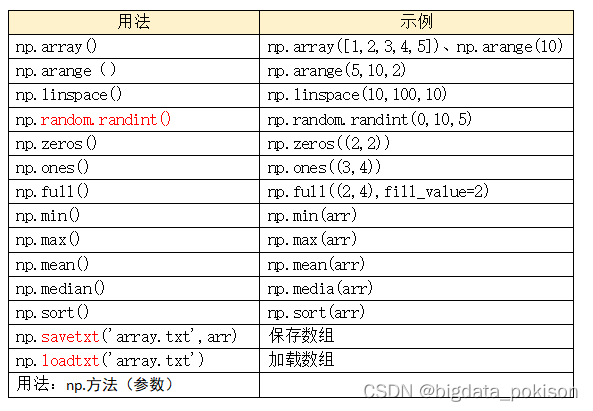
Numpy常用的20个函数
Numpy常用的20个函数
一、创建数组
1、array :它用于创建一维或多维数组 (array 数组)
import numpy as np
np.array([1,2,3,4,5])
----------------
array([1, 2, 3, 4, 5, 6])
还可以使用此函数将pandas的df转为NumPy数组。
data={'小写':['a','b','c'],'大写':['A','B','C']}
df=pd.DataFrame(data)
np.array(df)
2、arange :在给定的间隔内 返回具有一定步长的整数。 (arange 排列)
step:数值步长。
np.arange(5,10,2)
-----------------------
array([5, 7, 9])
3、Linspace :创建一个具有指定间隔的浮点数 的数组。 (lin-space 林空间)
start:起始数字 end:结束 Num:要生成的样本数
np.linspace(10,100,10)
--------------------------------
array([ 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])
4、random.randint :在一个范围内生成n个随机整数样本。 必记(random.rand-int)
(start:起始数字 end:结束 Num:要生成的样本数)
(1)np.random.randint(0,10,5)
------------------------------
[8, 6, 3, 2, 0]
(2)np.random.randint(4, 9, size=(3, 5)) 生成一个三行五列的正数矩阵
------------------------------
array([[5, 7, 7, 4, 4],
[4, 6, 7, 8, 4],
[5, 7, 6, 7, 7]])
5、zeros :np.zeros会创建一个全部为0的数组。 (zero + s)
shape:阵列的形状。
(1)np.zeros((2,3),dtype='int')
---------------
array([[0, 0, 0],
[0, 0, 0]])
(2)np.zeros(5)
-----------------
array([0., 0., 0., 0., 0.])
6、ones :np.ones函数创建一个全部为1的数组。 (one + s)
np.ones((3,4))
------------------
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
7、full :创建一个单独值的n维数组。fill_value:填充值。
np.full((2,4),fill_value=2)
--------------
array([[2, 2, 2, 2],
[2, 2, 2, 2]])
二、数组操作
8、min :返回数组中的最小值。
axis:用于操作的轴。 out:用于存储输出的数组。
arr = np.array([1,1,2,3,3,4,5,6,6,2])
np.min(arr)
----------------
1
9、max :返回数组中的最大值。
np.max(arr)
------------------
6
10、mean :返回数组的平均数
np.mean(arr,dtype='int')
-------------------------------
3
11、medain :返回数组的中位数。
arr = np.array([[1,2,3],[5,8,4]])
np.median(arr)
-----------------------------
3.5
12、sort :对数组排序。
kind:要使用的排序算法。 {'quicksort', 'mergesort', 'heapsort', 'stable'}
arr = np.array([2,3,1,7,4,5])
np.sort(arr)
----------------
array([1, 2, 3, 4, 5, 7])
13、abs :返回数组中元素的绝对值。当数组中包含负数时,它很有用。
A = np.array([[1,-3,4],[-2,-4,3]])
np.abs(A)
---------------
array([[1, 3, 4],
[2, 4, 3]])
14、合并 :Union1d函数将两个数组合并为一个。
a = np.array([1, 2, 3, 4, 5])
b = np.array([1, 3, 5, 4, 36])
np.union1d(a,b)
-------------------
array([ 1, 2, 3, 4, 5, 36])
15、重复的元素
np.repeat('2017',3)
---------------------
array(['2017', '2017', '2017'])
16、unique :返回一个所有唯一元素排序的数组。
return_index:如果为True,返回数组的索引。
return_inverse:如果为True,返回唯一数组的下标。
return_counts:如果为True,返回数组中每个唯一元素出现的次数。
axis:要操作的轴。默认情况下,数组被认为是扁平的。
np.unique(arr,return_counts=True)
---------------------
(
array([1, 2, 3, 4, 5, 6]), ## Unique elements
array([2, 2, 2, 1, 1, 2], dtype=int64) ## Count
)
三、保存和加载数据 (savetxt 、 loadtxt)
17、保存 :savetxt 用于在文本文件中保存数组的内容。
arr = np.linspace(10,100,500).reshape(25,20)
np.savetxt('array.txt',arr)
18、加载 :loadtxt用于从文本文件加载数组,它以文件名作为参数。
np.loadtxt('array.txt')
四、切片、索引
19、切片 (与python的切片语法相同:左闭右开)
a = np.arange(10)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = a[2:] # 从索引 2 开始到结束
c = a[2:7] # [2,7)之间的元素
d = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
20、高维切片 ( ...用来表示高维情况下,选中该维度的所有数据,并与其他维度选取结果取交集)
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
print (a[...,1]) # 第2列元素
print (a[1,...]) # 第2行元素
print (a[...,1:]) # 第2列及剩下的所有元素
# 切片 ":" 或 "..." 与索引数组组合
b = a[1:3, 1:3] # 位于第2,3行且第2,3列部分的元素
21、索引
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
b = a[5]
#输出: 5 (获取数组中第6个位置的元素)
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]] # 索引结果1维
y
#输出: [1 4 5] (获取数组中(0,0),(1,1)和(2,0)位置处的元素)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)