yolov5训练常见错误解决办法
Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.OMP原因:使用pip install torch-1.9.0+cu111-cp38-cp38-win_amd64.whl安装的pytorch框架anaconda下面多个虚拟环境下都有这个dll文件,要么都删掉,只保留一个,要么用另一种方法:见下面解决
Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.OMP
原因:使用pip install torch-1.9.0+cu111-cp38-cp38-win_amd64.whl安装的pytorch框架
anaconda下面多个虚拟环境下都有这个dll文件,要么都删掉,只保留一个,要么用另一种方法:见下面
解决办法:进入anaconda安装文件夹,搜索libiomp5md.dll,以我的环境为例,出现多个这个文件,在不同的文件夹下,但是当前运行程序环境下的这个文件肯定是两个。经过对比,发现没有安装torch的虚拟环境里面是图片1:C:\ProgramData\Anaconda3\envs\Deep-Learning-master\Lib\site-packages\torch\lib,安装了torch的虚拟环境的两个位置有这个文件:图片2:C:\ProgramData\Anaconda3\envs\yolov5-master\Lib\site-packages\torch\lib和图片3:C:\ProgramData\Anaconda3\envs\yolov5-master\Library\bin
所以我删除了C:\ProgramData\Anaconda3\envs\yolov5-master\Library\bin中的libiomp5md.dll
成功解决
另一种方法:
train.py 里面 在一大箩的导入语句后面添加
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
不要在原有的import os后面添加语句,程序会报错
而且在项目中基本上含有import os的都要添加这个语句(只是猜测,你们可以试试)因为我只加了一个文件的时候还是会报错
原文链接:https://blog.csdn.net/LHX19971114/article/details/121310528
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 2.00 GiB total capacity; 1.15
网络上常用的三种方法
方法一:
仅需减小batchsize
改文件的配置cfg的batchsize=1,一般在cfg文件下的查找batch或batchsize,将batchsize调小后,再次运行,类似于改下面

方法二 :
上述方法还没解决,不改batchsize,可以考虑下面的方法的链接
不计算梯度:
ps: 在报错的哪一行代码的上面,加上下面一行代码,不计算梯度
with torch.no_grad()
不计算梯度的方法
方法三:
释放内存:链接如下
释放内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
ps: 在报错的那一行代码的上面,加上下面两行代码,释放无关的内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
方法四:我的解决方案
我没用上面的方法,最主要是我是新手不知道在哪改,所以在看了好多网上的解决方案后,试了一下这种方法,可以训练了,成功解决GPU内存不足的问题
解决方法:将img-size调小

我把原本的[640,640]改为上图所示,成功解决问题
原文链接:https://blog.csdn.net/javahaoge/article/details/122890247
yaml文件中 命令后面要加空格:
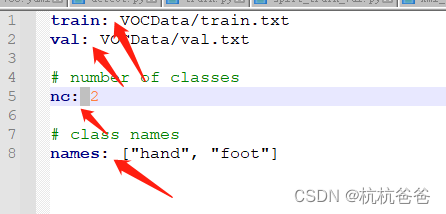
weights/yolov5m.pt 这种pt文件要用官方带的,复制粘贴过来改名子即可。
\VOCData\labels 里面的txt要有内容才是正常的
txt2yolo_label.py 里面的classes = ['hand', 'foot'] 标签集合也要改改
zero-size array to reduction operation maximum which has no identity :
txt2yolo_label.py 里面的classes = ['hand', 'foot'] 标签集合也要改改,基本就是各文件classes的值都不统一
TensorBoard: Start with ‘tensorboard --logdir runs\train’, view at http://localhost:6006/ 如何访问
#解决无法显示的问题
#(直接在PyCharm下面的 Terminal 进入输入命令就可以了)
#第一步:进入训练目录
cd C:\Users\lare\Desktop\pythoncode\BaiduSyncdisk\yolov5-master\runs\train
#第二步:设置生成这种文件的目录(events.out.tfevents.1634282239.xxxxxx.7676.0),一般都在训练目录的下一个目录
tensorboard --logdir=exp几几
#第三步:直接用浏览器打开生成的网址就可以了

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)