深度学习入门(看了就会)
什么是深度学习呢?简单来说就是当你拥有一个数据集的时候,若你想处理它,可能你的反应是for遍历一遍。但深度学习是不需要的。首先介绍一下深度学习的一些基本概念。对于一张图片的储存,是分为了三个二维数组,分别是红绿蓝三个颜色。而我们是将这三个二维数组中的数据全部放到一个列向量中。也就是说,若三个64×64的数组,那列向量x中的元素就是64×64×3个。x作为深度学习的输入,输出我们用y来表示,y的取值
什么是深度学习呢?
简单来说就是当你拥有一个数据集的时候,若你想处理它,可能你的反应是for遍历一遍。但深度学习是不需要的。
首先介绍一下深度学习的一些基本概念。
对于一张图片的储存,是分为了三个二维数组,分别是红绿蓝三个颜色。
而我们是将这三个二维数组中的数据全部放到一个列向量中。也就是说,若三个64×64的数组,那列向量x中的元素就是64×64×3个。x作为深度学习的输入,输出我们用y来表示,y的取值是0/1,0表示识别失败,1表示成功。
通常用n表示x维度(上述中n为64643),用m表示训练集的个数.。用X作为整个深度学习的输入,X是m个x组成的n行m列的数组。在python中通常用X.shape输出X的维度,即(n,m)。同理,将输出表示为Y,由m个y组成,Y.shape输出Y的维度(1,m)。
**
logistic回归
**
对于输入X,我们想知道他的输出Y,通常情况下会得到一个Y’,表示它是否满足结果的概率。
已知w是logistic函数的参数,也是n维向量,b就是个实数。
Y’ = w(转置) * x + b , 而对于Y‘ 我们希望它是个零到一之间的数,所以还需要用 sigmoid函数,即Y’ = σ(w(转置) * x + b)。
将括号里面的设为z,可得到z的sigmoid图像: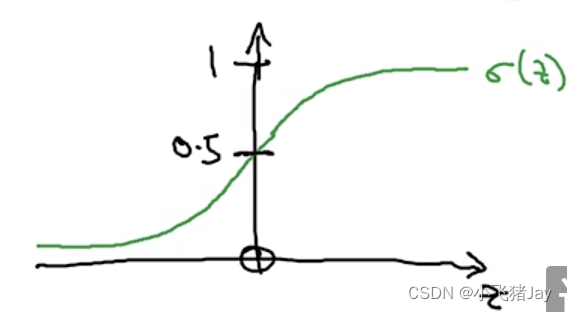
其中σ(z) = 1 / (1 + e^(-z) ),
可以看出,z越大,sigmoid(z)越接近1;相反,z越小或是越负数,sigmoid(z)就越接近0。
因此,当你做logistic回归时,你要做的就是学习参数w和b,所以Y’ 就变成了对Y较好的估计。
有时候,会用θ(一个0到n的向量),其中θ(0)就是b,θ(1)到θ(n)就是w。
定义一个损失函数,表示Y’ 和Y 之间的误差。在logistic中定义误差函数为δ(Y’ , Y) = -(y*logy’ + (1-y)*log(1-y’)) , 越小越好。
损失函数是在单个训练样本中定义的,成本函数衡量的是在全体训练样本上的表现。
成本函数J(w , b) = 1/mΣ δ(y’(i) , y(i) )
也就是:J(w , b) = -1/mΣ(y*logy’ + (1-y)*log(1-y’))
上面我们提到过,我们要做的就是找到好的参数w和b,所谓好的w和b就是指让成本函数J(w , b)较小的w和b。而这里的J是凸函数,所以是可以保证存在w和b使J有最小值。
【注:这里可能有同学忘记凸函数是啥了,想知道概念的话翻翻高数书就OK了。这里你只需要知道,如果优化的目标函数是凸函数,则局部极小值就是全局最小值。这也意味着我们求得的模型是全局最优的,不会陷入到局部最优值。】】
J的函数图像: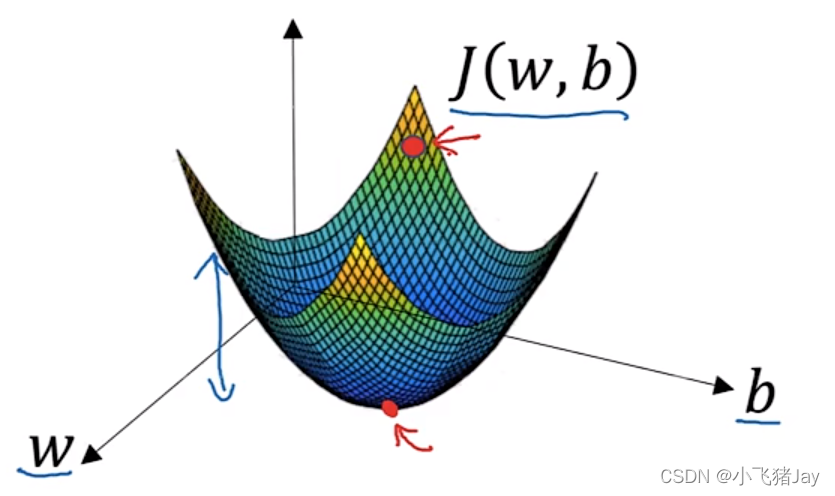
可以看到J(w,b)像个碗一样,碗底的红点就是他的最小值,对应的w和b就是我们要找的。通常情况下都是给他初始化,再进行一步步逼近。但是从他的图像可以发现,无论从哪一个点初始化,最终都会得到碗底的那个点。
梯度下降法:
在logistic回归函数中我们使用梯度下降法来寻找w和b。通俗的来讲,梯度下降法就是从某一点开始,沿着当前最陡的坡面下降,迭代多次之后就会找到最优解。
当我们忽略b只看w的时候,图像大概是一个二维的这样的: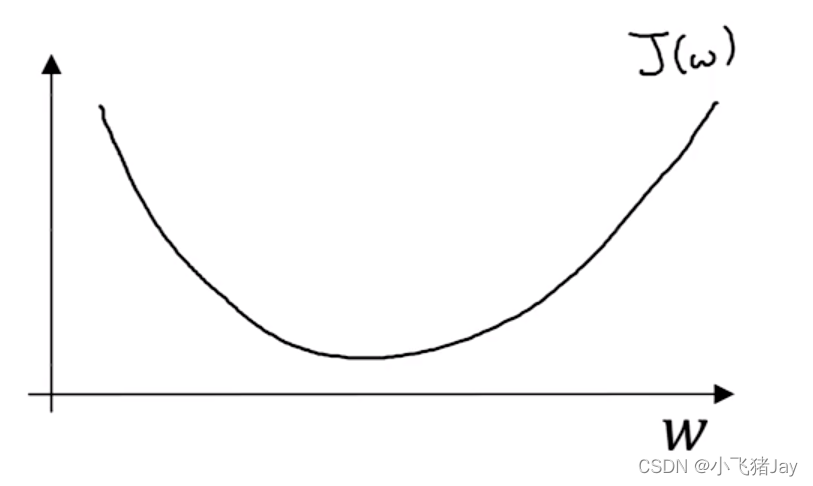
我们会按照如下的方法来进行w的迭代:
w := w - α(dJ / dw),α表示的是学习率,下面会详细介绍如何选择α,它的作用就是控制每一次迭代,或者梯度下降法的步长。括号中的其实就是函数J关于w的导数,理解了之后代码实现中我们都用dw来进行表示,即w := w - α(dw)。
因此,
w := w - α(dJ(w , b) / dw)
b := b - α(dJ(w , b) / dw)
向量化,它的作用可以理解为消除代码中的显式for循环语句,可以极大地缩短时间。
补充一个看论文的常见的标语:
FLOPS(全大写) :是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs(s小写) :是floating point operations的缩写(s表示复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)