torch_geometric.data 自建数据集
前言博客大部分都是搬运文档,是文档的翻译版,没什么意思。精细的内容还要结合文档去看。这个只是给你大致概念,不至于看文档看的头昏眼花,不是手把手教。文档:https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html一针见血数据集有两种,一个只存一个图的ImMemory类型,另一个是要存多个图DataSet的,需要
前言
博客大部分都是搬运文档,是文档的翻译版,没什么意思。精细的内容还要结合文档去看。
这个只是给你大致概念,不至于看文档看的头昏眼花,不是手把手教。
文档:
https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html
一针见血
数据集有两种,一个只存一个图的ImMemory类型,另一个是要存多个图DataSet的,需要额外实现len和get函数。
ImMemory要实现的基本上就是官网给的:
import torch
from torch_geometric.data import InMemoryDataset
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data.pt']
def download(self):
# Download to `self.raw_dir`.
def process(self):
# Read data into huge `Data` list.
data_list = [...]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
另一种无非再在继承类那地方改成torch_geometric.data.Dataset,继承这个类就是了,外加重写两个函数
def len(self):
return len(self.processed_file_names)
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
函数名称用途
download写怎么获得raw的dataset,显然我们要自定义数据集,往往是在本地就有的,这个可以直接pass returnraw_file_names这个函数给出多张graph所存的路径,假设有graph a,graph b,那么这里return的就应当是两幅图对应的文件名。processed_paths写处理所有graph过后所存的路径,道理同raw_file_namesprocess处理数据,成规定格式。
规定的什么格式?
from torch_geometric.data import Data这个Data类型,就是你要处理成的格式。
一下内容可以在Data.py里面找到内容,我只是大体提一下。
人家必须要有的属性是:
- y: label就是了,直接给one hot或者给数字类型的都行。
- x: 节点属性
- edge_index: 边关系,可以多种,一种是(id,id)的列表,一种是邻接表。都行。
处理出来以上数据后,可以直接
# contiguous这个是(id,id)这种方式需要加的
graph=Data(x=features,edge_index=network.t().contiguous(),y=labels)
这样一个基本的graph的Data就完成了。
但其实还可以加其他的属性,就直接在他后面加就行:
# 加train_idx
train_idx = torch.tensor([id2inter_id[idx] for idx in herb_with_label_id], dtype=torch.long)
graph=Data(x=features,edge_index=network.t().contiguous(),y=labels)
graph.train_idx = train_idx
实现完自己的数据集运行后会出现什么?
会直接出现这些,processed就是存放运行process函数后的数据,raw是原始数据。
函数的执行
他首先会判断,在参数root路径下存不存在raw和processed两个路径,raw中存不存在raw_paths中给出的raw data,如果没有,他会调用down_load函数给你下载。
想要不进行download,那么要保证raw文件里一定存在你raw path里面返回的文件名。
这里举个例子:
假设我要使用现有的AMiner这个数据集,但是数据是dropbox的,网上不了。我要手动下下来之后使用。
首先我确定这个数据集存在哪里。然后,在这个目录新建dir AMiner,在AMiner下面新建raw和processed,如图:
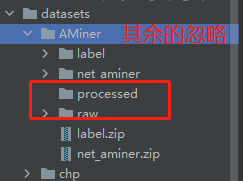
然后进入源码查看所需的raw有什么:
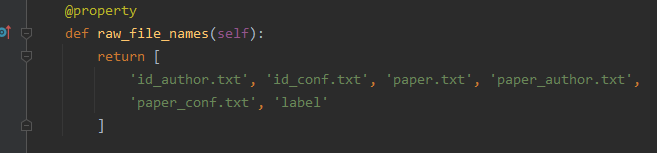
然后通过download函数,找到url,下载(并解压)后,全部放到raw那个目录里面。
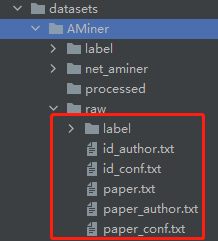
注意:如果没有全部放进去,那么代码会把raw目录整个删除!
接下来的就可以直接使用了,process函数也会把数据存入processed,往后不再赘述。
想要不进行processed直接去加载到内存不进行保存,这个未完待续。
最后再给个我自己用的例子
import torch
import pickle
from torch_geometric.data import InMemoryDataset, Data
class TCMDataSet(InMemoryDataset):
def __init__(self,root,name,feature_size,transform=None,pre_transform=None):
self.feature_size=feature_size
print(f'feature size: {feature_size}')
super(TCMDataSet, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['tcm_dataset.pt',]
@property
def processed_file_names(self):
return ['tcm_dataset.pt',]
def download(self):
pass
def process(self):
# do processing, get x, y, edge_index ready.
graph=Data(x=features,edge_index=network.t().contiguous(),y=labels)
train_idx = torch.tensor([id2inter_id[idx] for idx in herb_with_label_id], dtype=torch.long)
#加入新的属性
graph.train_idx = train_idx
if self.pre_filter is not None:
graph = [data for data in graph if self.pre_filter(data)]
if self.pre_transform is not None:
graph = [self.pre_transform(data) for data in graph]
data, slices = self.collate([graph])
torch.save((data, slices), self.processed_paths[0])

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)