Python Pandas Dataframe.describe()用法及代码示例
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。Pandas describe()用于查看一些基本的统计详细信息,例如数据帧的百分位数,均值,标准差等或一系列数值。当此方法应用于一系列字符串时,它将返回不同的输出,如以下示例所示。用法:DataFrame.describe(percenti
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas describe()用于查看一些基本的统计详细信息,例如数据帧的百分位数,均值,标准差等或一系列数值。当此方法应用于一系列字符串时,它将返回不同的输出,如以下示例所示。
用法:DataFrame.describe(percentiles=None, include=None, exclude=None)
参数:
percentile:列出像0-1之间的数字的数据类型以返回各自的百分位数
include:描述 DataFrame 时要包括的数据类型列表。默认为无
exclude:描述 DataFrame 时要排除的数据类型列表。默认为无
返回类型: DataFrame 的统计摘要。
要下载以下示例中使用的数据集,请单击此处。在以下示例中,使用的 DataFrame 包含一些NBA球员的数据。下面是任何操作之前的数据帧图像。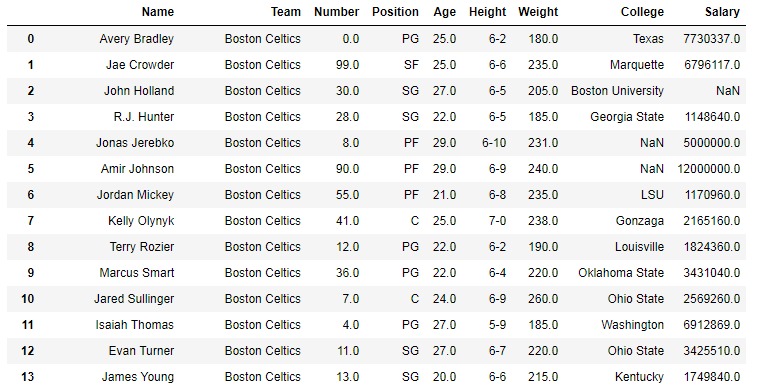
范例1:描述具有对象和数字数据类型的 DataFrame
在此示例中,描述了 DataFrame ,并传递了['object']以包含参数以查看对象系列的描述。将[.20,.40,.60,.80]传递给百分位数参数,以查看数字系列的相应百分位数。
# importing pandas module
import pandas as pd
# importing regex module
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# percentile list
perc =[.20, .40, .60, .80]
# list of dtypes to include
include =['object', 'float', 'int']
# calling describe method
desc = data.describe(percentiles = perc, include = include)
# display
desc输出:
如输出图像中所示,返回了数据帧的统计描述以及各自传递的百分位数。对于带有字符串的列,返回NaN进行数字运算。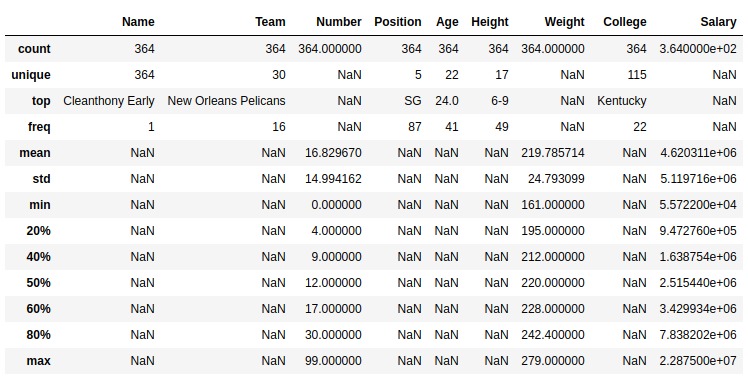
范例2:描述字符串系列
在此示例中,“名称”列调用describe方法,以查看对象数据类型的行为。
# importing pandas module
import pandas as pd
# importing regex module
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# calling describe method
desc = data["Name"].describe()
# display
desc输出:
如输出图像中所示,describe()的行为对于一系列字符串是不同的。
在这种情况下,返回了不同的统计信息,例如值的计数,唯一值,出现次数的最高值和发生频率。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)