Yolov5如何在训练意外中断后接续训练
Yolov5如何在训练意外中断后接续训练配置环境问题描述调参结果修改num_workers结论附录配置环境操作系统:Ubuntu20.04CUDA版本:11.4Pytorch版本:1.9.0TorchVision版本:0.7.0IDE:PyCharm硬件:RTX2070S*2问题描述在训练YOLOv4tiny时发现GPU占用率非常低,并且经常跳到0,导致训练速度很慢为此博主对几个时间点就行设置,打
1.配置环境
操作系统:Ubuntu20.04
CUDA版本:11.4
Pytorch版本:1.9.0
TorchVision版本:0.7.0
IDE:PyCharm
硬件:RTX2070S*2

2.问题描述
在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python、主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时停下是十分崩溃了,好在博主摸索到在yolov5中接续训练的方法了。
3.解决方法
首先直接上方法
3.1设置需要接续训练的结果
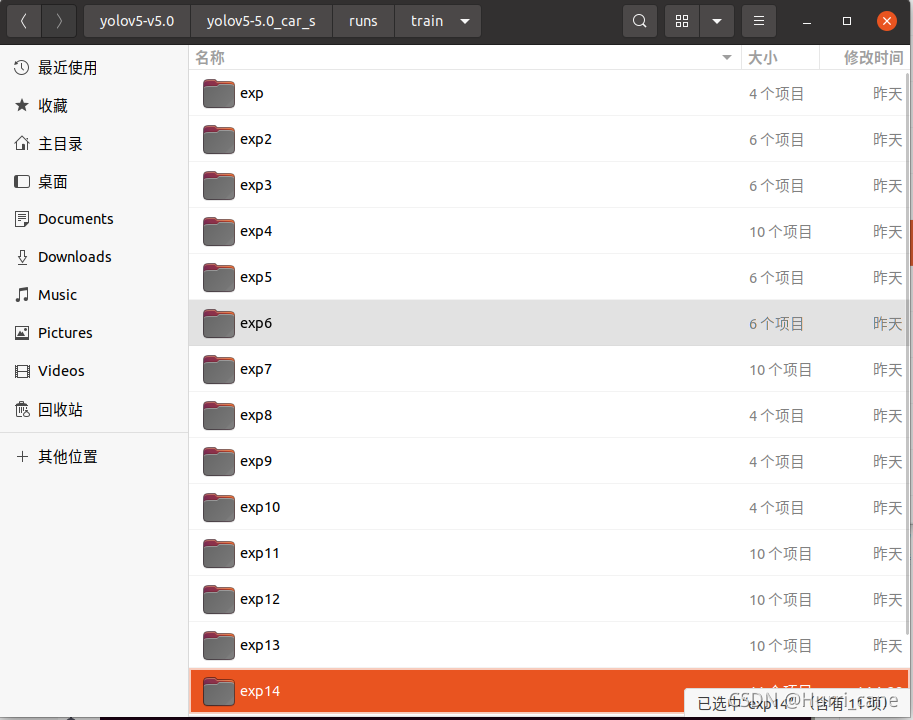
如果你想从上一次训练结果中回复训练,那么首先保证你的训练结果(一般都存放在/runs/train目录下)在保存目录中代号为最大的。

如上图所示,在train文件夹下一共有14个训练结果,假设我的第12次训练中断了,想接着第12次的结果继续训练,那么只需要将比12更大的:exp13、exp14这两个文件夹删除或者移动到其他地方,这样便设置好了需要接续训练的结果。
3.2设置训练代码
代码见yolov5代码中的train.py
if __name__ == '__main__':
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='../weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/car.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
注意上面patser中第9个参数resume,将其设置为default=True即可,也就是那一行代码改变为
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')
接下来运行python train.py边不会产生新的exp而是在最新的exp上接续训练
如下图所示:

博主运行完python train.py后便是接着上一次训练完139个epoch继续训练
4.原理
其实接续训练不是什么深奥内容 ,博主在训练自己模型的时候也早会使用。
我们在使用yolov5提供的权重,也就是像yolov5s.pt之类的文件时就是使用了官方提供的模型接续训练的。

我们每次训练模型时都会生成新的模型结果,存放在/runs/train/expxxx/weights下,接续训练就是将上次训练一半得到的结果拿来和模型结合进行训练。具体来说:如果最终训练目标是300个epoch,上次训练完了139个epoch,那么就是将第139个epoch得到的权重载入到模型中再训练161个epoch便可等效为训练了300个epoch
5.结束语
如果本文对你有帮助的话还请点赞、收藏一键带走哦,你的支持是我最大的动力!(づ。◕ᴗᴗ◕。)づ


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 97
97 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)