数据特征处理——jupyter notebook为例
目录数据集读取数据提取数据合并编码One-Hot编码标签编码分箱归一化与标准化归一化标准化处理缺失值判断缺失值是否存在处理缺失值数据集划分PAC降维简单可视化例子在训练机器学和深度学习模型时,都需要数据作为支持,数据可看作一个矩阵,行为数据个数,列为数据特征。在有监督学习中,某一列特征为目标值,无监督学习则没有,下面介绍几种常见的数据处理方法下面以简单的iris数据集为例:数据集读取from sk
在训练机器学和深度学习模型时,都需要数据作为支持,数据可看作一个矩阵,行为数据个数,列为数据特征。
在有监督学习中,某一列特征为目标值,无监督学习则没有,下面介绍几种常见的数据处理方法
下面以简单的iris数据集为例:
数据集读取
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris() #导入数据集
#iris = pd.read_csv("文件路径/文件名.csv") #数据集在本地使用pandas导入
#划分X,y
iris_features = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
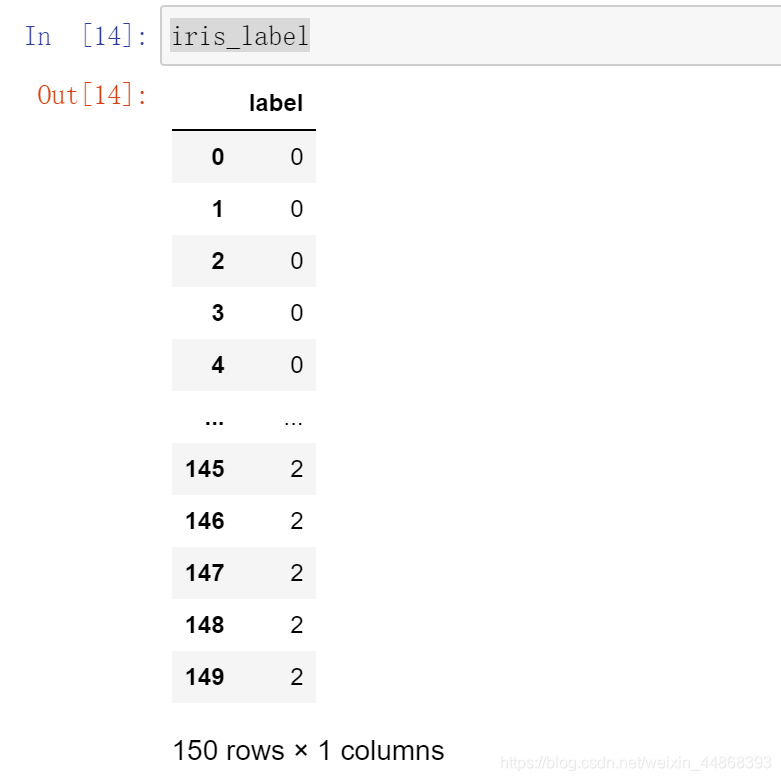
iris_label = pd.DataFrame(iris.target,columns = ["label"])
数据提取
data_1 = iris.iloc[0: ,0:4] #表示选取所有数据的前四列
data_2 = iris.iloc[0:100 , :] #表示选取前100个数据
lables = iris["label"] #将数据“Species”这一列取出
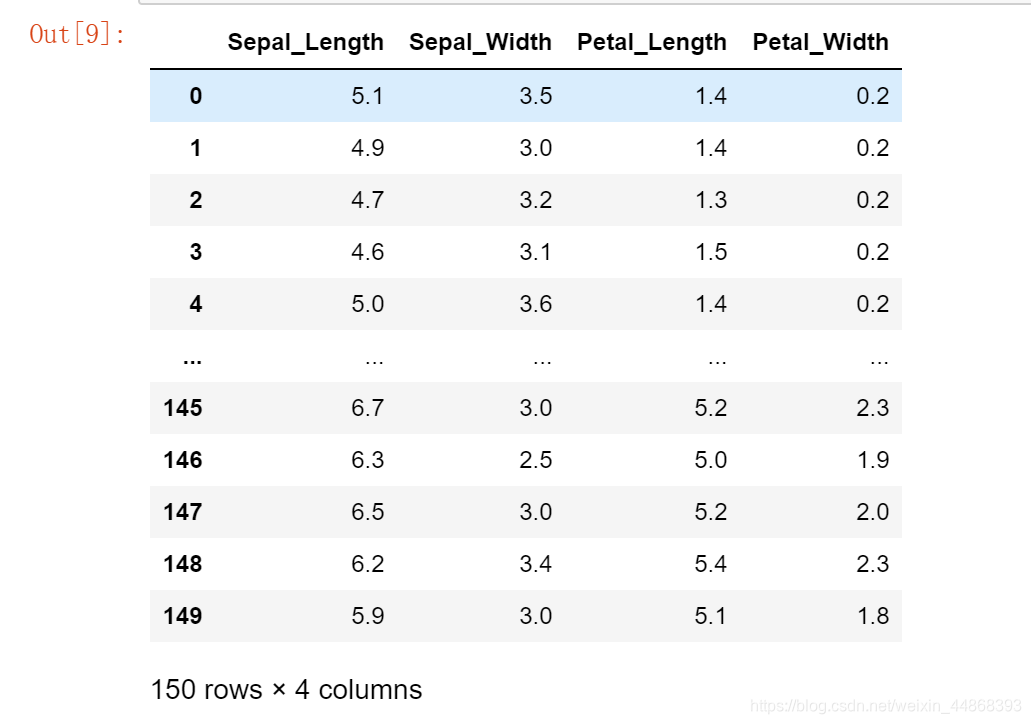
iris_features
数据合并
iris = pd.concat([iris_features,iris_label], axis=1) #axis=0要求列相同 ; axis=1要求行相同

编码
One-Hot编码
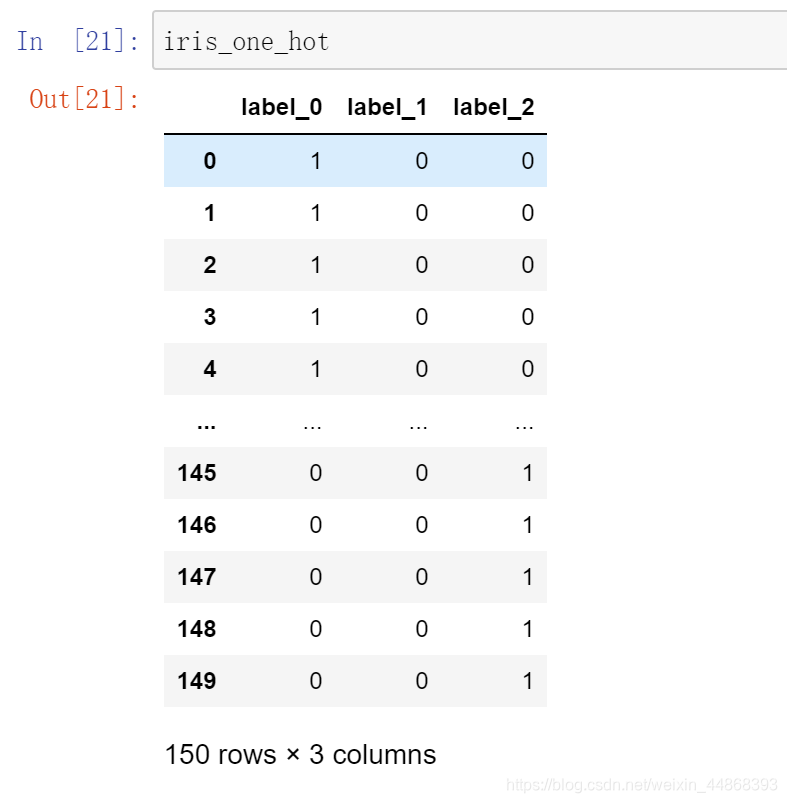
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
pandas.get_dummies(data, prefix=None)
data: 数据集目标值columns名字
prefix:分组名字
iris_one_hot = pd.get_dummies(iris['label'], prefix="label")
标签编码
通过为每个类别分配一个唯一的整数值,将分类数据转换为数字,称为标签编码。
# from sklearn.compose import ColumnTransformer
# labelencoder = ColumnTransformer()
# iris.iloc[:, -1] = labelencoder.fit_transform(iris.iloc[:, -1])
分箱
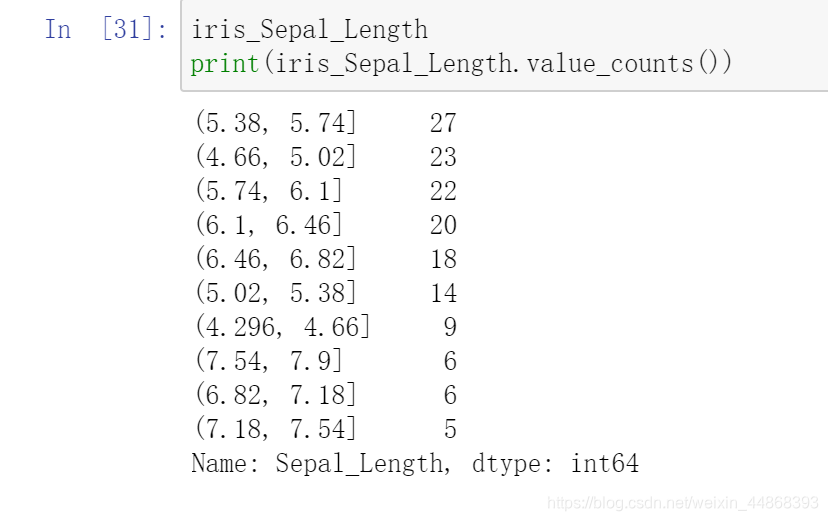
当我们有一个数字特征,需要把它转换成分类特征,使用分箱,减少目标值类别,提高标签的信息承载度
#bins = [0, 1, 2, 3, 4, 5, 6, 7, 8]#自定义
bins = 10 #分成10组
iris_Sepal_Length= pd.cut(iris['Sepal_Length'], bins)
归一化与标准化
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,
容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间

最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
归一化演示
:return: None
"""
data = iris
print(data)
# 1、实例化一个转换器类
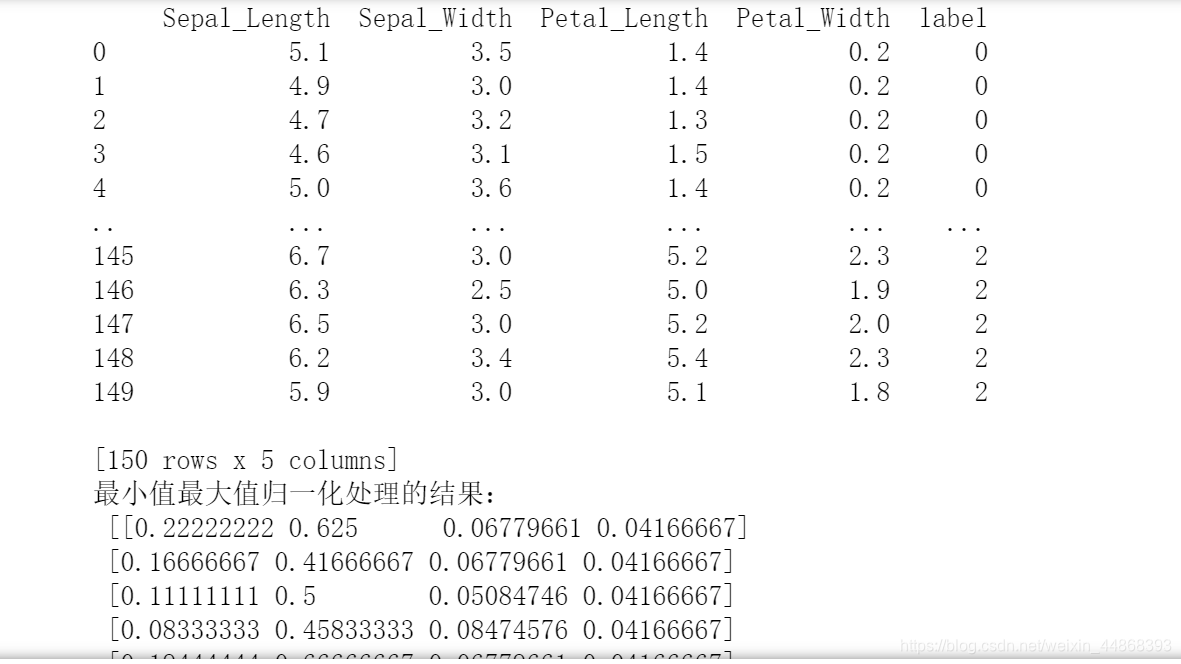
transfer = MinMaxScaler(feature_range=(0, 1)) #范围区间
# 2、调用fit_transform
data = transfer.fit_transform(data.iloc[:,0:-1])
print("最小值最大值归一化处理的结果:\n", data)
return None
minmax_demo()
标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
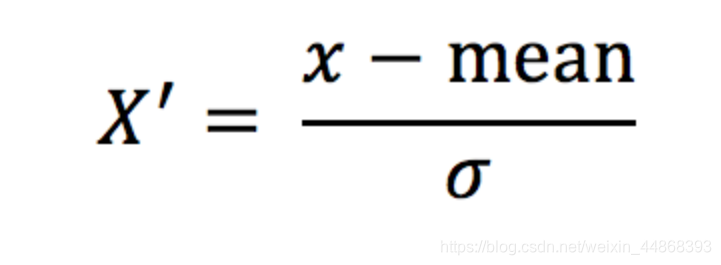
方差越大,说明数据间差异越大
from sklearn.preprocessing import StandardScaler
def stand_demo():
"""
标准化演示
:return: None
"""
data = iris
print(data)
# 1、实例化一个转换器类
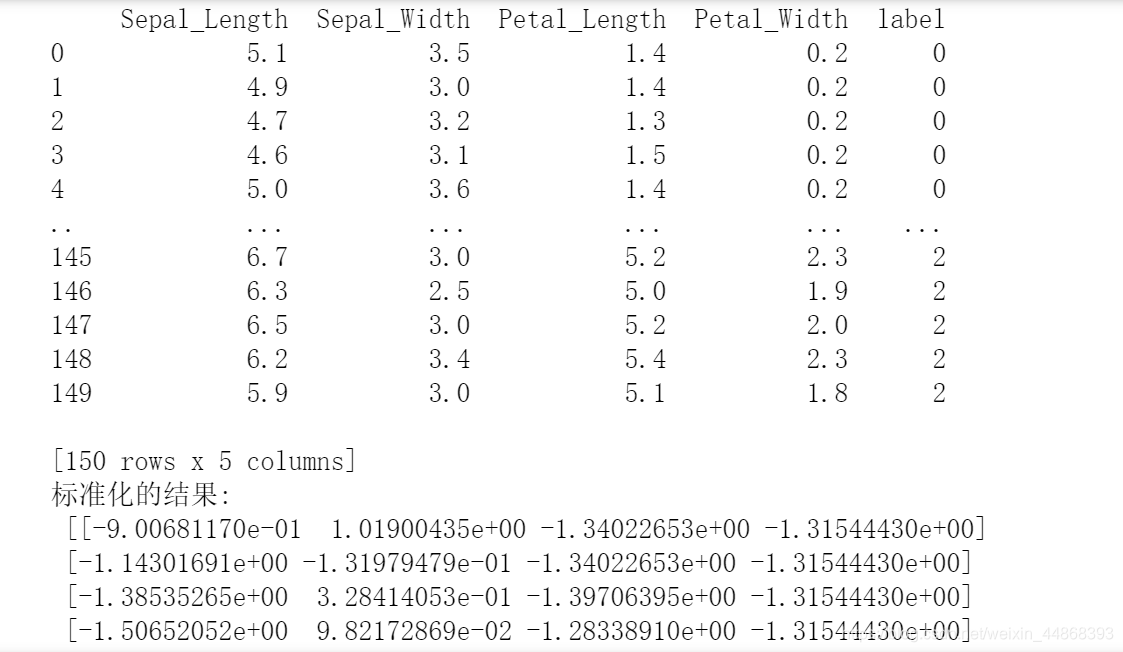
transfer = StandardScaler()
# 2、调用fit_transform
data = transfer.fit_transform(data.iloc[:,0:-1])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
stand_demo()
处理缺失值
判断缺失值是否存在
import numpy as np
np.all(pd.notnull(iris)) #True则不存在缺失值
处理缺失值
# 把一些其它值标记的缺失值,替换成np.nan
iris = iris.replace(to_replace='?', value=np.nan)
# 删除
iris = iris.dropna()
# 替换填充平均值,中位数
iris['Sepal_Length'].fillna(iris['Sepal_Length'].mean(), inplace=True)
#替换所有缺失值
for i in iris.columns:
if np.all(pd.notnull(iris[i])) == False:
print(i)
iris[i].fillna(iris[i].mean(), inplace=True)
数据集划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_label,test_size=0.2)
PAC降维
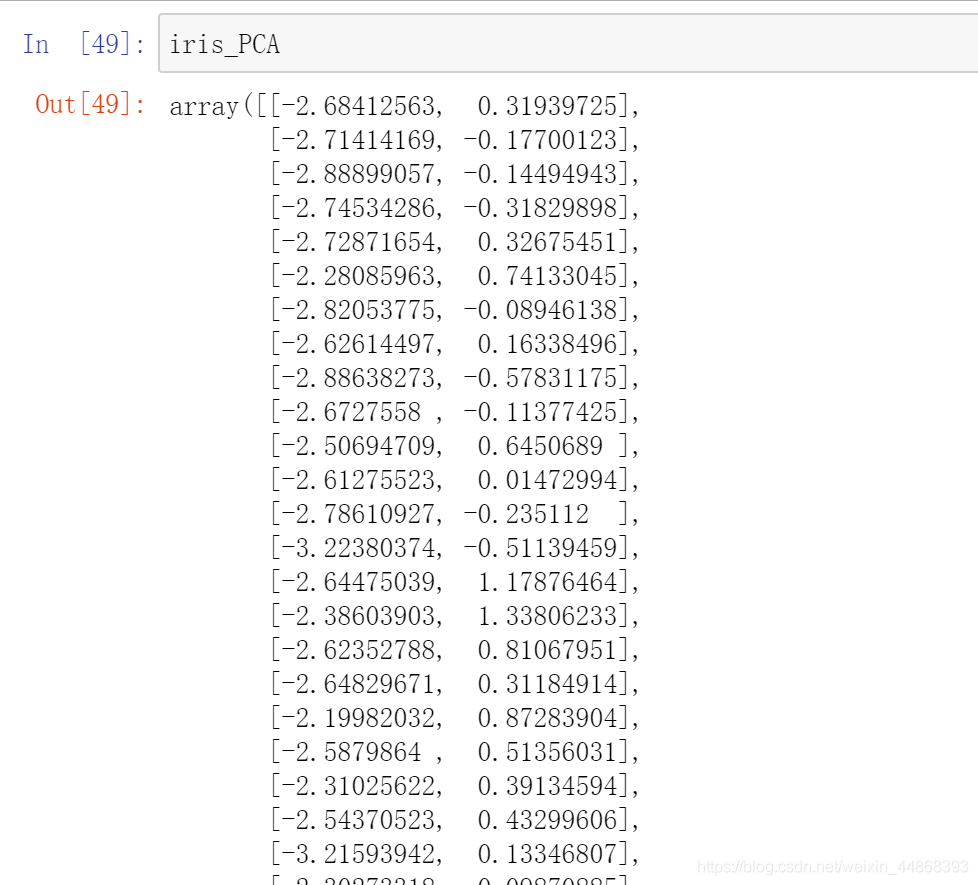
from sklearn.decomposition import PCA
transfer_1 = PCA(n_components=2) #n_components为正整数表示特征值由4维降为2维,若为小于1的小数就代表准确率
iris_PCA = transfer_1.fit_transform(iris_features)
简单可视化
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.scatter(iris_PCA[:,0], iris_PCA[: ,1])
plt.show()
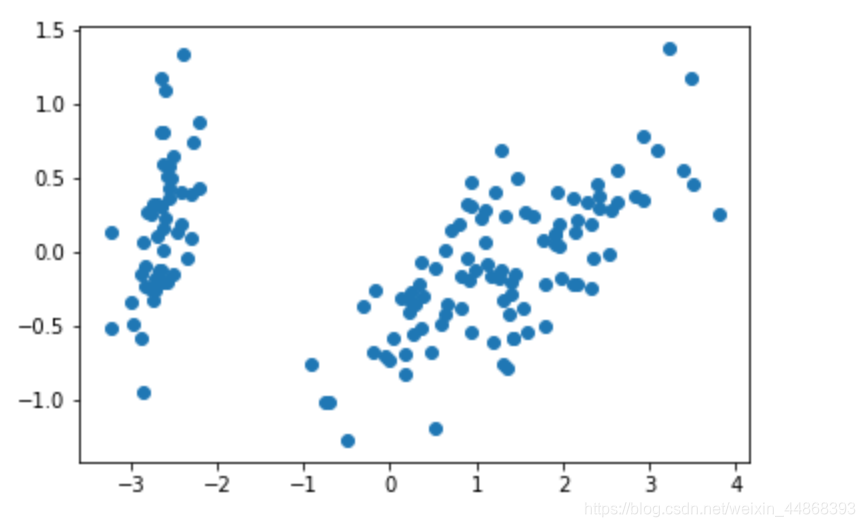
sns.lmplot(x = "Sepal_Length", y = "Petal_Length",data = iris ,hue = "label", fit_reg = False,markers=["o","x","s"], x_jitter = 0.2, y_jitter = 0.2, scatter_kws = {'alpha' : 1/3})
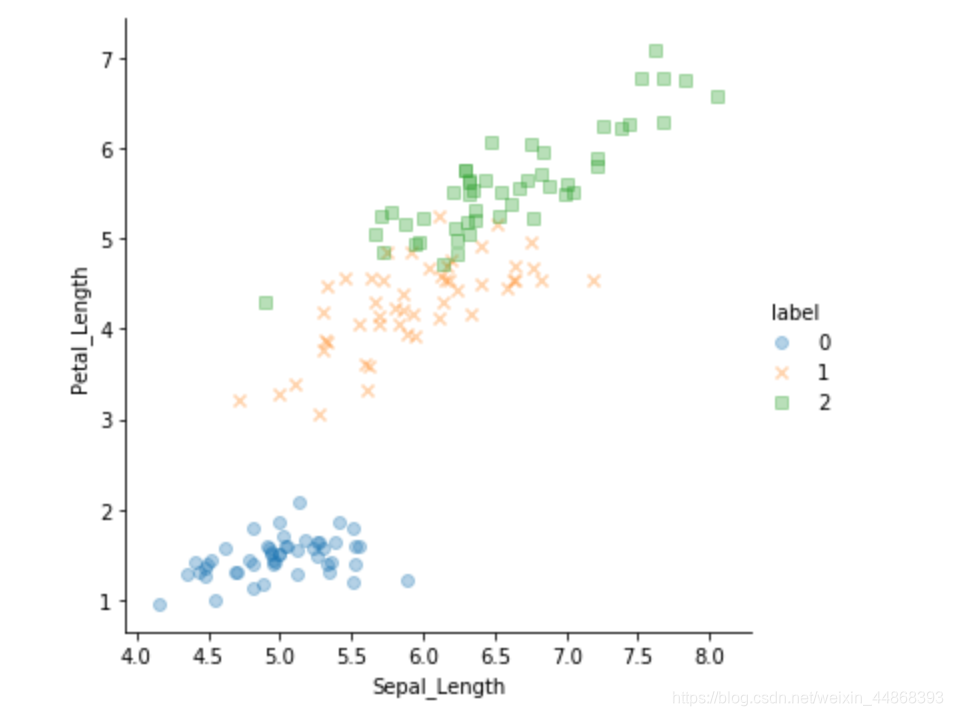
#各个特征之间关系分布图
pd.plotting.scatter_matrix(iris.iloc[:,0:-1], alpha = 0.8, figsize = (30,12), diagonal = 'kde')
例子
常用机器学习数据处理流程如下:
1.导入数据(编码,分箱,处理缺失值)
2.标准化(PCA降维)
3.划分数据集
4.sklearn模型训练
5.测试准确率
6.可视化
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#1.read data
iris = load_iris()
iris_features = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_label = pd.DataFrame(iris.target,columns = ["label"])
iris = pd.concat([iris_features,iris_label], axis=1)
#2.standardization
from sklearn.preprocessing import StandardScaler
def stand_demo():
"""
标准化演示
:return: None
"""
data = iris
#print(data)
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用fit_transform
data = transfer.fit_transform(data.iloc[:,0:-1])
#print("标准化的结果:\n", data)
#print("每一列特征的平均值:\n", transfer.mean_)
#print("每一列特征的方差:\n", transfer.var_)
return data
iris_features = pd.DataFrame(stand_demo(),columns=["Sepal_Length"," Sepal_Width "," Petal_Length "," Petal_Width"])
iris = pd.concat([iris_features,iris_label], axis=1)
#3.PCA
from sklearn.decomposition import PCA
transfer_1 = PCA(n_components=2) #n_components为正整数表示特征值由4维降为2维,若为小于1的小数就代表准确率
iris_PCA = transfer_1.fit_transform(iris_features)
#4.data split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris_PCA , iris_label,test_size=0.2)
#5.ml
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf = RandomForestClassifier(n_estimators=200, random_state=0)
clf.fit(x_train, y_train) # 使用训练集对分类器训练
y_predict = clf.predict(x_test) # 使用分类器对测试集进行预测
print(clf.score(x_test , y_test))
# 6.performance index
from sklearn import metrics
import matplotlib.pyplot as plt
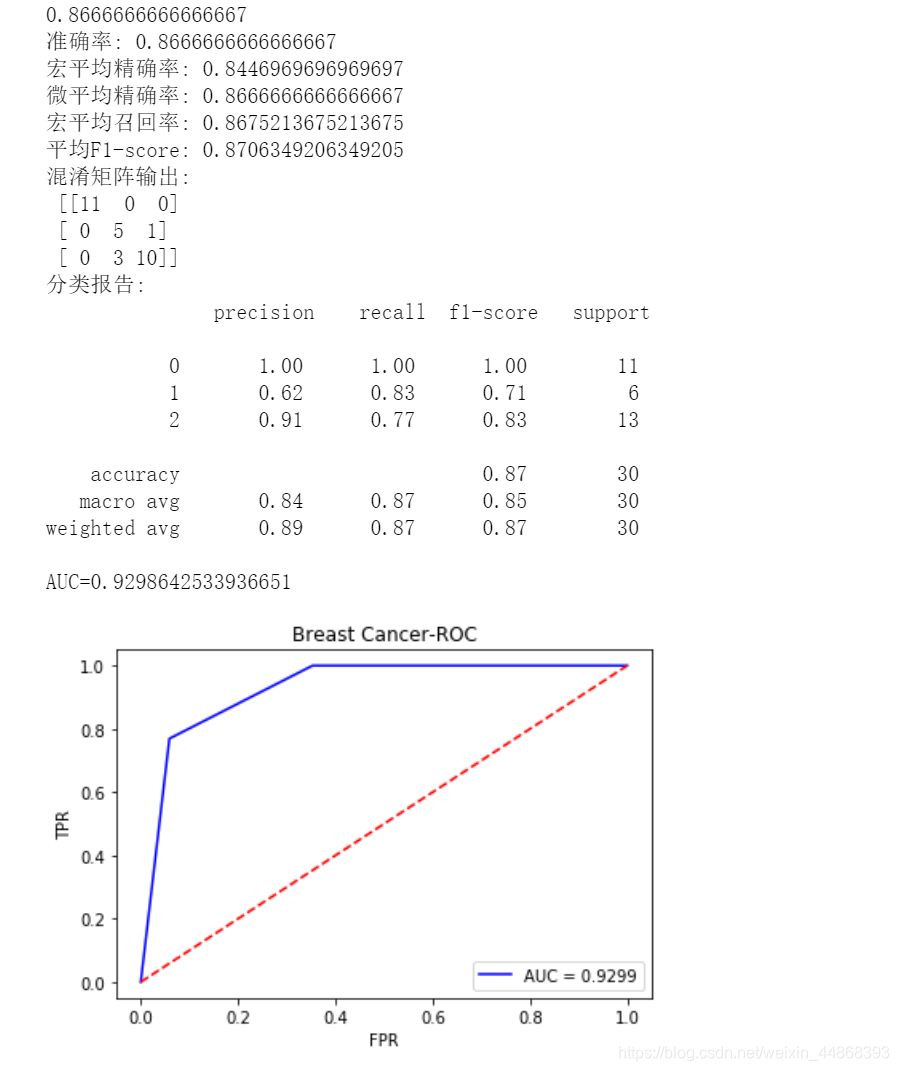
def Performance_metrics(y_test, y_predict):
print('准确率:', metrics.accuracy_score(y_test, y_predict)) #预测准确率输出
print('宏平均精确率:',metrics.precision_score(y_test,y_predict,average='macro')) #预测宏平均精确率输出
print('微平均精确率:', metrics.precision_score(y_test, y_predict, average='micro')) #预测微平均精确率输出
print('宏平均召回率:',metrics.recall_score(y_test,y_predict,average='macro'))#预测宏平均召回率输出
print('平均F1-score:',metrics.f1_score(y_test,y_predict,average='weighted'))#预测平均f1-score输出
print('混淆矩阵输出:\n',metrics.confusion_matrix(y_test,y_predict))#混淆矩阵输出
print('分类报告:\n', metrics.classification_report(y_test, y_predict))#分类报告输出
false_positive_rate, true_positive_rate, thresholds = metrics.roc_curve(y_test, y_predict, pos_label=2)
roc_auc = metrics.auc(false_positive_rate, true_positive_rate) #计算AUC值
print('AUC=' + str(roc_auc))
plt.title('Breast Cancer-ROC')
plt.plot(false_positive_rate, true_positive_rate, 'b', label='AUC = %0.4f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
# plt.savefig('figures/PC5.png') #将ROC图片进行保存
plt.show()
Performance_metrics(y_test, y_predict)
# 7 visualization
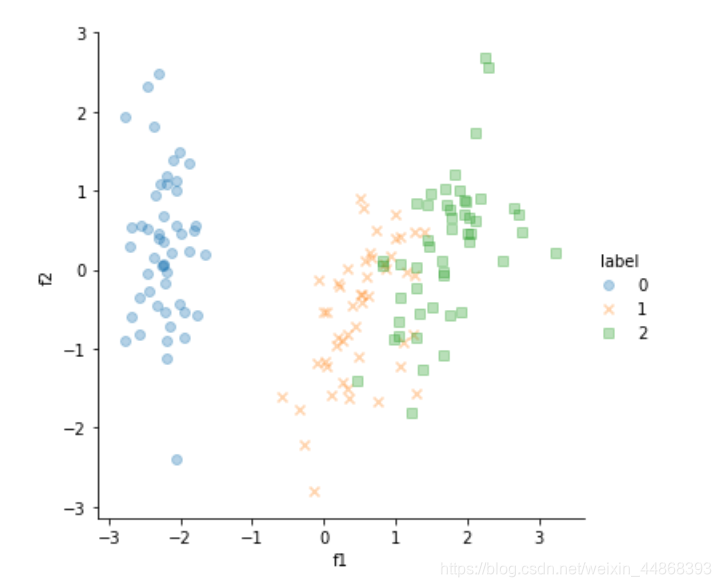
iris = pd.concat([pd.DataFrame(iris_PCA,columns=['f1','f2']),iris_label],axis=1)
sns.lmplot(x = "f1", y = "f2",data = iris ,hue = "label", fit_reg = False,markers=["o","x","s"], x_jitter = 0.2, y_jitter = 0.2, scatter_kws = {'alpha' : 1/3})

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)