蛋白质功能预测中PSSM矩阵的生成
生成PSSM矩阵
一、蛋白质功能预测
蛋白质功能预测
近年来高通量实验方法快速发展,随之产生大量新型蛋白质,发现的蛋白质数量与其功能注释之间的差距越来越大,蛋白质功能预测成为分子生物学研究领域的核心问题。传统的蛋白质功能预测方法耗时且昂贵,依靠单一数据源的特征信息表达不全面,因此如何选用合适的机器学习方法,构建有效的模型来融合多种生物数据,对预测蛋白质功能具有重要意义。
蛋白质功能预测通常被视为多标签分类问题,当前用于蛋白质功能预测的最新方法是使用机器学习技术来训练分类器,这些技术是基于大量网络、序列和基因表达等多种数据源进行预测。机器学习模型的应用离不开数据和算法,但是原始数据往往不能直接应用在模型中进行训练,通常需要特征向量化。受到受到氨基酸序列排列顺序及其折叠形成的空间结构影响,蛋白质蕴含不同的理化性质,体现出复杂多样的生物学功能,进而影响生命活动机制。
研究人员挖掘氨基酸特性的角度存在多样化,故能从序列中得到的生物信息也不同。近些年的研究表明,序列特征表示方法大多从氨基酸组成、氨基酸理化性质、进化信息等生物本质或者深度学习的角度提取想要的信息。本文主要介绍位置特异性打分矩阵 (Position-Specific Scoring Matrix, PSSM)是 Gribskov 等人首次在实验中采用的序列特征表示方法。对比其他序列特征提取方法,一级结构的进化信息借助PSSM得到有效表达,使得蛋白质分配功能注释、预测蛋白质结构、蛋白质结合位点预测等多类生物学研究取得一定的进步。PSSM通过序列相似性比对生成,将氨基酸的保守性信息包含在矩阵中。
二、PSSM矩阵
PSSM矩阵全称是“position-specific scoring matrix”,翻译为中文是“位置特异性打分矩阵”,也被称为“位置权重矩阵”(position weight matrix,PWM)、“位置特定权重矩阵”(position-specific weight matrix,PSWM),是生物序列中基序(模式)的常用表现形式。对于氨基酸和核苷酸,矩阵的形式不太一样,根据维基百科的解释,DNA(或RNA)序列对应的PSSM矩阵的行数为4,对应着四种不同的核苷酸;蛋白质序列的PSSM矩阵的行数为20,对应着二十种氨基酸。不过二者的PSSM的列数均为序列长度。(注:在使用软件生成的PSSM矩阵中,恰好相反,列数分别为固定的4或20,行数为序列长度。)如下图所示:
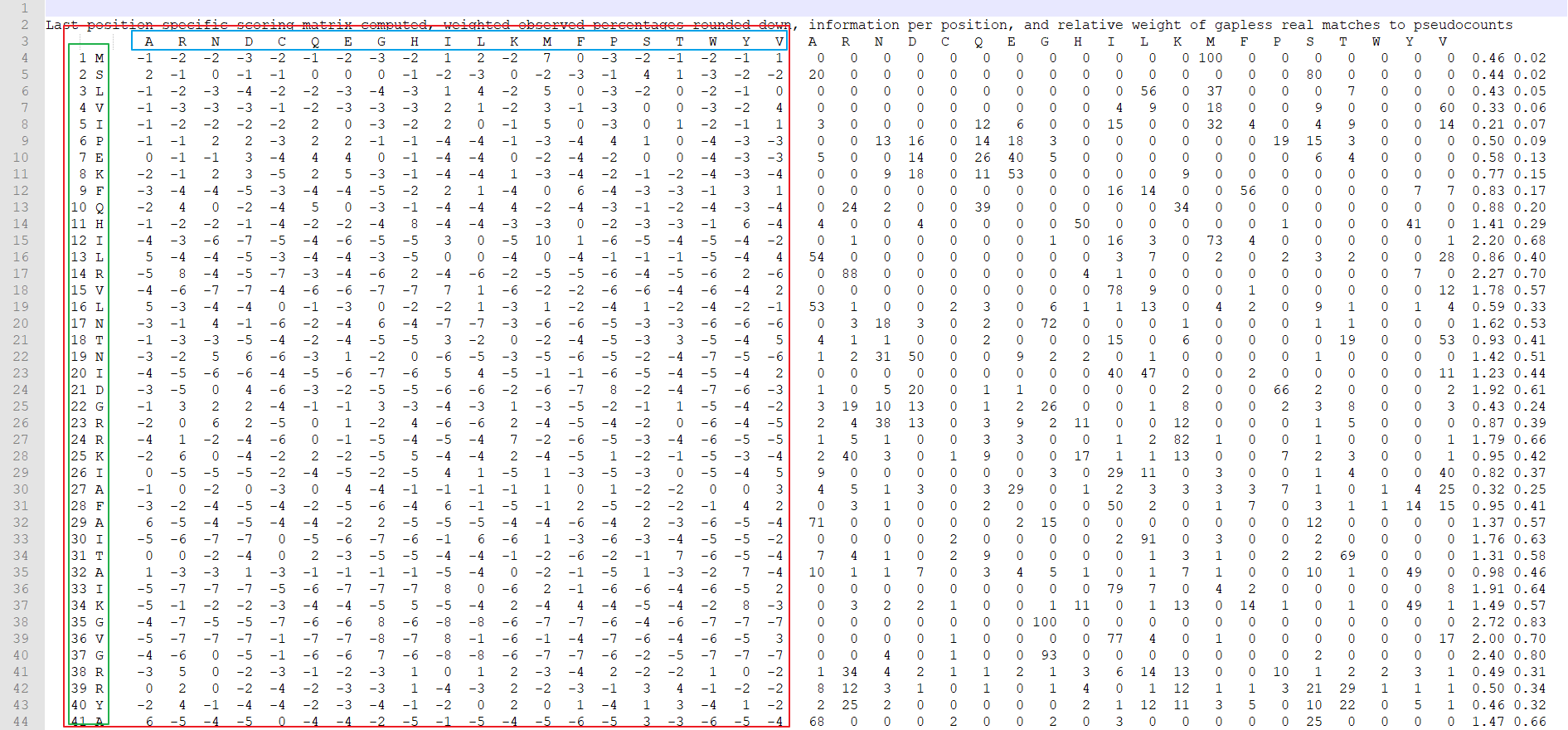
图中所示的就是一个具体的蛋白质序列生成的PSSM矩阵,通常来说我们只关注红框中的内容,后面的内容不做过多关注。红框中的内容是一个L*20维的矩阵,L代表着蛋白质序列的长度(图中绿色部分),20代表着20中氨基酸(图中蓝色部分)。
对于其中的数字,十分常见的一个解释是:对于PSSM中的一个元素Pij,其数值表示序列第i个位置上的氨基酸在进化过程中突变成第j个氨基酸的可能性,若值为正,就表示可能性越大;反之则表示可能性越小。
接下来介绍使用BLAST软件生成PSSM矩阵的过程,推导过程可看这篇文章:PSSM(一)-什么是PSSM – Ayanokouji Monki的博客
三、生成PSSM矩阵
生成序列文件
在UniPort网页中搜索蛋白质名称,并从中下载包含序列等信息的fasta文件,只读取其中的序列并生成单独的序列文件。(在使用BLAST软件生成PSSM时,文件中只能包含一条序列)
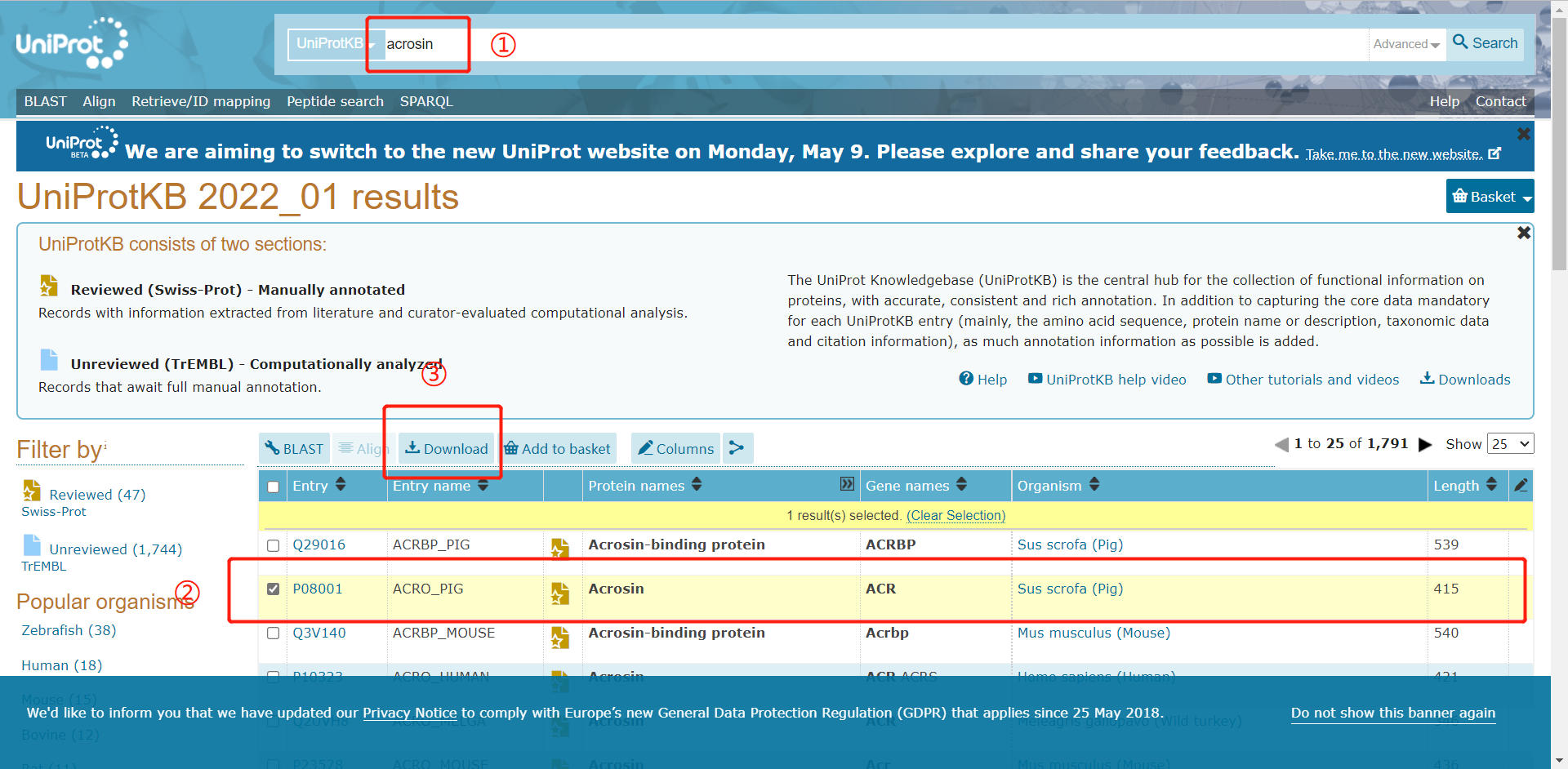
fasta文件格式

下载与安装BLAST
在Windows下下载适合的BLAST版本并配置相应的环境变量。下载地址为:Index of /blast/executables/blast+/LATEST (nih.gov)。我的主页提供了已经下载好的2.13.0版本的BLAST,下载完成后双击进行安装。
安装完成后需要配置环境变量,在系统变量下方“Path”添加变量值,路径写到安装BLAST软件的bin目录下。例如E:\BLAST\blast-BLAST_VERSION+\bin。
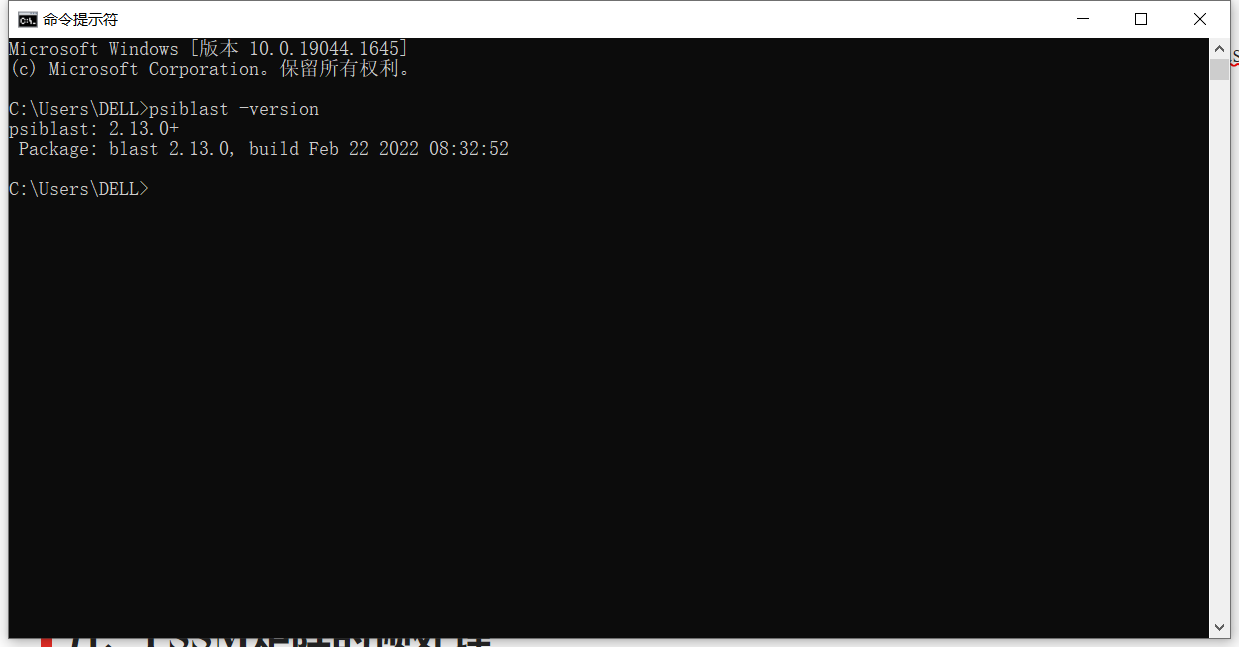
若想要查看是否安装成功,可以点击window的“开始”菜单,输入cmd,打开DOS命令行模式,输入psiblast -version命令来查看安装的版本信息,若能查询到,则代表成功安装。
构建BLAST本地数据库
我们需要首先下载数据库并对其解压,数据库的下载地址为:Index of /blast/db (nih.gov)。通常情况会选择SwissProt数据库、nr数据库等,但nr数据库是一个非冗余的蛋白质序列数据库,整个nr数据库大约上百G,构建本地数据库非常耗时,故通常选择SwissProt数据库。
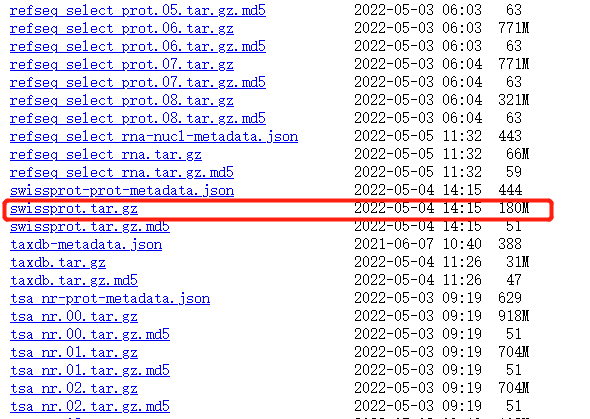
下载好数据库后,在blast文件夹下创建一个db文件夹,存放解压后的数据库文件。解压后在DOS命令行运行格式化数据库的命令:makeblastdb -in swissprot -dbtype prot -title “swissprot” -out sp。这样就完成了本地数据库的建立。(最新下载下来的数据库文件解压后好像可以直接使用,不用在DOS命令行执行操作,大家可以跳过此步。)
①-in:后面跟要格式化的数据库
②-dbtype:后跟所格式化的序列的类型,nucl指的是核酸,prot指的是蛋白质

生成PSSM
应用PSI-BLAST读取每个蛋白质对应的氨基酸序列,生成相应的位置特异性打分矩阵。此命令是:psiblast -query 蛋白质序列所在位置 -db 数据库所在位置 -evalue 0.001 -num_iterations 3 -out_ascii_pssm 输出pssm文件的位置。注意:当文件路径中出现空格时,一定要用双引号将路径引起来。例如:
psiblast -query "F:\Protein Prediction SVM\Data\aa.fasta" -db E:\BLAST\blast-BLAST_VERSION+\db\swissprot -evalue 0.001 -num_iterations 3 -out_ascii_pssm C:\Users\DELL\Desktop\ttttt.pssm
参数列表:
①-query:后面跟需要比对的序列位置,文件必须为fasta格式
②-num_iterations:迭代次数,一般选择3次
③-db:后面跟本地数据库的位置
④-out_ascii_pssm:如果需要生成PSSM矩阵,则需要输入此参数,参数后面跟pssm矩阵的名字,可任意取名
⑤-evalue:期望阈值,一般选择0.001
经过以上的步骤,便可以生成一个L*20维的PSSM,但是通过DOS命令行的方式,一次只能为一条蛋白质序列生成PSSM,效率非常底下,故可以选择使用Python程序来实现自动为任意条序列生成PSSM的工作。
四、Python实现批量生成PSSM矩阵
先放代码,然后解释。(本人Python不是特别熟悉,故实现时没有考虑效率问题,大家如果有什么建议,还请发表在评论区相互学习)
import os
import re
import codecs #或者io,使用哪种包无所谓
import pandas as pandas
def Get_PSSM(species_id):
df = pandas.read_excel(r'../Data/'+str(species_id)+'.xlsx', engine='openpyxl')
for i in range(0, df.shape[0]) :
f = open(r'../Data/Temporary.fasta', 'w')
f.write(df.values[i][1])
f.close()
os.system('psiblast -query "F:\Protein Prediction SVM\Data\Temporary.fasta"' + ' -db E:\BLAST\\blast-BLAST_VERSION+\db\swissprot -evalue 0.001 -num_iterations 3' + ' -out_ascii_pssm "F:\Protein Prediction SVM\Data\\'+str(species_id)+'\\' + str(df.values[i][0]) + '.pssm"')
print("step_1:所有PSSM矩阵构建成功")
我是将一个物种的所有蛋白质名称及序列利用爬虫技术获取到以后,存在一个名为该物种ID的Excel表格中,然后依次读取表格中的每一行内容,将序列数据放到一个临时的fasta文件中,然后生成该序列对应的PSSM,每一个PSSM的名称都是对应序列的蛋白质的名称。
注意事项
①一些过短的蛋白质序列是没有办法在swissprot数据库中完成搜索,并生成PSSM的,一般长度在15以下就无法生成了,可以选择更换nr数据库进行尝试。
②使用PSI_BLAST生成的PSSM是一个L*20维的矩阵,并不是一个固定长度。但是基于机器学习或其他方法,通常是需要使用相同长度的特征向量进行训练,所以还需要对不同大小的PSSM矩阵进行信息提取和归一化处理,大家可以上网搜索相关的论文。
如何生成PSSM矩阵就介绍到这里啦,大家有什么问题可以在评论区讨论!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用

所有评论(0)