Python爬虫:数据存储——CSV文件
崔大神《Python3网络爬虫开发实战(第2版)》阅读总结,可作为字典方便查询,持续更新中······
·
一. CSV
- CSV:Comma-Sparated Values,逗号分隔值(字符分隔值)
- 以纯文本形式存储数据表格,可由任意数目的记录组成,各条记录以某种换行符分隔开
二. 使用规则
1. 写入
1.1 writer
- 初始化写入对象,以逗号分隔字段
1.2 writerow( )
-
传入每行数据
import csv
with open('data.csv','w') as csvfile:
writer=csv.writer(csvfile)
writer.writerow(['id','name','age'])
writer.writerow(['1','a','20'])
writer.writerow(['2','b','21'])
writer.writerow(['3','c','22'])
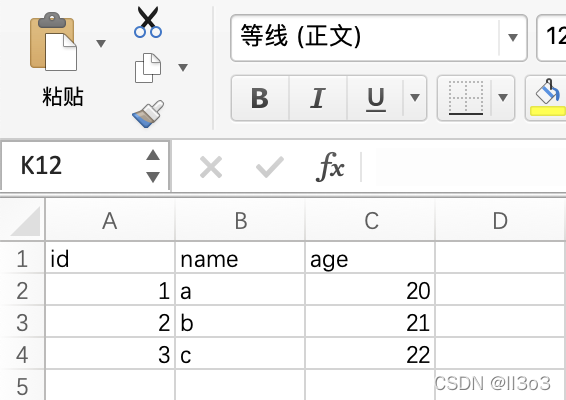
#运行结果
id,name,age
1,a,20
2,b,21
3,c,22同时生成csv文件,可用Excel打开
![]()
1.3 writerows( )
- 同时传入多行数据,此时参数需要传二维列表。输出结果同上
import csv
with open('data.csv','w') as csvfile:
writer=csv.writer(csvfile)
writer.writerow(['id','name','age'])
writer.writerows([['1','a','20'],['2','b','21'],['3','c','22']])1.4 delimiter
- 修改列与列之间的分隔符
- delimiter=' ':列与列以空格分隔
import csv
with open('data.csv','w') as csvfile:
writer=csv.writer(csvfile,delimiter=' ')
writer.writerow(['id','name','age'])
writer.writerow(['1','a','20'])
writer.writerow(['2','b','21'])
writer.writerow(['3','c','22'])1.5 字典写入
-
fieldnames
- DicWriter
- writeheader
先定义3个字段,用fieldnames表示,然后将其传给DicWriter方法初始化一个字典写入对象,并将对象赋给writer变量。接着调用写入对象的writerheader方法先写入头信息,再调用writerow方法传入相应字典。输出结果同上。
import csv
with open('data.csv','w') as csvfile:
fieldnames = ['id', 'name', 'age']
writer=csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id':'1','name':'a','age':'20'})
writer.writerow({'id':'2','name':'b','age':'21'})
writer.writerow({'id':'3','name':'c','age':'22'})1.6 追加写入
- a:追加写入模式
import csv
with open('data.csv','a') as csvfile:
fieldnames = ['id', 'name', 'age']
writer=csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writerow({'id':'4','name':'d','age':'22'})
#运行结果
id,name,age
1,a,20
2,b,21
3,c,22
4,d,22
1.7 写入中文内容
- 制定编码模式
with open('data.csv','a',encoding='utf-8') as csvfile:- pandas库
安装
pip3 install pandas使用:先定义几条数据,每条数据都是一个字典,然后将其组合成一个列表,赋值为data。接着使用pandas的DataFrame类新建了一个DataFrame对象,参数传入data,并把该对象赋值为df。最后调用df的to_csv方法将数据保存为csv文件
import pandas as pd
data=[{'id':'1','name':'陈','age':'20'},
{'id':'2','name':'李','age':'20'},
{'id':'3','name':'张','age':'20'}]
df=pd.DataFrame(data)
df.to_csv('data.csv',index=False)2. 读取
2.1 reader( )
- 通过遍历输出了文件中每行的内容,每一行都是一个列表
- 如果CSV文件中包含中文,需要指定文件编码
import csv
with open('data.csv','r',encoding='utf-8') as csvfile:
reader=csv.reader(csvfile)
for row in reader:
print(row)
#运行结果
['id', 'name', 'age']
['1', '陈', '20']
['2', '李', '20']
['3', '张', '20']2.2 pandas读取
- read_csv( ):读取CSV文件
import pandas as pd
df=pd.read_csv('data.csv')
print(df)- tolist( ):只读数据
import pandas as pd
df=pd.read_csv('data.csv')
data=df.values.tolist()
print(data)
#运行结果
[[1, '陈', 20], [2, '李', 20], [3, '张', 20]]
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)