Python数据分析入门笔记4——数据预处理之重复值
用pandas进行数据分析之前,必须先对缺失值、重复值和异常值进行处理。本文记录了重复值的检测与处理方法。
系列文章目录
Python数据分析入门笔记1——学习前的准备
Python数据分析入门笔记2——pandas数据读取
Python数据分析入门笔记3——数据预处理之缺失值
前言
pandas可以用isnull(),isna(),notnull()和notna()四个方法来检测缺失值。
若要直观地统计表中各列的缺失率,可以用自定义函数或者missingno库来实现。
- 如果缺失数据只有个别几个,可以直接用dropna()方法按行删除;
例如:要从一个DataFrame中,删掉列1内容为NaN或者列2内容为NaN的行,并且删除后覆盖更新原数据
DataFrame名称.dropna(axis=0, subset=[‘列1’,‘列2’], inplace=True)
- 如果这一列80%以上数据都缺失,可以考虑用drop()方法直接删除这一列;
例如:要从一个DataFrame中,列1和列2中缺失了绝大部分数据,那么可以用axis=1来代表删除列
DataFrame名称.drop(axis=1, subset=[‘列1’,‘列2’])
- 如果缺失数据的这列,数据不是时间序列类型,那可以直接用默认值或者统计值来填充;
例如:将这个DataFrame对象中的所有缺失值都填充为缺失值前面的值。
DataFrame名称.fillna(method=‘ffill’)
- 如果缺失数据的这一列是时间序列类型,通常用线性插补法来插补数据。
例如:结合线性插值法对这个DataFrame对象中的缺失值进行插补。
DataFrame名称.interpolate(method=‘linear’)
一、重复值的检测
pandas中使用duplicated()方法来检测数据中的重复值。检测完数据后会返回一个由布尔值组成的Series类对象,该对象中若包含True,说明该值对应的一行数据为重复项。
DataFrame.duplicated(subset=None, keep=‘first’)
| 参数 | 说明 | 取值和解释 |
|---|---|---|
| subset | 表示识别重复项的列索引或列索引序列。默认标识所有的列索引 | |
| keep | 表示采用哪种方式保留重复项。 | ‘first’,默认值,删除重复项,仅保留第一次出现的数据项。 ‘last’,删除重复项,仅保留最后一次出现的数据项。 ‘False’,表示将所有相同的数据都标记为重复项。 |
用法如下:
import pandas as pd
import numpy as np
stu_info=pd.DataFrame({'序号':['S1','S2','S3','S4','S4'],
'姓名':['张三','李四','王五','赵六','赵六'],
'性别':['男','男','女','男','男'],
'年龄':[15,16,15,14,14],
'住址':['苏州','南京',np.nan,np.nan,np.nan]})
# 检测stu_info对象中的重复值
stu_info.duplicated()
原始数据:
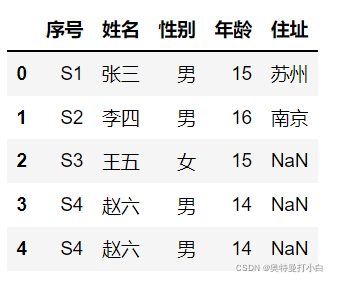
输出结果:

对比两次结果,我们能发现,行索引号为4的数据和行索引号为3的数据完全相同,所以我们调用duplicated()方法会默认保留第一次出现的数据,将后面出现的重复值标记为True。
若想筛选出重复值标记为True的所有数据,可以用如下代码:
# 筛选stu_info中重复值标记为True的数据记录
stu_info[stu_info.duplicated()]
运行结果如下:

二、重复值的处理
对于重复值,pandas中一般使用drop_duplicates()方法删除重复值。
DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False, ignore_index=False)
参数说明:
| 参数 | 说明 | 取值和解释 |
|---|---|---|
| subset | 表示删除重复项的列索引或列索引序列,默认删除所有的列索引。 | |
| keep | 表示采用哪种方式保留重复项。 | ‘first’,默认值,删除重复项,仅保留第一次出现的数据项。 ‘last’,删除重复项,仅保留最后一次出现的数据项。 ‘False’,表示将所有相同的数据都标记为重复项。 |
| inplace | 表示是否放弃副本数据,返回新的数据,默认为False | True,放弃副本,更新原数据。 False,不更新原数据。 |
| ignore_index | 表示是否对删除重复值后的对象的行索引重新排序,默认为False。 | True,重新排序。 False,不重新排序。 |
用法如下:
# 删除stu_info对象中的重复值
stu_info.drop_duplicates()
执行结果:
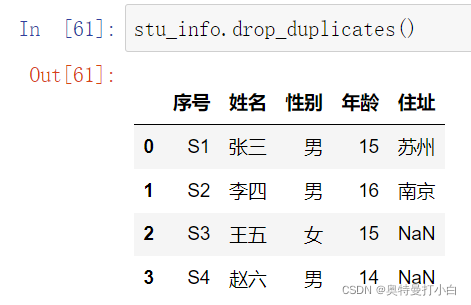
我们可以看出,行索引为4的一行数据被删除了。
总结
重复值的检测与处理比较简单。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)