Python实现TF-IDF提取关键词(sklearn库的使用)
TF-IDF算法TF−IDF=TF×IDFTF-IDF=TF\times IDFTF−IDF=TF×IDFTF=单词w在文档中出现的次数文档总词数TF=\frac{单词w在文档中出现的次数}{文档总词数}TF=文档总词数单词w在文档中出现的次数IDF=log文档总数包含单词w的文档数+1IDF=log\frac{文档总数}{包含单词w的文档数}+1IDF=log包含单词w的文档数文档总数+1P
·
TF-IDF算法
TF-IDF算法可用来提取文档的关键词,其主要思想是:如果某个单词在某篇文档中出现的频率很高,并且在其他文章中很少出现,则认为此词为该文档关键词。计算公式如下:

Python实现
TfidfVectorizer是sklearn中的库,可以用来计算TF-IDF值。
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.shape)
TfidfVectorizer=TfidfTransformer + CountVectorizer
fit_transform方法将语料转化成TF-IDF权重矩阵,get_feature_names方法可得到词汇表。
输出如下:

将权重矩阵转化成array:
X.toarray()
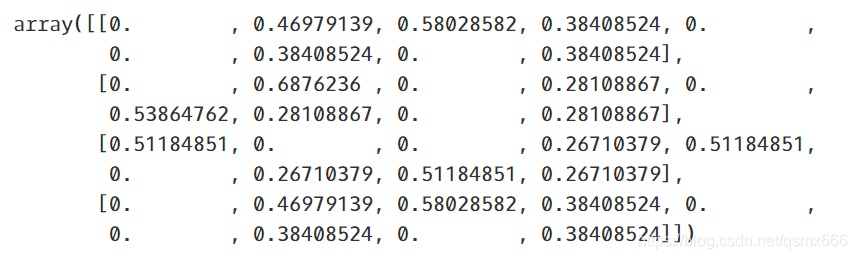
可以看到是4行9列,m行n列处值的含义是词汇表中第n个词在第m篇文档的TF-IDF值。提取单篇文档的关键词只需要将矩阵按行的值从大到小排序取前几个即可。如果要提取所有文档的关键词,我们可以将矩阵按列求和,得到每个词汇综合TF-IDF值。
X.toarray().sum(axis=0)

转化成dataframe,再排序。
data = {'word': vectorizer.get_feature_names(),
'tfidf': X.toarray().sum(axis=0).tolist()}
df = pd.DataFrame(data)
df.sort_values(by="tfidf" , ascending=False)
df
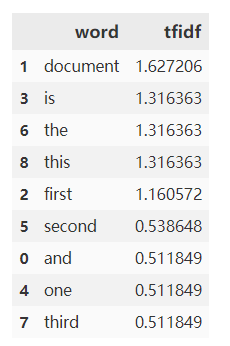
好啦,完成。假如取前三个为关键词,那么就是“document”、“is”和“the”。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)