pandas数据处理——根据条件新增/替换某一列值
以前又傻又菜的时候,根据条件替换某一列值或新增总是会写一些for 循环去处理,现在发现一个更简洁的方式,就是善用pandas方法。根据条件新增一列值现有数据集如下所示:调用apply()方法,可以作用于Series或者整个DataFrame,它自动遍历整个Series或者DataFrame, 对每一个元素运行指定的函数。新增一列label,要求按照id列是否包含M来指定label的取值:#按条件新
·
以前又傻又菜的时候,根据条件替换某一列值或新增总是会写一些for 循环去处理,现在发现一个更简洁的方式,就是善用pandas方法。
根据条件新增一列值
现有数据集如下所示:
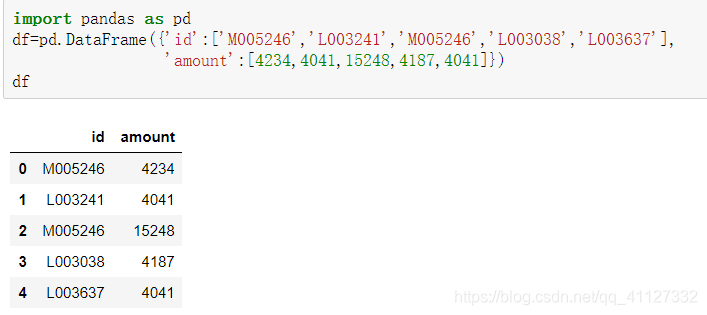
调用apply()方法,可以作用于 Series 或者整个 DataFrame,它自动遍历整个 Series 或者 DataFrame, 对每一个元素运行指定的函数。
新增一列label,要求按照id列是否包含M来指定label的取值:
#按条件新增一列
df['label']=df.id.apply(lambda x: 1 if 'M' in x else 0)
df输出:

根据条件替换某一列值
数据集如下所示:
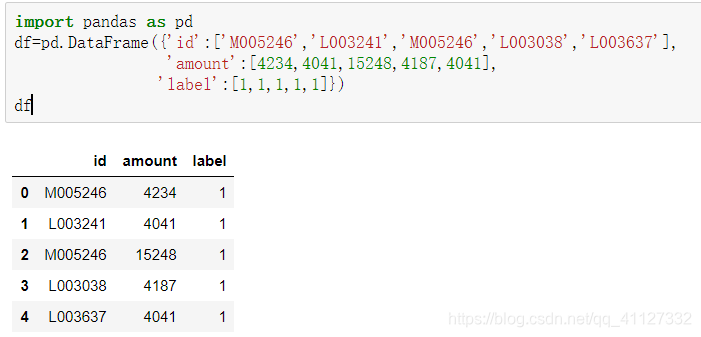
如果id列值包含‘L’,那么就将label列中对应的值从1替换成0:
df.loc[df['id'].str.contains('L'),'label']=0
df输出:


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)