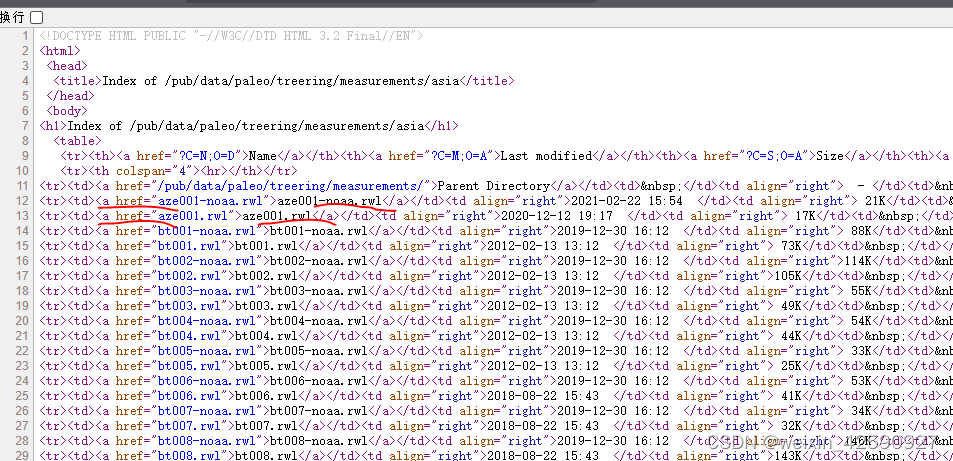
url_list = soup.find_all(herf=re.compile(“.rwl”))第六步,创建数组存储第五步所获取的所有超链接;
urls = []
For i in url_list[1:]
urls.append(‘访问的网站链接’ +i.get('href'))
第七步,将链接内容下载至本地,并存储在指定文件夹(注意:存储路径末尾以 / 结尾,否则下载文件会存储到上一级目录) ;
for i, url in enumerate(urls):
file_name="存储路径"+url.split('/')[-1]
urllib.request.urlretrieve(url, file_name)
附上本文下载所有亚洲地区树轮观测数据的全部代码:
# -*- coding:utf-8 -*-
# this file is used to download tree_ring data massively from NOAA for paleoclimate
# 2022-03-06
# author: ming
# using BeautifulSoup
import re
from bs4 import BeautifulSoup
import urllib.request
import ssl
TR_url = 'https://www1.ncdc.noaa.gov/pub/data/paleo/treering/measurements/asia/'
my_url = urllib.request.urlopen(TR_url).read().decode('ascii')
soup = BeautifulSoup(my_url,'lxml')
url_list=soup.find_all(href=re.compile(".rwl"))
print('step1 has fininshed!')
urls=[]
for i in url_list[1:]:
urls.append('https://www1.ncdc.noaa.gov/pub/data/paleo/treering/measurements/asia/'+i.get('href'))
print ('step2 has finished!')
for i, url in enumerate(urls):
file_name = "D:\my_data\climate_factor_data\ASM_domain/tree_ring\Asia_all_NOAA/"+url.split('/')[-1]
urllib.request.urlretrieve(url, file_name)
print ('congratulations! you got them all!')
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)