YOLOV3论文阅读(学习笔记)
cv小白的yolov3学习笔记总结论文下载地址:YOLOv3: An Incremental Improvementyolov网址:https://pjreddie.com/darknet/yolo/yolov3是yolov系列的第三个版本,yolov1和yolov2分别发表在2016和2017年的CVPR上。yolo系列算法是基于深度学习和卷积神经网络的单阶段通用目标检测算法,把目标检测问题转化
cv小白的yolov3学习笔记总结
论文下载地址:YOLOv3: An Incremental Improvement
yolov网址:https://pjreddie.com/darknet/yolo/
yolov3是yolov系列的第三个版本,yolov1和yolov2分别发表在2016和2017年的CVPR上。yolo系列算法是基于深度学习和卷积神经网络的单阶段通用目标检测算法,把目标检测问题转化为回归问题,不需要经过提取候选框的冗余问题。
一、摘要(Abstract)部分原文:
yolov3网络体积比yolov2网络更大,更深,但是准确度更高。在320×320的输入图像尺寸下,yolov3能够达到28.2的mAP,运算一张图片,前项推断需要22ms,和SSD一样准确,但是比SSD快三倍。yolov3在以0.5为IOU阈值时的mAP是比较好的。在Titan X环境下,yolov3的检测精度为57.9AP50,用时51ms;而RetinaNet的精度只有57.5AP500,但却需要198ms,yolov3比RetinaNet快3.8倍。
摘要部分解析:
mAP:Mean Average Precision ,即均值平均精度。作为 object dection 中衡量检测精度的指标。
如论文中的图3所示,作者将yolov3折线画在了第二象限,以表明在相同GPU条件下,以0.5为IOU阈值时yolov3比RetinaNet效果要好
横轴是运算时间,越靠左越快;
纵轴是以0.5为IOU阈值时的mAP,折线在图中越靠上则越准确
下图Figure3表明了速度和精度的权衡,速度就是运算时间,精度就是以0.5为IOU阈值时的mAP
蓝色折线是以RetinaNet-50为骨干网络的RetinaNet,橙色折线是以RetinaNet-101为骨干网络的RetinaNet
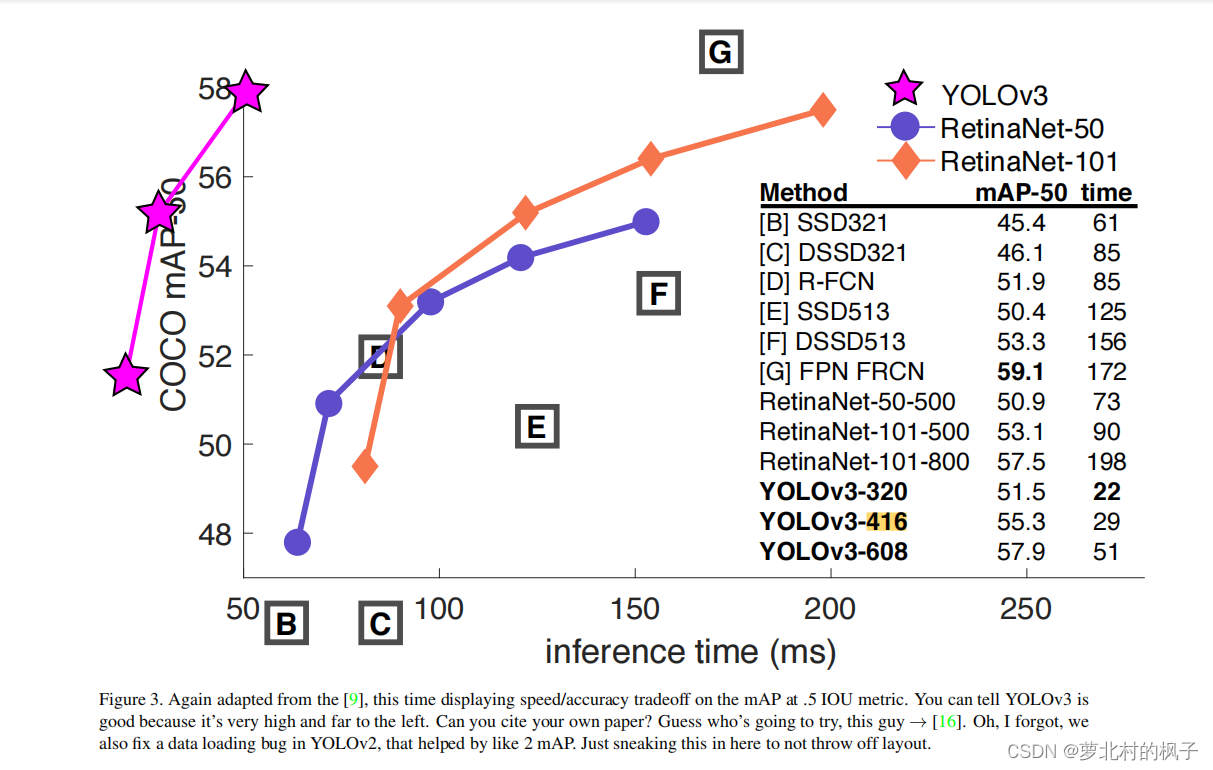
图表右下方的YOLOv3-320、YOLOv3-416、YOLOv3-608指的是输入图像的尺寸,yolov3和yolov2一样是全卷积网络,因此可以输入任意大小的图像,但是这些图像都必须是32倍数的(320,416,608都是32的倍数)。如果权重一样,不同大小的输入图像会输出不同的结果。
下面再来看论文中的Figure1,这张图是yolov3在以0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95为IOU阈值时,分别算出的mAP求平均值。
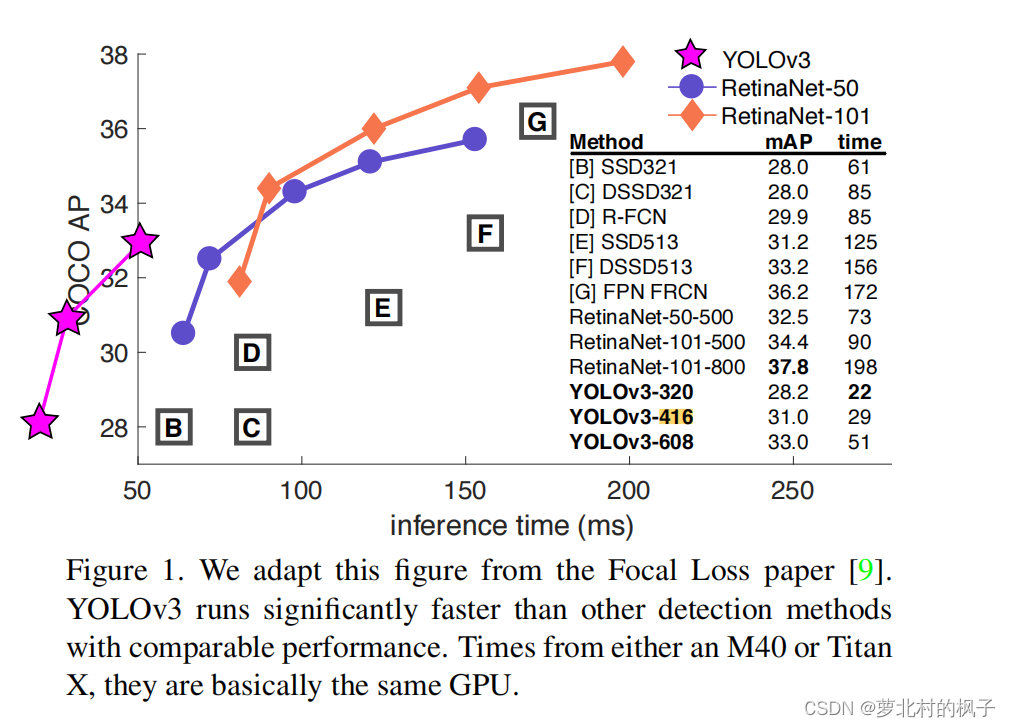
我们可以看到,在相同GPU情况下,与上面图3以0.5为IOU阈值时相比,Figure1中yolov3精度虽然有所下降,但是仍然在RetinaNet左上方,还是比RetinaNet效果要好。这也印证了作者在Abstract中写到的:When we look at the old .5 IOU mAP detection metric YOLOv3 is quite good.
即yolov3在高IOU阈值时的表现没有在低IOU阈值条件下的表现好。
二、边框预测(Bounding Box Prediction)
1.第一段原文:
在yolov9000(即yolov2)这个版本中,我们对数据集进行了聚类,把聚类中心作为anchor;每个预测框会预测出四个和坐标相关的值(tx、ty、tw、th,通过这四个值可以推算出预测框中心点的横纵坐标,预测框的宽度和高度)。每个grid cell相对于图像左上角偏移了(cx,cy),并且anchor的高度是pw和ph
边框预测第一段解析:
anchor:已经设置好长宽比的固定预测框;比如识别电线杆就会用高瘦的框,识别狗就会用低矮的框;并且通过下面的公式,我们就可以根据四个值(tx、ty、tw、th)来计算出预测框的中心点位置和框的宽高
σ函数:将预测框中心点位置限制在grid cell内部,如下下方论文中Figure2所示
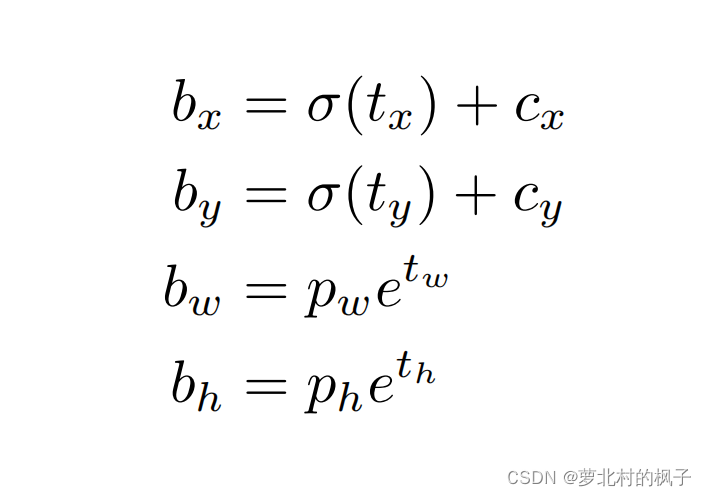
bx:预测框中心点x
by:预测框中心点y
bw:预测框宽度
bh:预测框高度
cx:所处的grid cell相较于全图左上角的偏移量cx
cy:所处的grid cell相较于全图左上角的偏移量cy
pw:anchor的宽度
ph:anchor的高度
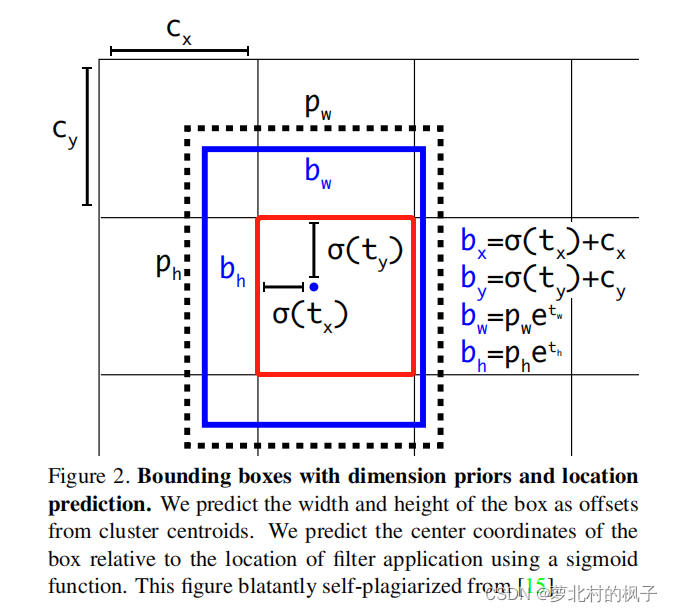
yolov把整张图像画成若干个网格的grid cell,每个grid cell的长宽归一化为1,简单来说,每个grid cell是边长为1的正方形
如论文中Figure2所示:
用红色框框起来的grid cell的cx为1,cy为1
2.2多类别标注分类(Class Prediction)
原文:
在yolov3中每一个预测框会输出输出85个值,其中的5个是中心点坐标,宽高,置信度,还有80个是条件类别概率。每一个类别,单独用一个二分类输出0到1之间的概率,也就说,可能会有多个类别的概率都是1,标签值为1,预测值为1。我们并不使用softmax因为我们发现它表现并不好,我们用各类别独立的逻辑回归。在训练过程中,每个类别单独用二分类交叉熵损失函数来训练。
这种方式帮助我们在更加复杂的任务领域,例如谷歌的Open Image数据集,在这个数据集中,一个预测框可以同时存在多个标签(例如同时存在女性和人这两个标签)。但是softmax会有假设各个类别的标签是互斥的,使用多标签的方式能够更好的给数据建模
笔记:每个预测框的每个类别可以逐一的用逻辑回归输出二分类概率,可以有多个类别输出高概率
2.3多尺度目标检测(Predictions Across Scales,网络拓扑结构)
原文:
yolov3在3个尺度上进行预测。我们的系统受到feature pyramid networks(FPN特征金字塔)的启发,从特征提取的骨干网络可以延伸出三条路,即不同尺度的特征分别加不同尺度的卷积层,每一个尺度获得一个三维的feature map,每一个feature map都有255个通道。在我们yolov3的实验中用的是COCO数据集,有80个类别,每一个尺度的grid cell都产生3个anchor,每一个尺度的输出结果都是N×N×[3×(4+1+80)],此输出结果经过sigmod等函数进行处理后作为4个坐标偏移量
笔记:
三条路:即输入任意尺度的三通道(RGB)的图像,经过yolov3之后,输出三种不同尺度的feature map(特征图)
255个通道:每一个grid cell有三个anchor(预测框),每一个anchor有80+5=85个值,3×85=255,所以一个feature map有255个通道
N×N×[3×(4+1+80)]:
N×N:该尺度下的grid cell个数
3:每一个grid cell生成3个anchor(预测框)
4:中心点坐标、宽、高
1:置信度
80:80个类别的条件类别概率
对比:
yolov1:输入的是448×448的三通道图像,每一张图像划分为7×7=49个grid cell,每个grid cell生成2个big bounding box(没有anchor),即产生98个框;输出的feature map结构是7×7×(5×2+20)
yolov2:输入的是416×416的三通道图像,每一张图像划分为13×13=169个grid cell,每一个grid cell生成5个anchor,即产生845个框;输出的feature map结构是13×13×(5+20)
5=4+1:中心点坐标、宽、高,置信度
20:20个类别的条件类别概率
从yolov2开始,兼容了不同输入尺寸的图片,输出尺寸由输入尺寸决定,小图片生成的feature map就小,大图片生成的feature map就大,如果输入正好是416×416,输出就是13×13的feature map
yolov3:如果输入的是416×416的三通道图像,yolov3会产生三个尺度:13×13、26×26、52×52,也对应着grid cell个数。对于每一个grid cell,产生3×(5+80)个张量。
即总共产生13×13+26×26+52×52个grid cell,(13×13+26×26+52×52)×3=10647个预测框
5=4+1:中心点坐标、宽、高,置信度
80:80个类别的条件类别概率
如果输入的是256×256的三通道图像,yolov3会产生三个尺度:8×8、16×16、32×32,每一个grid cell产生3个anchor,总共产生(8×8+16×16+32×32)×3=4032个预测框
13×13预测大物体、26×26预测中物体、52×52预测小物体
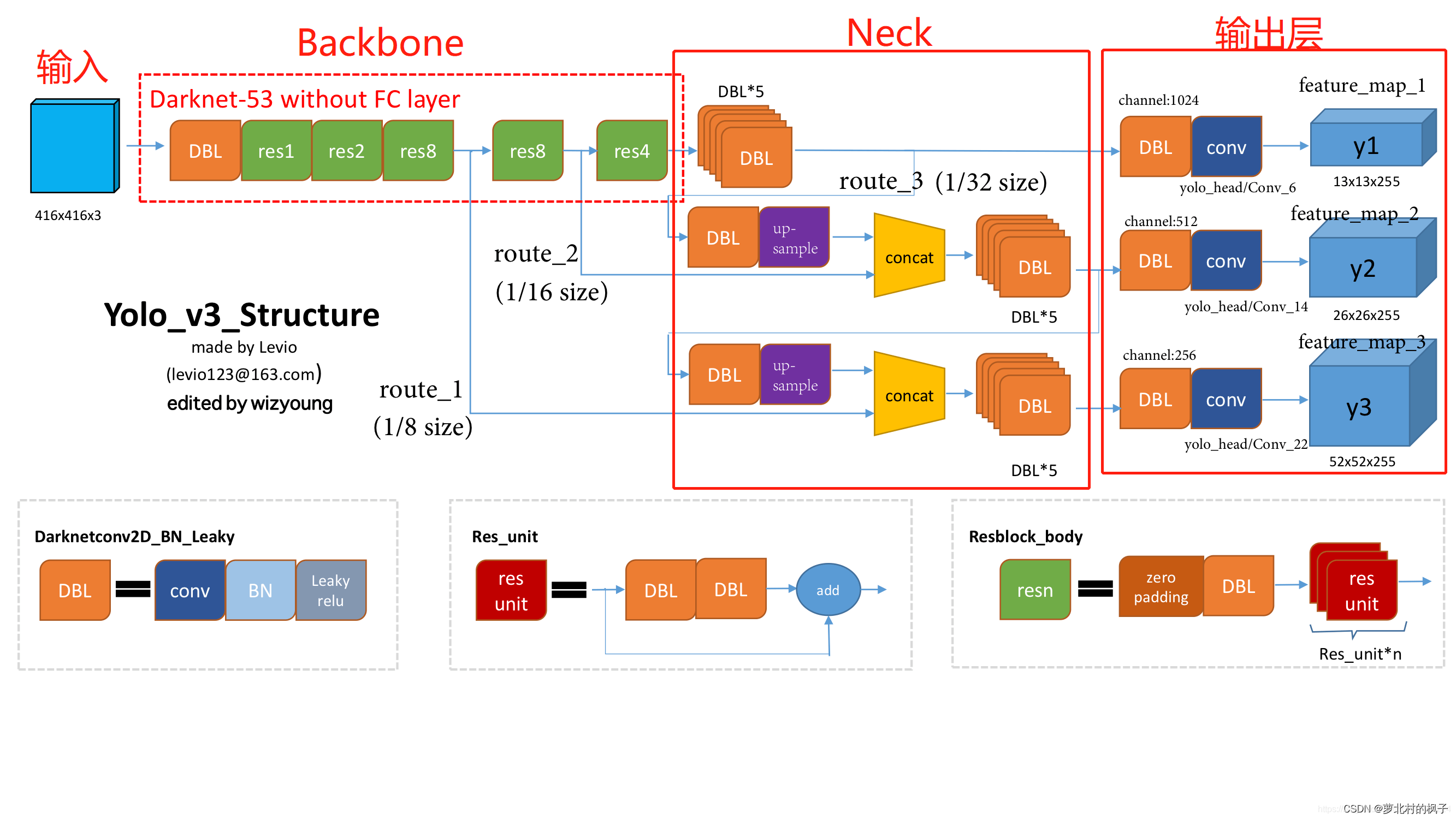
在这里引用一张作者是Levio的图片,如图所示输入416×416的三通道图片,经过骨干网络(Backbone)提取特征,由不同尺度的特征在Neck中进行汇总。
13×13通过上采样和26×26拼接(concatenation),得到输出层中的26×26
26×26通过上采样和52×52拼接,得到输出层中的52×52
输出层中255的含义:
255=85×3=(80+5)×3
5=4+1:中心点坐标、宽、高,置信度
80:80个类别的条件类别概率
2.4特征提取(Feature Extractor)
骨干网络提取出图像中好的特征来实现我们所需的目标
原文:
我们使用一个新的网络进行特征提取。新的网络混合了yolov2的Darknet-19和ResNet。我们的网络采用了连续的3×3卷积和1×1卷积,再加上了跨层连接。总共有53个带权重的卷积层,所以我们叫它Darknet-53(52个卷积层+1个全连接层)
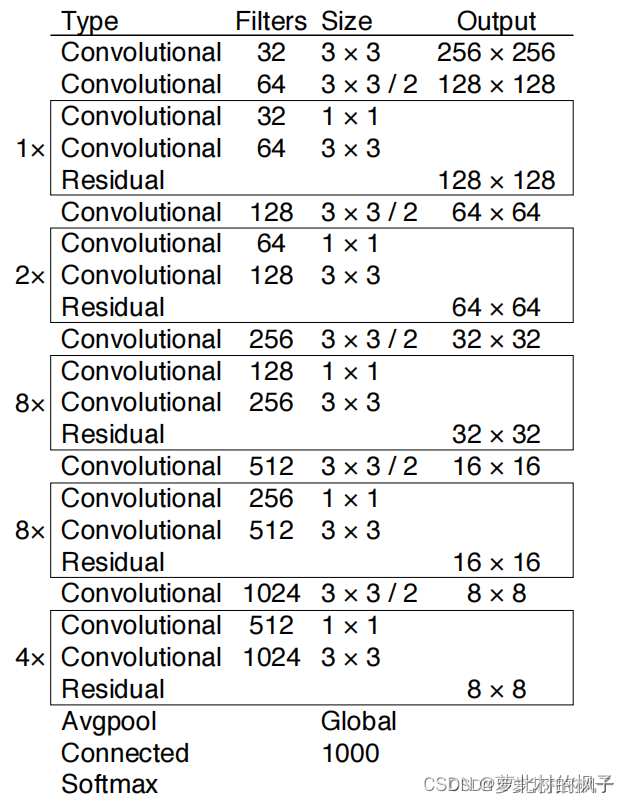
这个新的网络比Darknet-19要强得多,并且比ResNet-101和ResNet152效率要高的多(如下图所示)
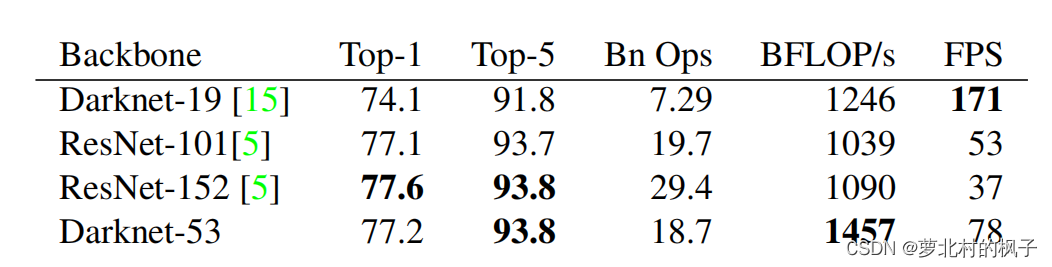
Top-5:准确率
Bn Ops:计算量
BFLOP/s:billions of operations,每秒可进行的十亿次的浮点运算量
FPS:Frames Per Second,FPS是图像领域中的定义,是指画面每秒传输帧数
(yolov2骨干网络是Darknet-19,yolov3骨干网络是Darknet-53,最新的yolov5的骨干网络是CSPDarknet-53,即融合了csp模块的Darknet-53网络)
2.5训练(Training)
原文:
我们仍然使用端对端训练,没有采用RCN中的难例挖掘。我们使用了多尺度的训练,大量的数据扩增,bn层,所有标准的东西。我们使用Darknet来进行深度学习训练测试。
3.How We Do
部分原文:
yolov3在COCO奇怪的mAP@0.5:0.95上和ssd效果是差不多的,在另一个指标上比ssd快三倍。不过yolov3仍然落后于在这个指标上像RetinaNet的其他网络。
然而在IOU=0.5(或图表中的AP50)时,yolov3的效果是非常好的,几乎可以和RetinaNet相媲美,,并且显著超过了SSD变种。这表明YOLOv3在低IOU阈值下的性能是非常好的。然而随着IOU阈值的增加,性能显著下降,这表明YOLOv3在高IOU阈值条件下的表现是不尽人意的。
在过去yolov在小物体检测上效果并不是很好,然而现在情况已经反转。随着新的多尺度预测,我们看到yolov3有更好的APs性能
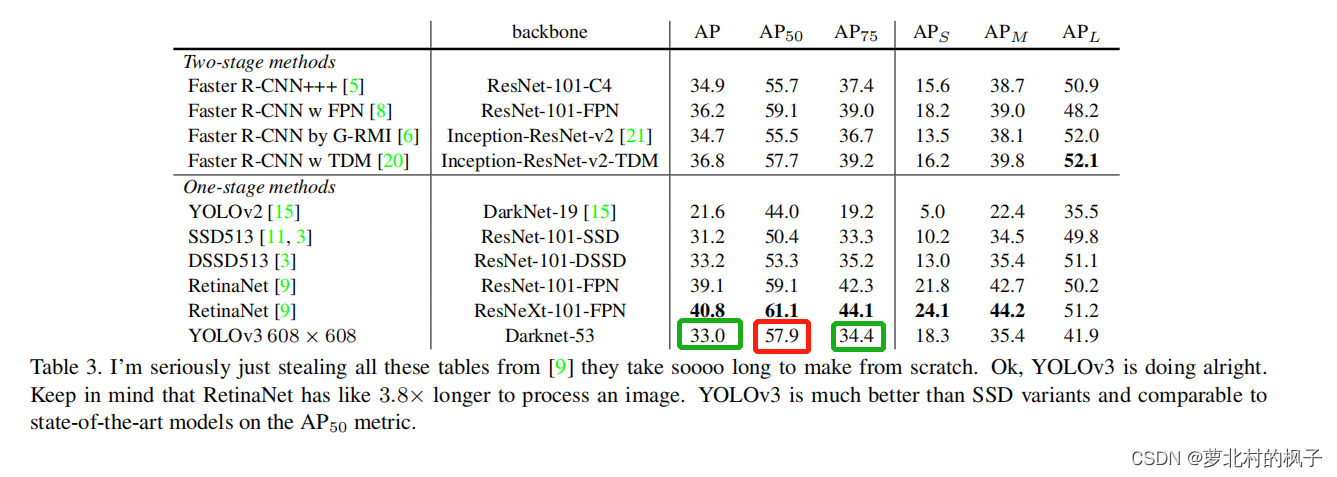
笔记:
由图表可知,yolov3在AP50时效果是比较好的(红色框),在AP和AP75条件下效果并不好(绿色框)
S:小物体,area(框大小)<32×32
M:中物体,32×32<area<96×96
L:大物体,96×96<area
APs:小目标的AP(剩下两个同理)
我们可以从表右下角得知,在小目标上的性能(18.3)是很好的,在中物体和大物体上的性能并不好(分别为35.4和41.9)
yolov3之前版本在小目标和密集目标检测上效果较差,以yolov1为例,yolov1将每张图像划分为7×7个grid cell,每一个grid cell只能预测出一个物体,即整张图最多只能预测出49个物体,一旦物体个数超过49个,yolov1就难以预测;并且如果两个物离得很近,密集目标也无法预测。
yolov3在小目标\密集目标的改进:
1.grid cell个数增加,yolov1(7×7),yolov2(13×13),yolov3(13×13+26×26+52×52)
2.yolov2和yolov3可以输入任意大小的图片,输入图片越大,产生的grid cell越多,产生的预测框也就越多
3.专门小目标预先设置了一些固定长宽比的anchor,直接生成小目标的预测框是比较难的,但是在小预测框基础上再生成小目标的预测框是比较容易的
4.多尺度预测(借鉴了FPN),既发挥了深层网络的特化语义特征,又整合了浅层网络的细腻度的像素结构信息
5.对于小目标而言,边缘轮廓是非常重要的,即浅层网络的边缘信息。在损失函数中有着惩罚小框项
6.网络结构:骨干网络加了跨层连接和残差连接(shortcut connection),这样可以整合各个层的特征,这样使得骨干网络本身的特征提取能力变好了
4.Things We Tried That Didn’t Work
部分原文:
在开发 YOLOv3 时,我们尝试了很多东西。很多都没有奏效。以下这些是我们记下来的一些东西。
锚框 x, y 偏移预测。我们尝试使用正常的锚框预测机制,使用x、y 线性偏移量预测为框宽度或高度的倍数。我们发现这种方式降低了模型的稳定性并且效果不佳。(预测相对于初始Anchor宽高倍数作为偏移量,预测框不受约束)
直接使用 x, y线性回归偏移量预测而不用sigmoid函数。我们尝试使用线性激活来直接预测 x,y 偏移而不是逻辑激活。这导致mAP下降了几个点。
Focal loss。我们尝试使用Focal loss。它使我们的mAP下降了大约 2 个点。 YOLOv3 可能已经对焦点损失试图解决的问题具有鲁棒性,因为yolov3采用了分离的置信度和条件类别概率。对于大多数例子来说,具体是什么原因,我们并不完全确定。
双IOU阈值和真值分配。 Faster RCNN在训练期间采用了两个IOU阈值。对于所有地面实况对象而言,如果IOU阈值大于0.7判定为正样本,小于0.3则为负样本,在0.7和0.3之间的被忽略。在yolov3中我们尝试了类似的方法,但没有得到好的结果。
我们非常喜欢我们目前的表述,它似乎至少处于局部最优状态。其中一些技术可能最终会产生良好的结果,也许它们只需要一些调整来稳定训练。
笔记:
Focal loss解决的是单阶段目标检测(ssd,yolov,RetinaNet等)正负样本不均衡,真正有用的负样本少的问题。相当于是某种程度的难例挖掘
yolov3中负样本的IOU阈值设置的过高(0.5),导致负样本中混入了正样本。正样本就会被赋予label noise,而Focal loss又会给label noise赋予更大的权重值,因此效果不好
RetinaNet的论文指出:单阶段目标检测不缺正样本,缺的是高质量的负样本。使用双IOU阈值只能增加正样本的个数,而负样本还是按照小于某个IOU阈值的方法去筛选。
5.What This All Means
第五部分是作者对未来的展望
以上笔记结束

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)