Pandas中求某一列中每个列表的平均值
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤露从今夜白,月是故乡明。大家好,我是皮皮。一、前言前几天在Python最强王者交流群【冫马讠成】问了一道Pandas处理的问题,如下图所示。原始数据如下:df=pd.DataFrame({'student_id':['S001','S002','S003'],...
点击上方“Python共享之家”,进行关注
回复“资源”即可获赠Python学习资料
今
日
鸡
汤
露从今夜白,月是故乡明。
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【冫马讠成】问了一道Pandas处理的问题,如下图所示。
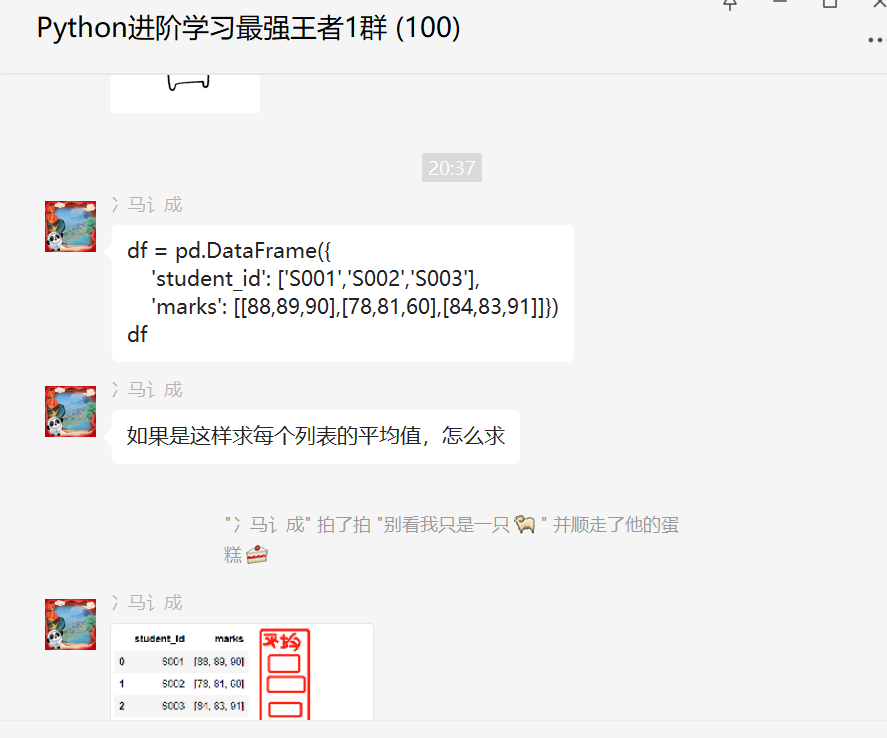
原始数据如下:
df = pd.DataFrame({
'student_id': ['S001','S002','S003'],
'marks': [[88,89,90],[78,81,60],[84,83,91]]})
df预期的结果如下图所示:

二、实现过程
方法一
这里【瑜亮老师】给出一个可行的代码,大家后面遇到了,可以对应的修改下,事半功倍,代码如下所示:
df['dmean'] = df['marks'].map(lambda x: np.mean(x))运行之后,结果就是想要的了。

方法二
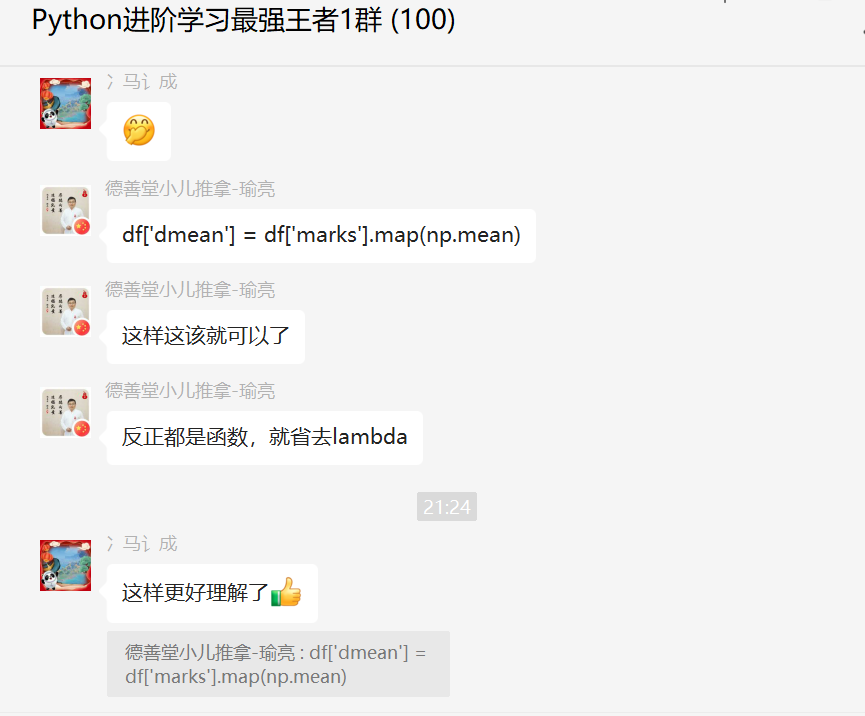
后来【瑜亮老师】又给了一份优化后的代码如下所示:
df['dmean'] = df['marks'].map(np.mean)
或者
df['dmean'] = df['marks'].apply(np.mean)运行之后,结果就是想要的了。
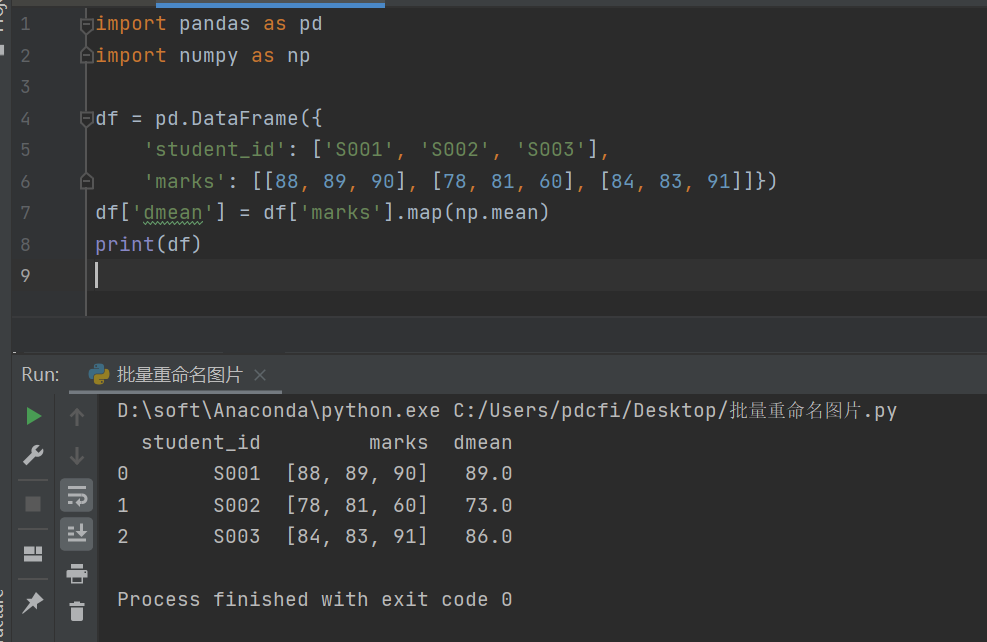
完美的解决了粉丝的问题!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道使用Pandas处理数据的问题,文中针对该问题给出了具体的解析和代码实现,一共两个方法,帮助粉丝顺利解决了问题。
最后感谢粉丝【冫马讠成】提问,感谢【月神】、【瑜亮老师】给出的思路和代码解析,感谢【dcpeng】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)