Python利用requests抓取页面源代码(基础)
Python利用requests抓取页面源代码(基础)Requests模块是一个用于网络访问的模块.由于使用到的requests库为第三方库,需要事先对其进行安装1.1安装requests(1)利用cmd安装,首先确保Python已经下载入电脑内,然后启动cmd控制台,输入pip install requests,等待下载完成即可(2)利用pycharm安装,在pycharm的Terminal中输
Python利用requests抓取页面源代码(基础)
Requests模块是一个用于网络访问的模块.
由于使用到的requests库为第三方库,需要事先对其进行安装
1.1安装requests
(1)利用cmd安装,首先确保Python已经下载入电脑内,然后启动cmd控制台,输入pip install requests,等待下载完成即可
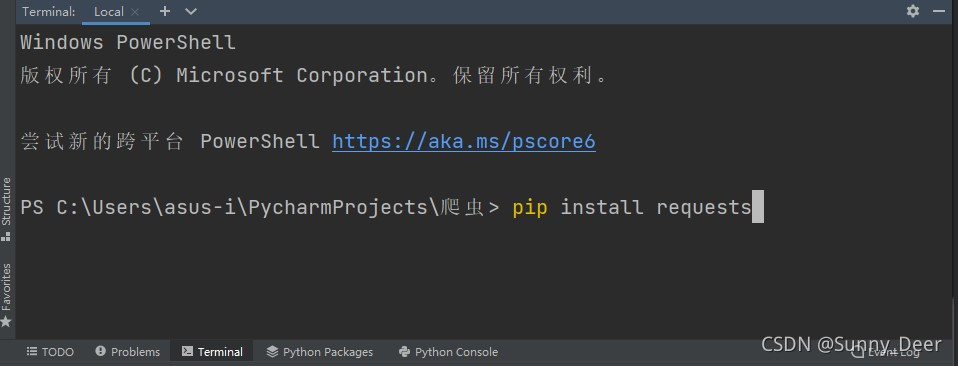
(2)利用pycharm安装,在pycharm的Terminal中输入 pip install requests 命令进行request的安装
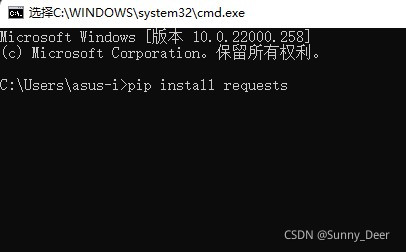
回车等待安装完毕即可
1.2网页请求方式
了解一下网页请求方式
一般来说,我们我们所使用的HTTP协议或者HTTPS协议,使用的请求方式最常见的有GET方式和POST方式
- GET方式:是最常见的HTTP方法之一,用于从指定资源请求数据,不需要在浏览器中输入链接之外的东西,只是想要获取一些资源,例如网页源代码。
- POST方式:用于将数据发送到服务器来创建或者更新资源,在访问某个网页之前需要用户输入链接之外的东西,需要发送给服务器,这样服务器才能根据你发送的信息来返回响应。
2.使用
2.1爬取搜索关键字页面数据
以搜狗搜索周杰伦为例
在搜狗搜索引擎中键入“周杰伦”后,得到的网址如下
https://www.sogou.com/web?query=邓紫棋&_asf=www.sogou.com&_ast=&w=01015002&p=40040108&ie=utf8&from=index-nologin&s_from=index&oq=&ri=0&sourceid=sugg&suguuid=&sut=0&sst0=1634387928175&lkt=0%2C0%2C0&sugsuv=1634387082744536&sugtime=1634387928175
我们只保留“https://www.sogou.com/web?query=邓紫棋”的地址(这个地址同样可以完成请求命令)
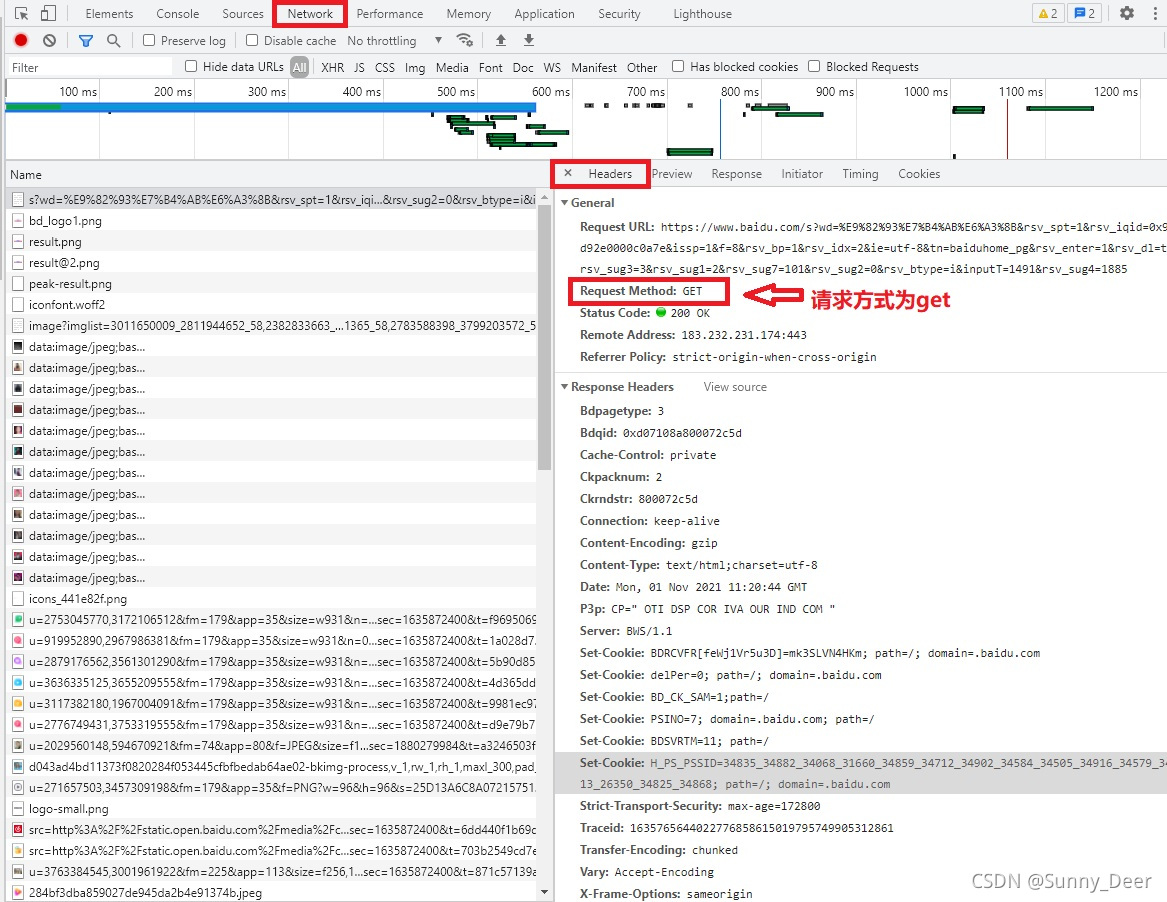
import requests #首先导入requests
url = "https://www.sogou.com/web?query=邓紫棋"
resp = requests.get(url) #由抓包工具可知使用get方法请求
print(resp)
resp.close()
运行结果为

从结果可知,我们的请求命令成功,并且得到了服务器回应
随后我们将响应内容输出
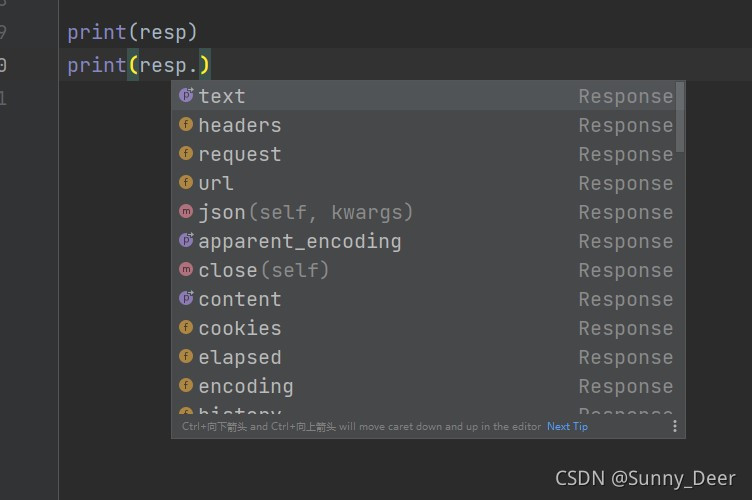
可以选择不同的输出内容,在这里我们选择text来查看源代码
2.2拦截处理
随后检查源代码发现我们的请求遭到了拦截,原因可能是是服务器认为我们的这次请求是通过自动化程序发出的而不是正常浏览器发出的
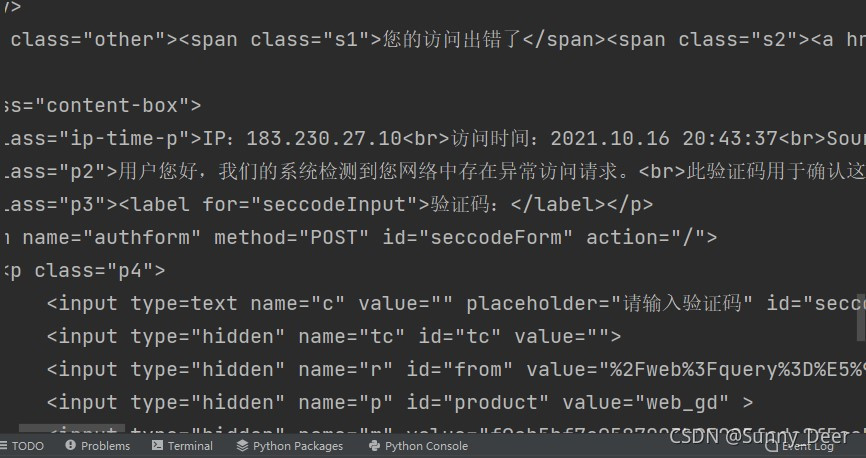
解决这个问题我们可以进行一个小小的伪装,用浏览器打开我们请求的页面的抓包工具的Network后刷新页面,选择其中的一个目标中找到User-Agent


headers = { #准备一个headers
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.47"
}
resp = requests.get(url,headers = headers)#将得到的User-Agent赋给headers来进行伪装
再次运行抓取,我们便得到了该页面的源代码
2.3改进(实现用户自主查询+将源代码写入文件)
#实现用户输入想要搜索的人物或者关键字,并进行抓取
import requests
quary = input("输入一个你喜欢的明星")
url = f"https://www.sogou.com/web?query={quary}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.47"
}
resp = requests.get(url,headers = headers)
with open("result.txt", mode="w",encoding="UTF-8") as f: #将源代码写入文件,将编码格式改为UTF-8
f.write(resp.text)
f.close()
resp.close() #记得关闭
这样我们就完成了利用requests库来抓取网页源代码(有了源代码,就可以获得更多的我们想要的数据了,这也是数据抓取的第一步)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)