样本不均衡及其解决办法
1 什么是类别不均衡类别不平衡(class-imbalance),也叫数据倾斜,数据不平衡,是指分类任务中不同类别的训练样例数目差别很大的情况。在现实的分类学习任务中,我们经常会遇到类别不平衡,例如广告点击率预测、故障分析、异常检测等;或者在通过拆分法解决多分类问题时,即使原始问题中不同类别的训练样例数目相当,在使用OvR(One vs. Rest)、MvM(Many vs. Many)策略后产生
1 什么是类别不均衡
类别不平衡(class-imbalance),也叫数据倾斜,数据不平衡,是指分类任务中不同类别的训练样例数目差别很大的情况。
在现实的分类学习任务中,我们经常会遇到类别不平衡,例如广告点击率预测、故障分析、异常检测等;或者在通过拆分法解决多分类问题时,即使原始问题中不同类别的训练样例数目相当,在使用OvR(One vs. Rest)、MvM(Many vs. Many)策略后产生的二分类任务仍然可能出现类别不平衡现象。而标准机器学习算法通常假设不同类别的样本数量大致相似,所以类别不平衡现象会导致学习算法效果大打折扣。因此有必要了解类别不平衡时处理的基本方法。
2 解决办法
每种解决方法都有其适用范围,需要因地制宜。甚至有时候根本就不需要专门处理,比如这两种情况(正样本为少数类别):
- 已经给定了问题的指标是ROC或者AUC等对类别不平衡不敏感的指标,那么此时不处理和处理的差别没那么大;
- 任务中正样本和负样本是同等重要的,即预测对一个正样本和预测对一个负样本是同等重要的,那么不做处理,让那些正样本被淹没也没啥影响。
如果我们对于召回有特别大的需求,也就是说我们更关心正样本,那么这个时候如果不做任何处理就很难拿到我们所希望的结果。因此,下面介绍几种办法
2.1 简单办法
(1)收集数据
针对少量样本数据,可以尽可能去扩大这些少量样本的数据集,或者尽可能去增加他们特有的特征来丰富数据的多样性
(2)将分类任务转换成异常检测
如果少数类样本太少,少数类的结构可能并不能被少数类样本的分布很好地表示,那么用平衡数据或调整算法的方法不一定有效。如果这些少数类样本在特征空间中再分布的比较散,情况会更加糟糕。这时候不如将其转换为无监督的异常检测算法,不用过多的去考虑将数据转换为平衡问题来解决。
(3)调整权重
可以简单的设置损失函数的权重,更多的关注少数类。在python的scikit-learn中我们可以使用class_weight参数来设置权重。为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”
例如在医疗诊断中,错误地把健康人诊断为患者可能会带来进一步检查的麻烦,但是错误地把患者诊断为健康人,则可能会丧失了拯救生命的最佳时机。
(4)阈值调整
直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将原本默认为0.5的阈值调整到 即可。(大部分是负样本,因此分类器倾向于给出较低的分数)
即可。(大部分是负样本,因此分类器倾向于给出较低的分数)
2.2 数据层面-重采样
重采样是不平衡学习领域使用最广泛的一类方法,关注于通过修改训练数据集以使得标准学习算法也能在其上有效训练。根据实现方式的不同,可被进一步分类为:
- 欠采样,从多数类别中删除样本(如ENN、Tomeklink、NearMiss、EasyEnsemble等)
- 过采样,为少数类别生成新样本(如SMOTE、Borderline-SMOTE、ADASYN等)
- 上述两种方案的结合(如SMOTE+ENN等)
由于随机欠采样可能会丢失含有重要信息的样本,随机过采样可能会招致严重的过拟合(简单的复制少数类的样本),引入无意义的甚至有害的新样本(粗暴地合成少数类样本),因此发展了一系列更高级的方法,试图根据数据的分布信息来在进行重采样的同时保持原有的数据结构。
在重采样过程中,要尽可能的保持训练样本和测试样本的概率分布是一致的。如果违背了独立同分布的假设,很可能会产生不好的效果。
2.2.1 欠采样
去除一些多数类中的样本使得正例、反例数目接近,然后再进行学习
(1)随机欠采样
随机欠采样顾名思义即从多数类中随机选择一些样样本组成样本集 。然后将新样本集与少数类样本集合并。
随机欠采样方法通过改变多数类样本比例以达到修改样本分布的目的,从而使样本分布较为均衡,但是这也存在一些问题。对于随机欠采样,由于采样的样本集合要少于原来的样本集合,因此会造成一些信息缺失,即将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
(2)Edited Nearest Neighbor (ENN)
遍历多数类的样本,如果他的大部分k近邻样本都跟他自己本身的类别不一样,我们就将他删除;
(3)Repeated Edited Nearest Neighbor(RENN)
重复以上ENN的过程直到没有样本可以被删除;
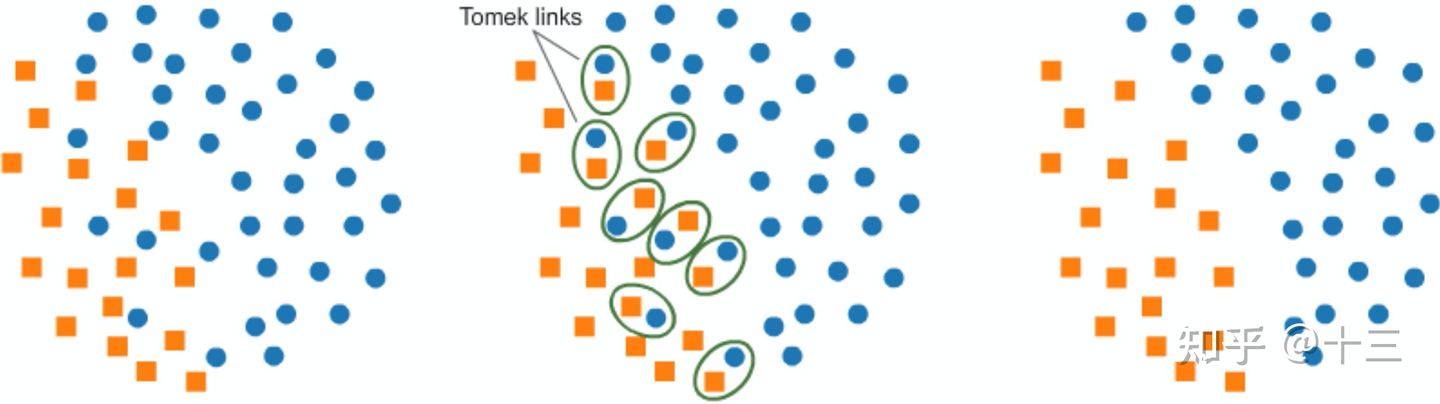
(4)Tomek Link Removal
其思想是,类别间的边缘可能增大分类难度,通过去除边缘中的多数类样本可以使得类别间margin更大,便于分类。具体方法是:如果有两个不同类别的样本,它们的最近邻都是对方,也就是A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link,我们要做的就是将所有Tomek link都删除掉。那么一个删除Tomek link的方法就是,将组成Tomek link的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉。这样我们可以发现正负样本就分得更开了。如下图所示。
2.2.2 过采样
(1)随机过采样
随机过采样是在少数类S中随机选择一些样本,然后通过复制所选择的样本生成样本集E,将它们添加到S中来扩大原始数据集从而得到新的少数类集合S+E。
缺点:
对于随机过采样,由于需要对少数类样本进行复制来扩大数据集,造成模型训练复杂度加大。另一方面也容易造成模型的过拟合问题,因为随机过采样是简单的对初始样本进行复制采样,这就使得学习器学得的规则过于具体化,不利于学习器的泛化性能,造成过拟合问题。
(2)SMOTE(Synthetic Minority Oversampling,合成少数类过采样)
SMOTE是对随机过采样方法的一个改进算法,通过对少数类样本进行插值来产生更多的少数类样本。基本思想是针对每个少数类样本,从它的k近邻中随机选择一个样本 (该样本也是少数类中的一个),然后在两者之间的连线上随机选择一点作为新合成的少数类样本。
存以下两个缺点:
A) 由于对每个少数类样本都生成新样本,因此容易发生生成样本重叠的问题。
B) 在SMOTE算法中,出现了过度泛化的问题,主要归结于产生合成样本的方法。特别是,SMOTE算法对于每个原少数类样本产生相同数量的合成数据样本,而没有考虑其邻近样本的分布特点,这就使得类间发生重复的可能性增大。(3)Borderline SMOTE
先将所有的少数类样本分成三类:
- Noise: 所有的k近邻个样本都属于多数类;
- Danger : 超过一半的k近邻样本属于多数类;
- Safe: 超过一半的k近邻样本属于少数类。如下图所示。
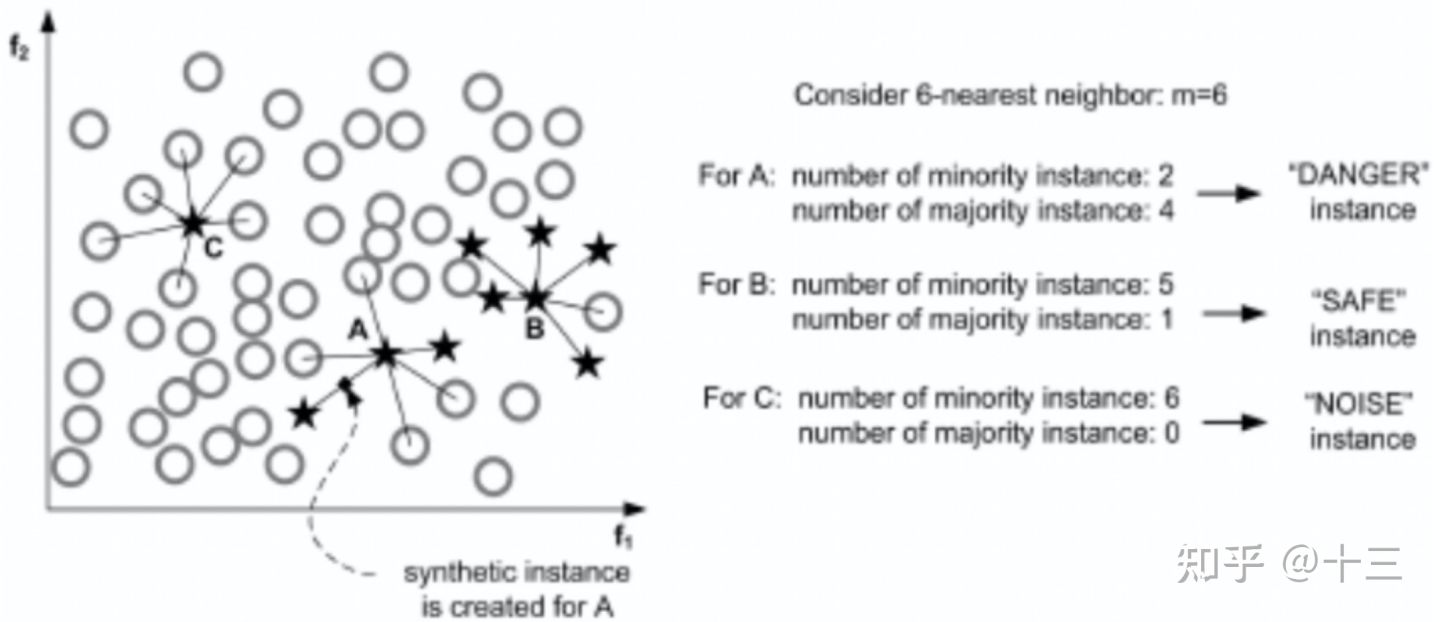
Danger类的点都在边界处,以此为种子作为出发点,然后用SMOTE算法产生新的样本。若选取的另一端的样本在Noise或Safe集合中,则随机插值处应靠近种子样本端。
2.2.3 欠采样 + 过采样
- SMOTE + Tomek Link Removal
- SMOTE + ENN
2.2.4 采样方法的优劣
优点:
- 平衡类别分布,在重采样后的数据集上训练可以提高某些分类器的分类性能。
- 欠采样方法减小数据集规模,可降低模型训练时的计算开销。
缺点:
- 采样过程计算效率低下,通常使用基于距离的邻域关系(k近邻)来提取数据分布信息,计算开销大。
- 易被噪声影响,最近邻算法容易被噪声干扰,可能无法得到准确的分布信息,从而导致不合理的重采样策略。
- 过采样方法生成过多数据,会进一步增大训练集的样本数量,增大计算开销,并可能导致过拟合。
- 不适用于无法计算距离的复杂数据集,如用户ID。
2.3 算法层面
2.3.1 代价敏感
代价敏感学习是对调整权值方法的扩展,调整权重的方法通常用在二分类中,但是代价敏感学习把这种思想进一步扩展,可以设置代价矩阵用于多分类,也可以用代价矩阵对标准算法进行改造,使其适应不平衡数据的学习,比如针对决策树,可以将代价矩阵代入到决策阈值选择、分裂标准、剪枝这三个方面。
优点:
- 不增加训练复杂度,可直接用于多分类问题。
缺点:
- 需要领域先验知识:代价矩阵需要由领域专家根据任务的先验知识提供,这在许多现实问题中显然是不可用的。因此在实际应用时代价矩阵通常被直接设置为归一化的不同类别样本数量比,不能保证得到最优的分类性能。
- 不适合某些分类器:对于需要以批次训练(mini-batch training)方法训练的模型(如神经网络),少数类样本仅仅存在于在很少的批次中,这会导致梯度下降更新的非凸优化过程会很快陷入鞍点,使得网络无法进行有效学习。
2.3.2 集成学习
(1) EasyEnsemble
为了克服随机欠采样方法导致的信息缺失问题,又要保证算法表现出较好的不均衡数据分类性能,出现了欠采样法代表性的算法EasyEnsemble。

1:数据中,少数标签的为P,多数标签的N,为P与N在数量上的比例,T为需要采集的subset份数,也可以说是设置的基分类器的个数。
为训练基分类器i (默认使用AdaBoost,也可以设置为其他,例如XGBoost)的训练循环次数(iteration)。
2-5: 根据少数标签的为P的数量,对多数标签的N进行随机采样产生,使得采样出来的数量和P的数量一样。
6: 把和P结合起来,然后给基分类器i学习。这里的公式只单个基分类器的训练过程。论文里用的基分类器是AdaBoost,而AdaBoost是由N个弱分类器组成的,j就是表示Adaboost基分类器里的第j个弱分类器.
7: 重复采样,训练T个这样的基分类器。
8: 对T个基分类器进行ensemble。而这里并非直接取T个基分类的结果(0,1)进行投票,而是把n个基分类器的预测概率进行相加,最后再通过sign函数来决定分类,sgn函数就是sign函数,sgn就是把结果转成两个类,小于0返回-1,否则返回1。.
(2) balance cascade

第1步相同就未贴,差别就在第7步和第8步。通过控制分类阈值来控制假正例率(False Positive Rate),将所有判断正确的类删除。
2.4 评估方法

- AccuracyRate(准确率):

- Recall(召回率,查全率,击中概率):
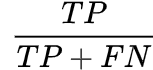 , 在所有GroundTruth为正样本中有多少被识别为正样本了;
, 在所有GroundTruth为正样本中有多少被识别为正样本了; - Precision(查准率):
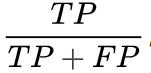 ,在所有识别成正样本中有多少是真正的正样本;
,在所有识别成正样本中有多少是真正的正样本; - F1-score:

- Roc: 横轴
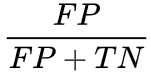 ,纵轴
,纵轴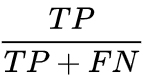
- Auc: Roc曲线下面积
3 总结
- 类别不平衡中学习的评价指标最好选用聚焦于正例的指标,而非Accuracy;
- 随机降采样 + Bagging是万金油。
- 解决方法需要因地制宜
文章来源:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)