
【Python网络爬虫】前程无忧网爬虫+可视化
文章目录前言一、页面分析二、代码实现前言本文以前程无忧网的爬虫职位为例,通过面向对象的形式进行编码,利用requests库发起请求,利用xpath与正则表达式进行数据解析,将最终结果存入Excel中,最后对数据进行统计并可视化。一、页面分析首先进入爬取的目标页面:前程无忧网爬虫职位信息城市名城市编号全国000000北京市010000上海市020000广州市030200深圳市040000武汉市180
前言
本文以前程无忧网的爬虫职位为例,通过
面向对象的形式进行编码,利用requests库发起请求,利用xpath与正则表达式进行数据解析,将最终结果存入Excel中,最后利用pyecharts对数据进行统计并可视化(截图模糊但实际效果清晰)。
一、页面分析
-
首先进入前程无忧网首页:https://www.51job.com/
-
在搜索框中输入”爬虫“,点击搜索。
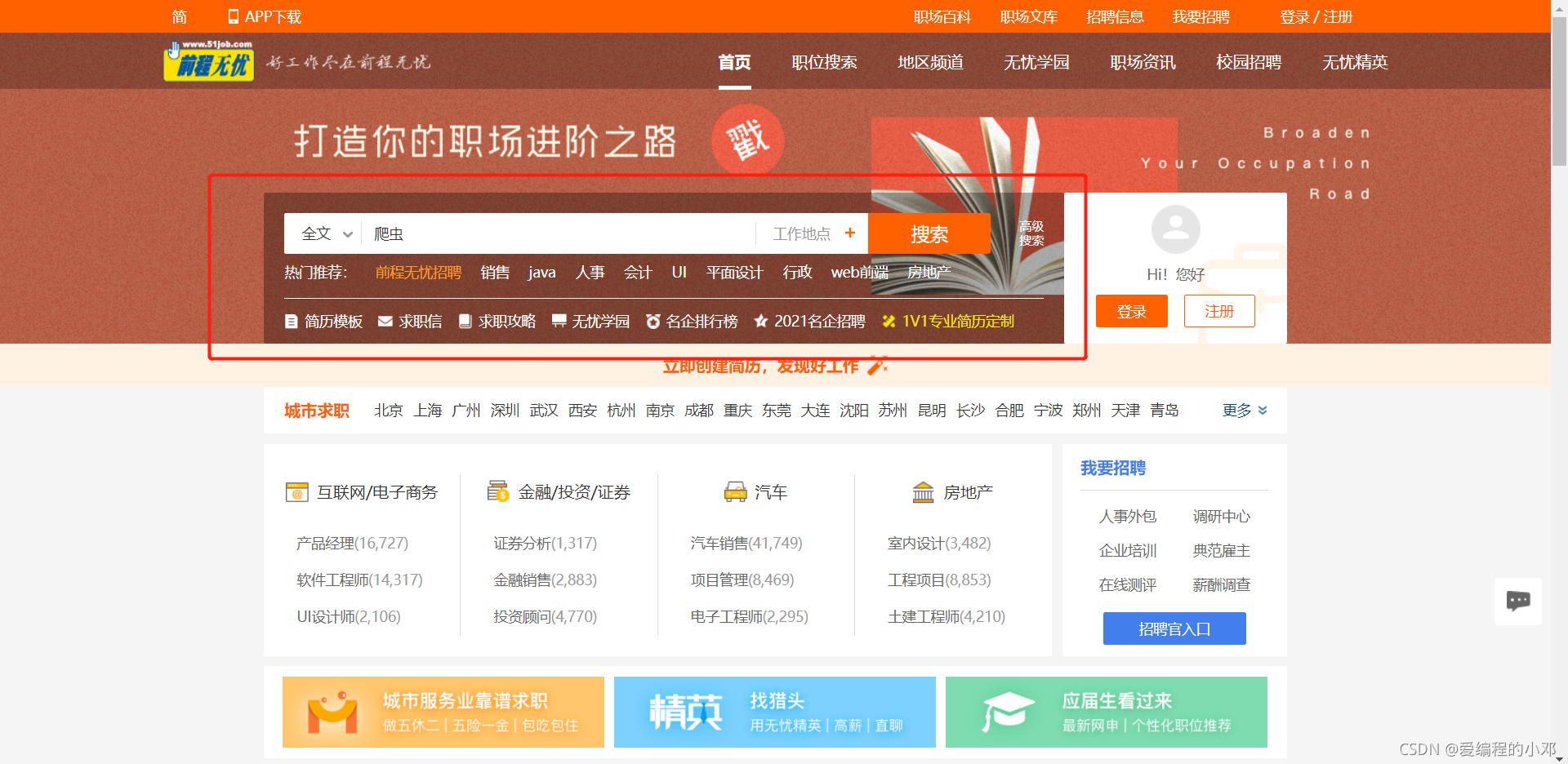
-
返回的页面如下。
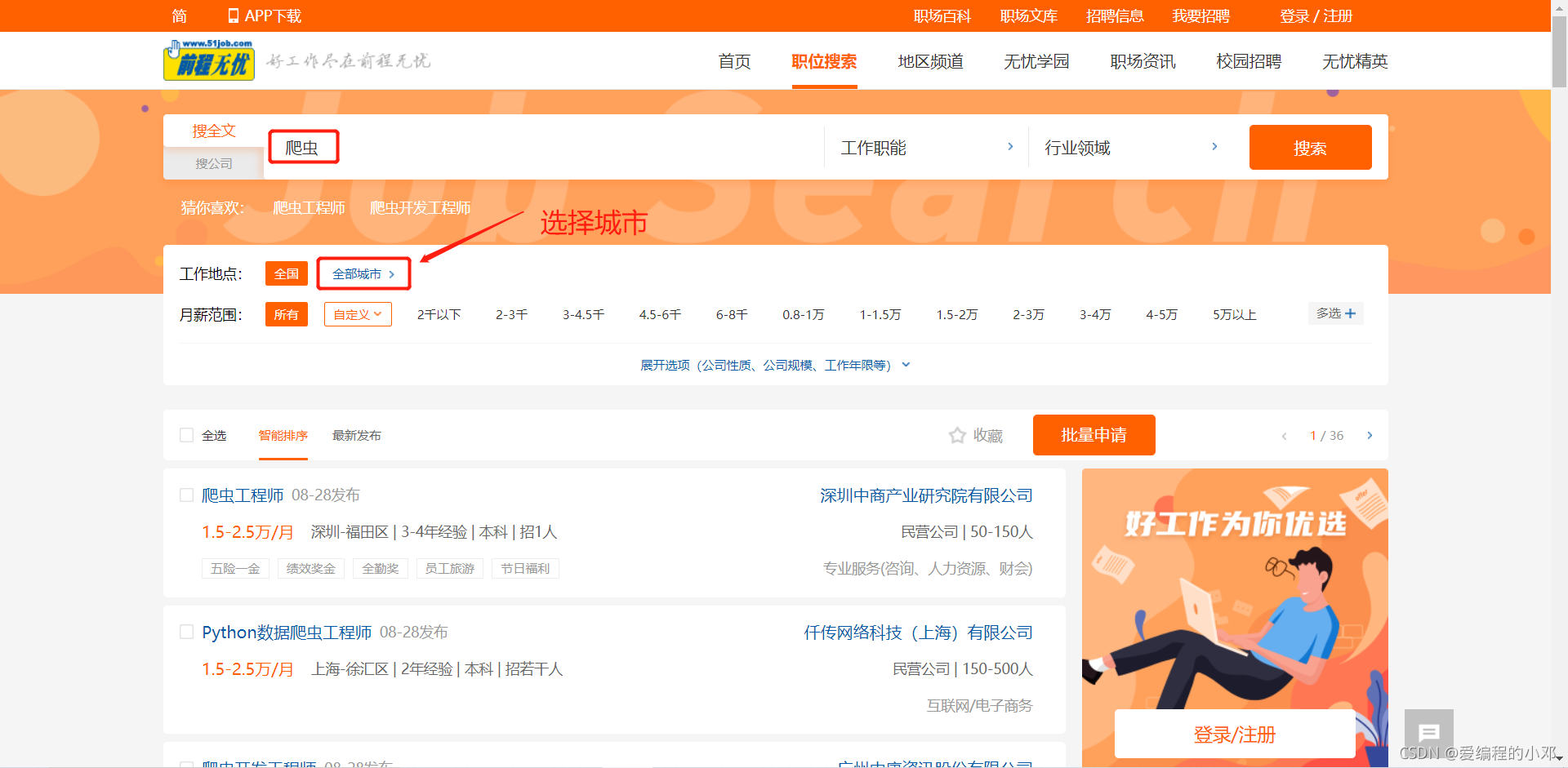
-
通过在搜索框中搜索不同关键词,页面下方导航栏改变页数,以及选择不同城市,通过观察网页URL可以发现如下规律,由于URL的查询字符串部分完全一致,所以下图中未显示。(下图URL为全国爬虫职位第一页的URL)

-
下表为中国主要城市的编号。
| 城市名 | 城市编号 |
|---|---|
| 全国 | 000000 |
| 北京市 | 010000 |
| 上海市 | 020000 |
| 广州市 | 030200 |
| 深圳市 | 040000 |
| 武汉市 | 180200 |
| 西安市 | 200200 |
| 杭州市 | 080200 |
| 南京市 | 070200 |
| 成都市 | 090200 |
| 重庆市 | 060000 |
| 东莞市 | 030800 |
| 大连市 | 230300 |
| 沈阳市 | 230200 |
| 苏州市 | 070300 |
| 昆明市 | 250200 |
| 长沙市 | 190200 |
| 合肥市 | 150200 |
| 宁波市 | 080300 |
| 郑州市 | 170200 |
| 天津市 | 050000 |
| 青岛市 | 120300 |
| 济南市 | 120200 |
| 哈尔滨市 | 220200 |
| 长春市 | 240200 |
| 福州市 | 110200 |
-
由于无法直接获得职位信息的总页数,所以只能通过尝试发现,全国爬虫职位信息共36页。同时职位编码可以利用程序进行转换。
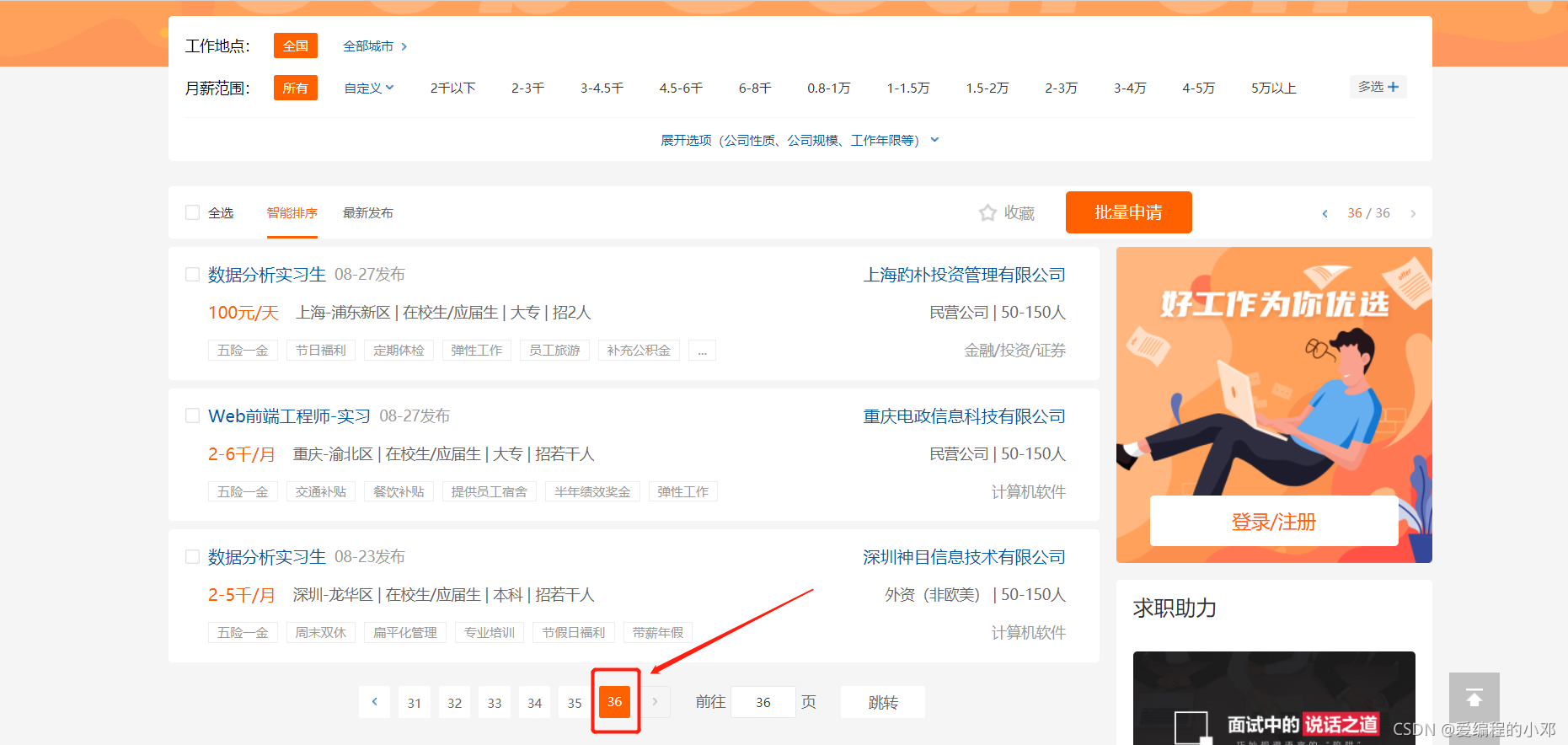
-
通过以上分析可以得到模板URL,通过改变相应位置的参数即可改变搜索条件,其他位置的参数感兴趣的小伙伴可以自行研究。
-
到此网页的URL分析完成,下面解决数据提取问题。通过观察发现,服务器返回的网页源代码,与在开发者工具(F12)中的网页源代码不同,原因是由于浏览器呈现的数据是由JS通过浏览器二次渲染得到的,所以数据要在JS代码中获取。
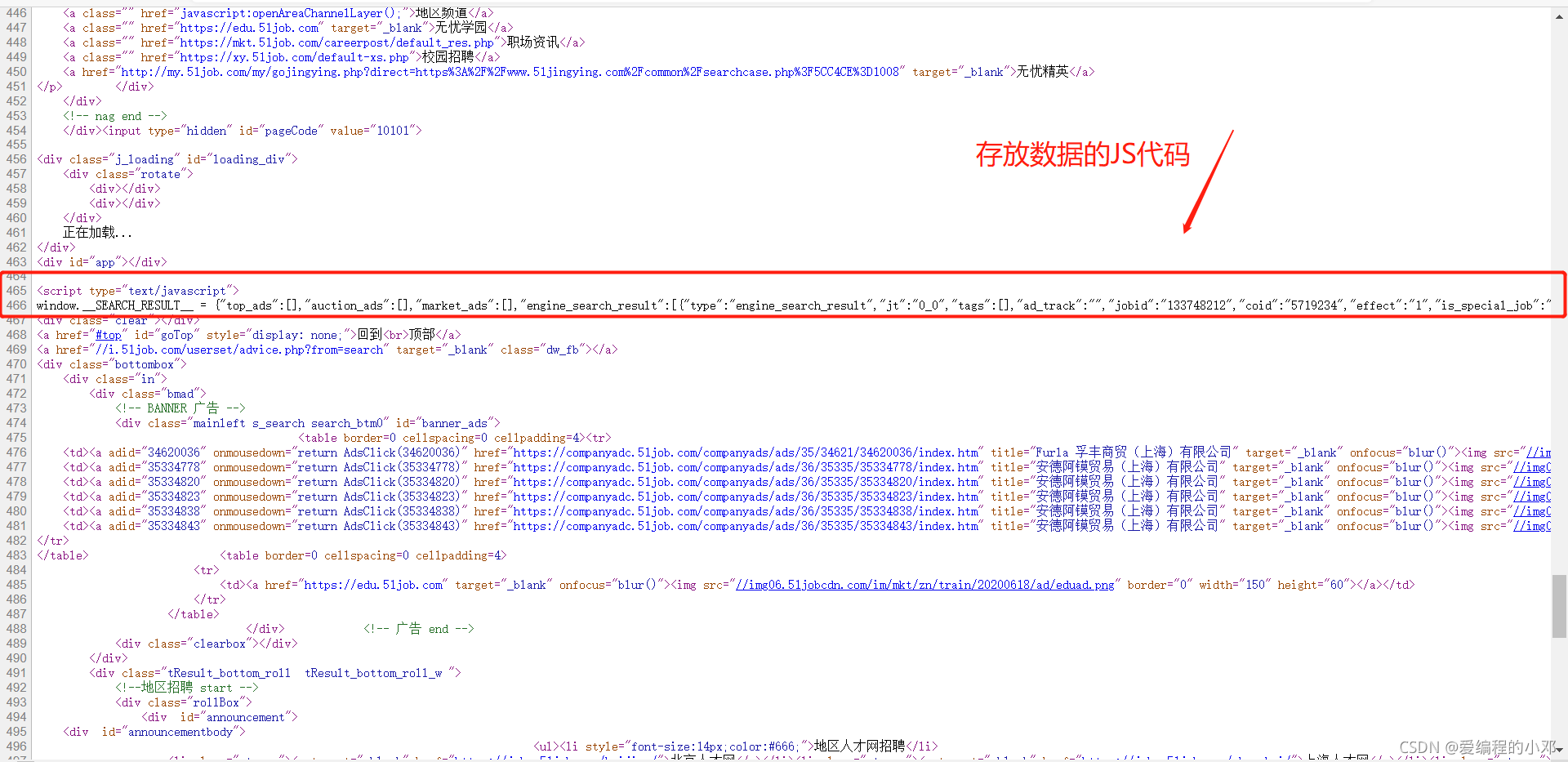
-
经过xpath和正则表达式提取之后,可以看到数据的存储形式。每页返回一个列表,列表含有若干个下图所示的字典。这样就可以提取到想要的数据。
{
"type":"engine_search_result",
"jt":"0_0",
"tags":[
],
"ad_track":"",
"jobid":"133748212",
"coid":"5719234",
"effect":"1",
"is_special_job":"",
"job_href":"https:\/\/jobs.51job.com\/shenzhen-ftq\/133748212.html?s=sou_sou_soulb&t=0_0",
"job_name":"爬虫工程师",
"job_title":"爬虫工程师",
"company_href":"https:\/\/jobs.51job.com\/all\/co5719234.html",
"company_name":"深圳中商产业研究院有限公司",
"providesalary_text":"1.5-2.5万\/月",
"workarea":"040100",
"workarea_text":"深圳-福田区",
"updatedate":"08-28",
"iscommunicate":"",
"companytype_text":"民营公司",
"degreefrom":"6",
"workyear":"5",
"issuedate":"2021-08-28 09:02:13",
"isFromXyz":"",
"isIntern":"",
"jobwelf":"五险一金 绩效奖金 全勤奖 员工旅游 节日福利",
"jobwelf_list":[
"五险一金",
"绩效奖金",
"全勤奖",
"员工旅游",
"节日福利"
],
"isdiffcity":"",
"attribute_text":[
"深圳-福田区",
"3-4年经验",
"本科",
"招1人"
],
"companysize_text":"50-150人",
"companyind_text":"专业服务(咨询、人力资源、财会)",
"adid":""
},
二、代码实现
import urllib.parse
import random
import requests
from lxml import etree
import re
import json
import time
import xlwt
class QianChengWuYouSpider(object):
# 初始化
def __init__(self, city_id, job_type, pages):
# url模板
self.url = 'https://search.51job.com/list/{},000000,0000,00,9,99,{},2,{}.html'
# UA池
self.UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
# 请求头
self.headers = {
'User-Agent': random.choice(self.UApool),
# 注意加上自己的Cookie
'Cookie': '',
}
# 请求参数
self.params = {
"lang": "c",
"postchannel": 0000,
"workyear": 99,
"cotype": 99,
"degreefrom": 99,
"jobterm": 99,
"companysize": 99,
"ord_field": 0,
"dibiaoid": 0,
"line": '',
"welfare": ''
}
# 保存的文件名
self.filename = "前程无忧网" + job_type + "职位信息.xls"
# 城市编号
self.city_id = city_id
# 职位名称 【转为urlencode编码】
self.job_type = urllib.parse.quote(job_type)
# 页数
self.pages = pages
# 临时存储容器
self.words = []
# 请求网页
def parse(self, url):
response = requests.get(url=url, headers=self.headers, params=self.params)
# 设置编码格式为gbk
response.encoding = 'gbk'
# 网页源代码
return response.text
# 数据提取
def get_job(self, page_text):
# xpath
tree = etree.HTML(page_text)
job_label = tree.xpath('//script[@type="text/javascript"]')[2].text
# 正则表达式
job_str = re.findall('"engine_jds":(.*"adid":""}]),', job_label)[0]
# 转换为json类型
data = json.loads(job_str)
# 数据提取
for item in data:
# 职位名称
job_name = item['job_name']
# 职位链接
job_href = item['job_href']
# 公司名称
company_name = item['company_name']
# 公司链接
company_href = item['company_href']
# 月薪范围
salary = item['providesalary_text']
# 工作地点
address = item['workarea_text']
# 其他信息
info_list = item['attribute_text']
# 有个别数据不完整, 直接跳过
if len(info_list) < 3:
continue
# 经验要求
experience = info_list[1]
# 学历要求
education = info_list[2]
# 发布日期
update_date = item['updatedate']
# 公司性质
company_type = item['companytype_text']
# 公司福利
job_welf = item['jobwelf']
# 公司行业
company_status = item['companyind_text']
# 公司规模
company_size = item['companysize_text']
self.words.append({
"职位名称": job_name,
"公司名称": company_name,
"月薪范围": salary,
"工作地点": address,
"经验要求": experience,
"学历要求": education,
"发布日期": update_date,
"公司性质": company_type,
"公司福利": job_welf,
"公司行业": company_status,
"公司规模": company_size,
"职位链接": job_href,
"公司链接": company_href,
})
print("该页爬取完成")
# 数据保存
def save(self, words, filename, sheet_name='sheet1'):
try:
# 1、创建工作薄
work_book = xlwt.Workbook(encoding='utf-8')
# 2、创建sheet表单
sheet = work_book.add_sheet(sheet_name)
# 3、写表头
head = []
for k in words[0].keys():
head.append(k)
for i in range(len(head)):
sheet.write(0, i, head[i])
# 4、添加内容
# 行号
i = 1
for item in words:
for j in range(len(head)):
sheet.write(i, j, item[head[j]])
# 写完一行,将行号+1
i += 1
# 保存
work_book.save(filename)
print('数据保存成功')
except Exception as e:
print('数据保存失败', e)
# 主程序
def run(self):
for page in range(1, self.pages + 1):
# 拼接每页url
url = self.url.format(self.city_id, self.job_type, page)
# 请求网页
page_text = self.parse(url)
# 数据提取
self.get_job(page_text)
# 防止爬取过快
time.sleep(random.randint(1, 2))
self.save(words=self.words, filename=self.filename)
if __name__ == '__main__':
# 实例化爬虫对象 全国爬虫职位信息
# city_id:城市编号(上表)
# job_type:职位名称 (尽量精准,爬取到的数据会更贴切)
# pages:页数(自己指定,注意不要超过总页数)
spider = QianChengWuYouSpider(city_id=000000, job_type="爬虫", pages=20)
# 运行主程序
spider.run()
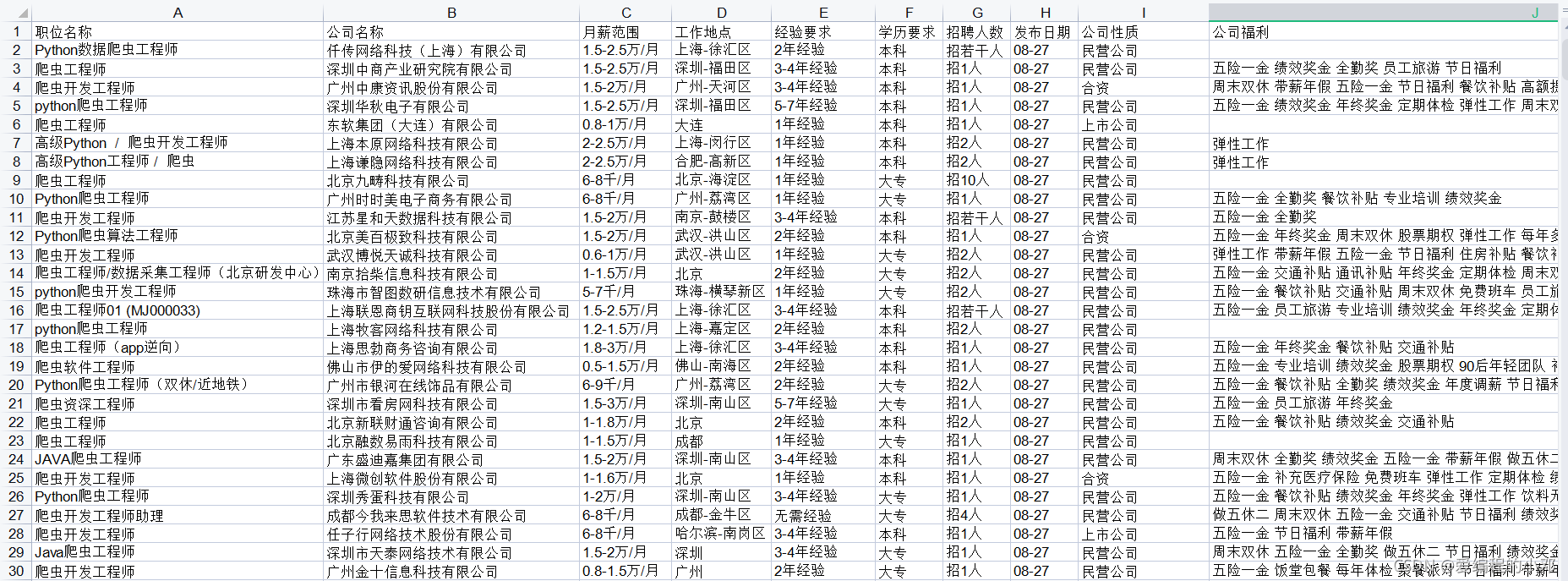
三、运行结果
四、数据统计及可视化
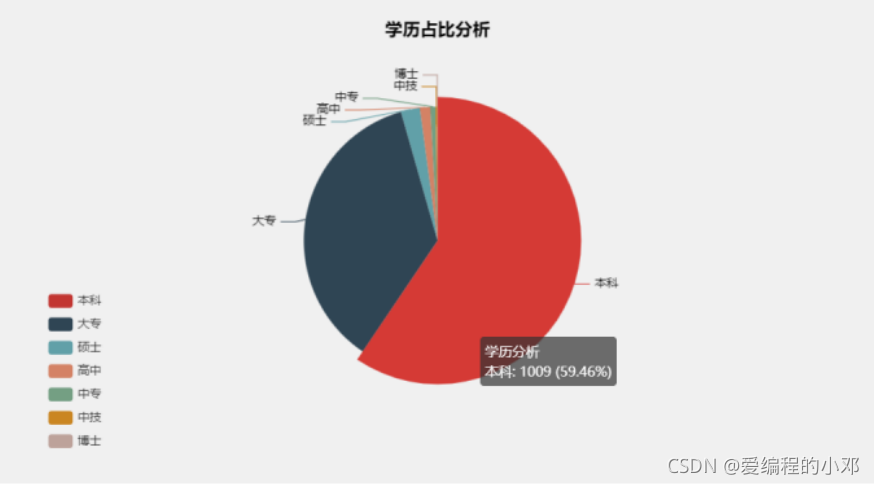
1.学历占比饼图
import pandas as pd
from pyecharts.charts import Pie
from pyecharts import options as opts
def education_analysis(data):
# 统计每种学历的人数
counts = data['学历要求'].value_counts()
l1 = counts.index.tolist()
l2 = counts.values.tolist()
# 数据格式整理
data_pair = [list(z) for z in zip(l1, l2)]
(
# 设置图标背景颜色
Pie(init_opts=opts.InitOpts(bg_color="rgba(206, 206, 206, 0.3)"))
.add(
# 系列名称,即该饼图的名称
series_name="学历分析",
# 系列数据项
data_pair=data_pair,
# 饼图的半径,设置成默认百分比,相对于容器高宽中较小的一项
radius="55%",
# 饼图的圆心,第一项是相对于容器的宽度,第二项是相对于容器的高度
center=["50%", "50%"],
# 标签配置项
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
# 全局设置
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(
# 名字
title="学历占比分析",
# 组件距离容器左侧的位置
pos_left="center",
# 组件距离容器上方的像素值
pos_top="20",
# 设置标题颜色
title_textstyle_opts=opts.TextStyleOpts(color="#000"),
),
# 图例配置项,参数 是否显示图里组件
legend_opts=opts.LegendOpts(
is_show=True,
# 竖向显示
orient="vertical",
# 距离左边5%
pos_left="5%",
# 距离上边60%
pos_top="60%",
),
)
# 系列设置
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# 设置标签颜色
label_opts=opts.LabelOpts(color="#000"),
)
.render(path="./output/01-学历占比图.html")
)
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 1.学历分析
education_analysis(data)
由该饼图可以发现,公司要求本科学历达到将近60%,本科+中专达到近95%。可以看到爬虫这项技术相对简单,门槛较低。
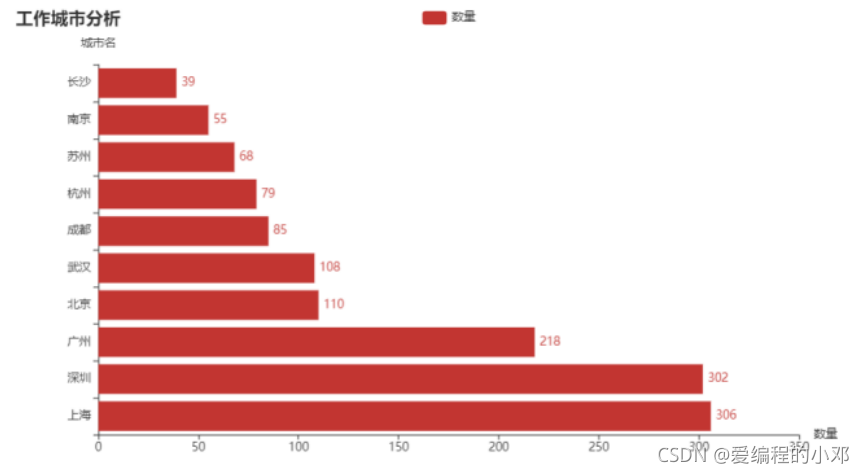
2.工作地点TOP10
import pandas as pd
import re
from pyecharts.charts import Bar
from pyecharts import options as opts
# 只保留城市名 不统计区
# 例:上海-徐汇区 -> 上海
def city_cleaning(df, loc):
# 对指定列转化为列表数据
original_data = df[loc].tolist()
# 市与区之间以-分割
current_data = []
for item in original_data:
division = re.sub("-.*", "", item)
current_data.append(division)
# pandas转化
df_clean = pd.DataFrame(current_data, columns=[loc])
return df_clean
def city_analysis(data):
# 统计每个城市数量 取前十
counts = data['工作地点'].value_counts()[:10]
l1 = counts.index.tolist()
l2 = counts.values.tolist()
bar = (
# 初始化
Bar()
# 添加横坐标
.add_xaxis(l1)
# 添加纵坐标
.add_yaxis('数量', l2)
# 将图形反转
.reversal_axis()
# 数值在图形右侧显示 left center right
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(
# 图表标题
title_opts=opts.TitleOpts(title="工作城市分析"),
# y轴标签
yaxis_opts=opts.AxisOpts(name="城市名"),
# x轴标签
xaxis_opts=opts.AxisOpts(name="数量"),
)
)
bar.render('./output/02-工作地点TOP10.html')
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 2.工作地点分析
DATA = city_cleaning(data, "工作地点")
city_analysis(DATA)
由该条形图可以发现,爬虫职位工作地点在北上广深居多,上海和深圳最多。
3.福利词云

import matplotlib.pyplot as plt
from wordcloud import WordCloud
import pandas as pd
def word_cloud(data):
# 删除缺失值
complete_data = data.dropna()
welf_list = complete_data['公司福利'].astype(str).tolist()
text = ' '.join(welf_list)
word_cloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
background_color='#fef8ef',
scale=1.2,
max_font_size=180,
min_font_size=15
).generate(text)
plt.figure(figsize=(10, 10))
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
plt.savefig(r'./output/03-福利词云.png')
plt.show()
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 3.福利词云
word_cloud(data=data)
词频越大,该词在词云中越大。可以得知五险一金与效绩奖金为大多数公司都提供的福利。
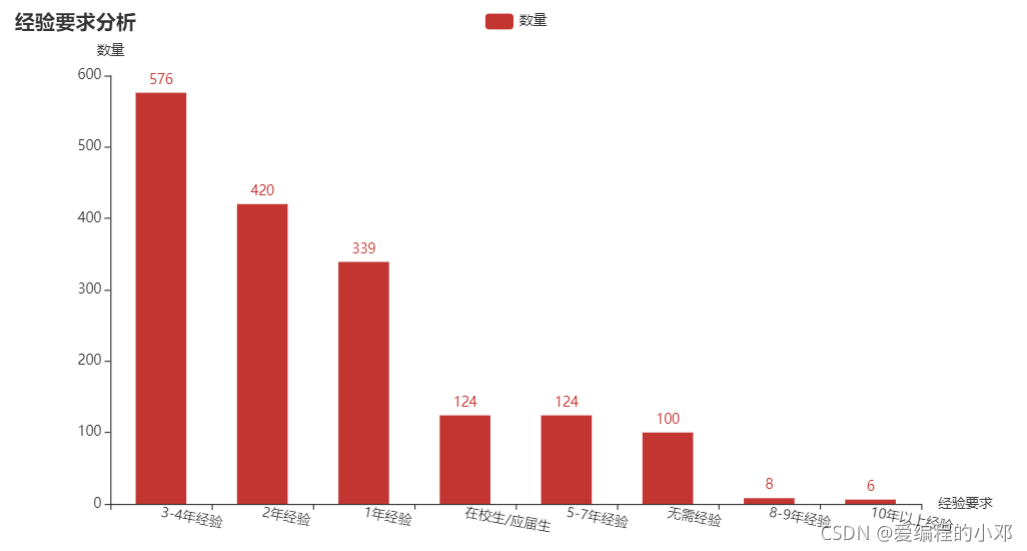
4.经验要求
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
def experience_analysis(data):
# 统计每种经验数量
counts = data['经验要求'].value_counts()
l1 = counts.index.tolist()
l2 = counts.values.tolist()
bar = (
# 初始化
Bar()
# 添加横坐标
.add_xaxis(l1)
# 添加纵坐标
.add_yaxis('数量', l2, category_gap="50%")
# 数值在图形上侧显示 left center right
.set_series_opts(label_opts=opts.LabelOpts(position="top"))
.set_global_opts(
# 旋转x轴坐标 解决标签名字过长的问题
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-10), name="经验要求"),
# 图表标题
title_opts=opts.TitleOpts(title="经验要求分析"),
# y轴标签
yaxis_opts=opts.AxisOpts(name="数量"),
)
)
bar.render('./output/04-经验要求.html')
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 4.经验分析
experience_analysis(data)
由图可以看到,爬虫职业要求1-4年经验居多,但无需经验与应届生也不在少数。
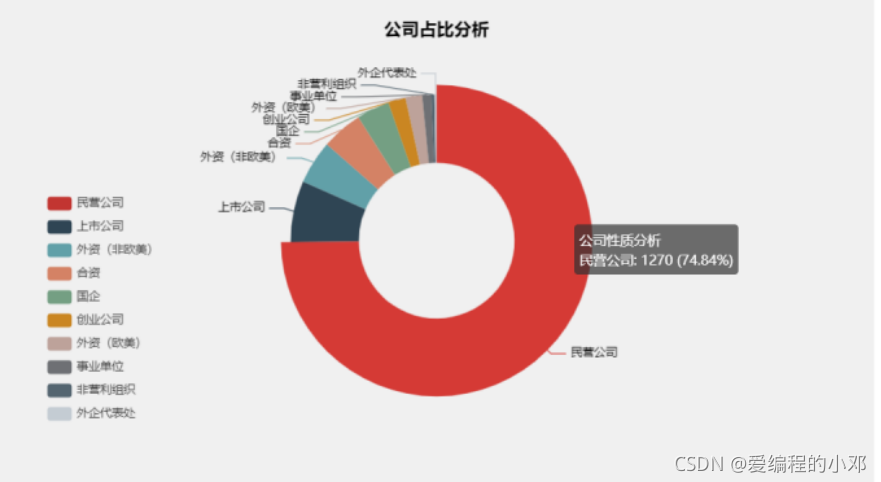
5.公司性质占比圆环图
import pandas as pd
from pyecharts.charts import Pie
from pyecharts import options as opts
def company_analysis(data):
# 统计每种等级的人数
counts = data['公司性质'].value_counts()
# 等级
l1 = counts.index.tolist()
# 其对应人数
l2 = counts.values.tolist()
# 数据格式整理
data_pair = [list(z) for z in zip(l1, l2)]
(
Pie(init_opts=opts.InitOpts(bg_color="rgba(206, 206, 206, 0.3)"))
.add(
series_name="公司性质分析",
data_pair=data_pair,
# 设置为圆环图
radius=[80, 150],
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="公司占比分析",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#000"),
),
legend_opts=opts.LegendOpts(
# 竖向显示
orient="vertical",
# 距离左边5%
pos_left="5%",
# 距离上边40%
pos_top="40%",
),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="#000"),
)
.render(path="./output/05-公司性质占比.html")
)
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 5.公司性质分析
company_analysis(data)
民营公司与上市公司占近80%。
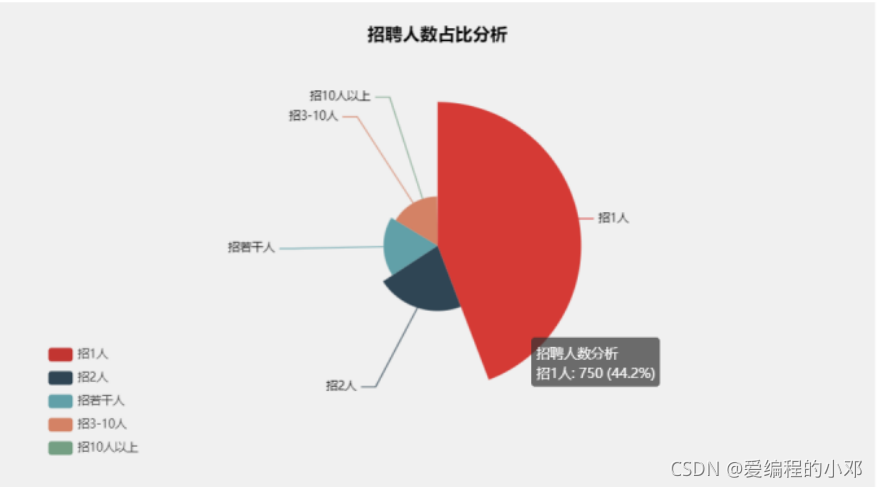
6.招聘人数玫瑰图
import pandas as pd
import re
from pyecharts.charts import Pie
from pyecharts import options as opts
def recruit_cleaning(df, loc):
# 对指定列转化为列表数据
original_data = df[loc].tolist()
current_data = []
for item in original_data:
number = re.findall("招(.*)人", item)[0]
if number == "若干":
current_data.append("招若干人")
else:
number = int(number)
if number >= 3 and number <= 10:
current_data.append("招3-10人")
elif number > 10:
current_data.append("招10人以上")
else:
current_data.append("招{}人".format(number))
# pandas转化
df_clean = pd.DataFrame(current_data, columns=[loc])
return df_clean
def recruit_analysis(data):
# 统计招聘的人数
counts = data['招聘人数'].value_counts()
l1 = counts.index.tolist()
l2 = counts.values.tolist()
# 数据格式整理
data_pair = [list(z) for z in zip(l1, l2)]
(
Pie(init_opts=opts.InitOpts(bg_color="rgba(206, 206, 206, 0.3)"))
.add(
series_name="招聘人数分析",
data_pair=data_pair,
# 设置为玫瑰图
# radius:圆心角展示数据百分比,半径展示数据大小
# area:圆心角相同,半径展示数据大小
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="招聘人数占比分析",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#000"),
),
legend_opts=opts.LegendOpts(
# 竖向显示
orient="vertical",
# 距离左边5%
pos_left="5%",
# 距离上边70%
pos_top="70%",
),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="#000"),
)
.render(path="./output/06-招聘人数占比.html")
)
if __name__ == '__main__':
# 导入数据
data = pd.read_excel('前程无忧网爬虫职位信息.xls')
# 6.招聘分析
df = recruit_cleaning(data, "招聘人数")
recruit_analysis(data=df)
这招聘若干人就很灵性。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 27
27 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)