
使用python统计《三国演义》人物词频,看看罗贯中笔下谁的出场次数最多
使用分词算法统计《三国演义》人物词频,看看谁是罗贯中心中最靓的仔。谁才是《三国演义》中出场次数最多的人。重新优化的其他案例的统计逻辑
·
“滚滚长江东逝水,浪花淘尽英雄”。近来读《三国演义》,忽然想看看到底哪位英雄在书中提到的最多,于是就想用分词算法实现一下。
网上也确实有相关的案例,作为参考,自己又重写并优化了一遍。
思路
- 下载《三国演义》txt文档
- 使用jieba分词算法对文档进行分词处理
- 将分词结果踢除停用词、标点符合、非人名等
- 词频统计、并排序
- 可视化展示
问题
按照上面的思路进行简单实施时,查看结果会发现几个问题
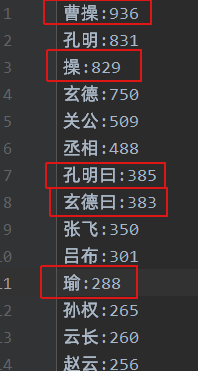
- 名字
- 三国人物有名、字、号等,还有其他的一些别称,如“相父”、“曹阿瞒“、刘皇叔”,要想办法统一成一个人
- 词性
- 比如“曰”、“大胜”等非人名的词不是我们需要统计的
- 分词
- 一些如“孔明曰”、“玄德问”、“操大怒”之类的词没有被分割开
- 干扰词
- 分词后会出现像“诸公”、“齐声”、“班师回”等明显,但是算法无法判断的非人名词语,干扰排序结果
所以对这些情况要进行特殊处理。
优化
- 针对名、字、号的问题进行枚举判断。网上的案例中大多采用如
w.word == '玄德'这种等号判断,但对于 “玄德遂”、“操乃”等分词不准确情况枚举不足。比如我们在文本里统计“操”字有2800多个,基本都是指代曹操,而用阿瞒、孟德、曹丞相等枚举等号判断时,最终统计的“曹操”词频只有1000多个,所以我采用的是包含判断,即'操' in w.word、'孟德' in w.word。 - 词性踢除。通过w.flag将nr(人名)外的其他词性踢除掉,这一步很多案例中是放在人物名字号的判断前,但是“玄德”会被当成x(未知词性),这样就会少算很多姓名,所以我放在了人物名字判断后,再踢除无关词性。
- 对于词性为nr但是非人名的词,则需要在停用词的基础上,增加一张踢除干扰词的自定义文件
结果
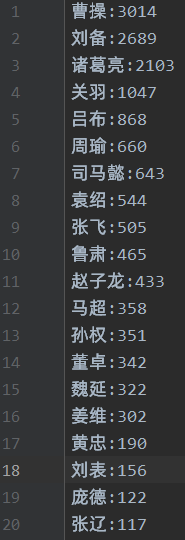
经过以上处理后,基本排除了干扰,最后就是激动人心的时刻,那么谁才是罗贯中心中的南波万呢?
当当当当,那就是这位“可爱的奸雄”——曹操。
曹操:3014
刘备:2689
诸葛亮:2103
关羽:1047
吕布:868
周瑜:660
司马懿:643
袁绍:544
张飞:505
鲁肃:465
赵子龙:433
马超:358
孙权:351
董卓:342
魏延:322
姜维:302
黄忠:190
刘表:156
庞德:122
张辽:117
再来一张拉风的三国词云
说明:该处理结果只对排名靠前的刘备、诸葛亮、曹操、关羽、张飞、吕布、司马懿等人物的分词结果进行了优化(见代码),其他诸如魏延、庞统、庞德等不影响第一排名的人物,名、字、号问题未进行详细处理。
附代码
import jieba.posseg as pseg
import jieba
import re
import matplotlib.pyplot as plt
import codecs
# 词云
import wordcloud
import imageio
# 定义主要人物的个数
keshihuaTop=10 # 可视化人物图人数
mainTop = 100 # 人物词云图人物数
peopleTop=10 # 人物关系图
# 获取图书数据
def get_book(file_path):
fn = open(file_path,encoding='utf-8')
stringdata = fn.read()
fn.close()
return stringdata
# 文本处理
def bookdata_process(bookdata):
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"')
book_str = re.sub(pattern,'',bookdata)
print('文本预处理完成')
return book_str
# 获取停用词
def stop_word_list(file_path):
stopwords = [line.strip() for line in open(file_path,'r',encoding='utf-8').readlines()]
return stopwords
# 获取词频
count = {}
# 获取词频
def getWordTime(txt,stopWordList,wordFlagList):
jieba.load_userdict("prepare/userword.txt")
cutfinal = pseg.cut(txt)
for w in cutfinal:
if w.word == None or w.word in stopWordList:
continue
elif '刘玄德' in w.word or '玄德' in w.word or '刘豫州' in w.word or'备' in w.word or '大耳贼' in w.word \
or '先主' in w.word or '刘皇叔' in w.word or '皇叔' in w.word or '大耳' in w.word or '玄德公' in w.word \
or '汉中王'in w.word or '刘备' in w.word:
real_word = '刘备'
elif '孔明' in w.word or '卧龙' in w.word or '卧龙先生' in w.word or'亮' in w.word or '武侯' in w.word \
or '武乡侯' in w.word or '诸葛丞相'in w.word or '相父' in w.word or '诸葛孔明' in w.word or '诸葛亮' in w.word:
real_word = '诸葛亮'
elif '曹孟德' in w.word or '曹公' in w.word or '曹贼' in w.word or'操' in w.word or '曹丞相' in w.word \
or '曹操'in w.word or '魏公'in w.word or '魏王' in w.word or '阿瞒'in w.word or '曹阿瞒' in w.word \
or '孟德' in w.word or '操军' in w.word:
real_word = '曹操'
elif '关云长' in w.word or '云长' in w.word or '关二爷' in w.word or'关公' in w.word or '关将军' in w.word \
or '美髯公'in w.word or '汉寿亭侯' in w.word or '关云' in w.word or '关某' in w.word:
real_word = '关羽'
elif '赵云' in w.word or '子龙' in w.word or '常山' in w.word or '赵将军' in w.word:
real_word = '赵子龙'
elif '张翼德' in w.word or '三弟' in w.word or '翼德' in w.word or '张翼' in w.word:
real_word = '张飞'
elif '吕奉先' in w.word or '奉先' in w.word or '布' in w.word or '吕将军' in w.word or '三姓家奴' in w.word:
real_word = '吕布'
elif '卓' in w.word or '仲颖' in w.word or '董老贼' in w.word:
real_word = '董卓'
elif '瑜' in w.word or '公瑾' in w.word or '周郎' in w.word:
real_word = '周瑜'
elif '仲达' in w.word or '司马仲达' in w.word or '懿' in w.word:
real_word = '司马懿'
elif '刘景升' in w.word or '景升' in w.word:
real_word = '刘表'
elif '超' in w.word or '孟起' in w.word or '马孟起' in w.word:
real_word = '马超'
elif '阿斗' in w.word:
real_word = '刘禅'
elif '仲谋' in w.word or '吴王' in w.word or '吴主孙权' in w.word:
real_word = '孙权'
elif '袁本初' in w.word or '本初' in w.word or '绍' in w.word:
real_word = '袁绍'
elif '肃' in w.word or '子敬' in w.word or '子敬' in w.word:
real_word = '鲁肃'
elif '伯约' in w.word:
real_word = '姜维'
elif '瓒' in w.word:
real_word = '公孙瓒'
elif (len(wordFlagList)>0 and w.flag not in wordFlagList):
# print(w.word + w.flag)
continue
else:
real_word = w.word
count[real_word] = count.get(real_word,0) + 1
# 分词生成人物词频(写入文档)
def writeWordResult(items,sinkPath,topN):
with codecs.open(sinkPath, "w", "utf-8") as f:
if len(items) < topN:
topN = len(items)
for i in range(topN):
word, count = items[i]
f.write("{}:{}\n".format(word, count))
# 生成词云
def creat_wordcloud(excludes):
bg_pic = imageio.imread('prepare/sanguo.jpg')
wc = wordcloud.WordCloud(font_path='prepare/simhei.ttf',
background_color='white',
width=1000, height=800,
stopwords=excludes,# 设置停用词
max_words=500,
mask=bg_pic # mask参数设置词云形状
)
# 从单词和频率创建词云
wc.generate_from_frequencies(count)
# 保存图片
wc.to_file('output/三国演义词云_人名.png')
# 显示词云图片
plt.imshow(wc)
plt.axis('off')
plt.show()
if __name__ == '__main__':
excludes = stop_word_list("prepare/exclude.txt")
stopwordlist = stop_word_list("prepare/tingyong.txt") + excludes
bookdata = get_book("prepare/sgyy.txt")
txt = bookdata_process(bookdata)
# 设置词性--nr:人名
# 玄德会被识别为未知词性(x)
# 亮、操会被识别为动词(v)
# 云会被识别为地名(ns)
wordFlagList = {'nr'}
getWordTime(txt,stopwordlist,wordFlagList)
items = list(count.items())
# 进行降序排列 根据词语出现的次数进行从大到小排序
items.sort(key=lambda x: x[1], reverse=True)
sink_path = "output/sanguo_word_count.txt"
writeWordResult(items,sink_path,300)
creat_wordcloud(excludes)
相关附件下载
sgyy.txt 三国演义txt文件
excludes.txt 干扰词文件
tingyong.txt 汉语停用词
sanguo.jpg 三国词云底图
simhei.ttf字体可到电脑C:\Windows\Fonts字体库下自行复制

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 32
32 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)