决策树的绘制与图像解读
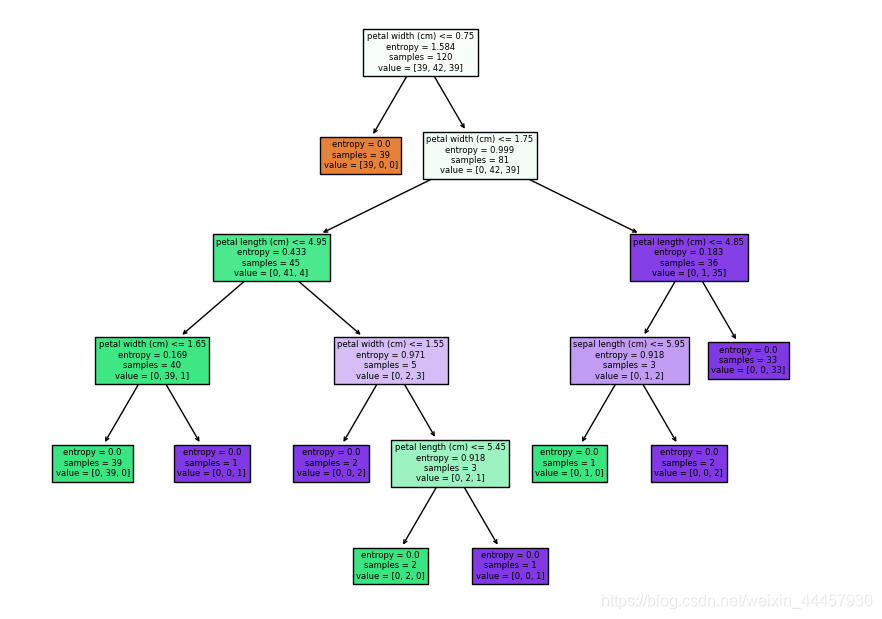
决策树决策树的显示结果可以看到,满足petal width <= 0.75的样本,其三种标签值的样本数分别为[39, 0, 0],也就是说,只要满足这个条件,它的结果是确定的,因此交叉熵为0
1 决策树的绘制
可以调用 sklearn.tree.plot_tree 方法绘制决策树,不用像之前那样保存为dot格式文件再转化,而是可以直接绘制
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
from sklearn import tree
import matplotlib.pyplot as plt
# 导入数据
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
feature_names = iris.feature_names
# 划分数据
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 1024)
# 决策树实例化、拟合、预测
clf = DecisionTreeClassifier(criterion='entropy')
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
# 指定图幅大小
plt.figure(figsize=(18,12))
# 绘制图像
_ = tree.plot_tree(clf,filled = True,feature_names=feature_names) # 由于返回值不重要,因此直接用下划线接收
plt.show()
# 保存图像
plt.savefig('./tree.jpg')
输出
因为scikit-learn是基于numpy,scipy和matplotlib开发的模块,这三个库中,只有matplotlib有绘图功能,因此可以使用matplotlib中的方法设定图幅大小并显示。
程序运行结束之后,会在当前目录下多出一个“tree.jpg”的文件
最后显示的图可以看到,根据驯良数据得到的决策树,如果按照数据结构中的标准是6层,但这里我们不考虑叶节点,那么该决策树的深度为5。
2 图像解读
为了便于分析决策树的显示结果,我们这里只绘制1层,代码为
_ = tree.plot_tree(clf,filled = True,feature_names=iris.feature_names,max_depth=1)
# max_depth表示绘制的最大深度,最大深度不包含叶子节点,
# 如果max_depth是1,则按数据结构中的标准是2层
# 有可能决策树不止1层,但这里只绘制一层
我们对输出的结果进行解读
对于每个划分点,有四条信息,分别为划分依据、当前交叉熵(如果没指定交叉熵,则为基尼系数,基尼系数的计算看本博客第三节),当前样本数,各类样本的数量
对于每个叶子节点,其比划分节点少一条信息,即划分依据,除此之外其他三条信息都一样。

如果在实例化决策树类的时候,不对树的深度加以限制,那么将会把样本划分到交叉熵(或基尼系数)为0为止。
为何第一个节点要按照 petal width > 0.75 进行裂分?
因为CART算法,具体参考《机器学习算法导论》王磊、王晓东
3 限制图像的深度
基尼系数的计算公式
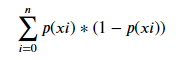
这里我们使用基尼系数,并且限制图像深度
clf = DecisionTreeClassifier(criterion='gini', max_depth=3)
clf.fit(X_train,y_train)
plt.figure(figsize=(12,10))
_ = tree.plot_tree(clf,filled=True,feature_names = feature_names)
plt.show()
输出
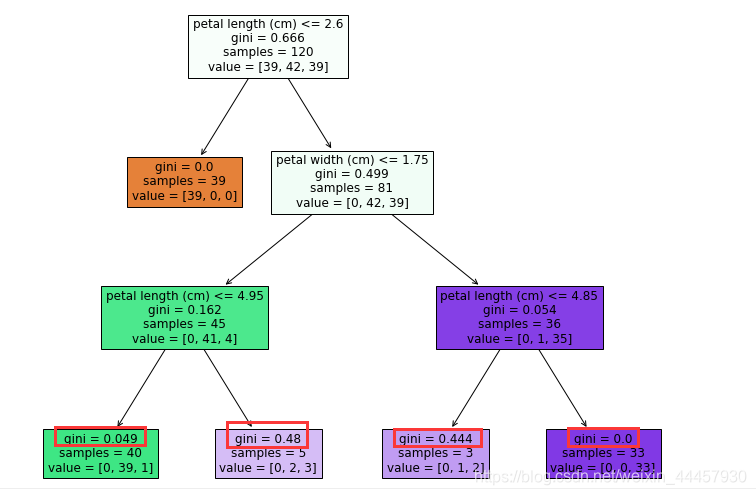
可以看到,由于限定了树的深度,使得叶子结点的基尼系数并非都为0,只有第二层的叶子结点基尼系数为0

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)