初学者都能学会的Python基础网页抓爬万能代码(仅限无反爬网站)
抓爬教程
·
今天我要和大家分享一个比较基础、简单的抓爬网页文本内容的代码。
实现这个功能非常简单,他主要就是基于一个最最基础的python爬虫包——requests。
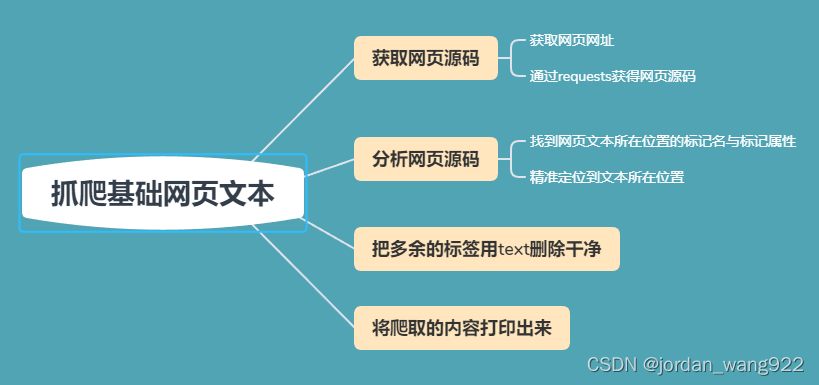
抓爬普通网页我们只需要把它分成几步就可以完成:
首先,抓爬获取源码是首要。我们可以在需要抓爬的网站里敲击F12查看网页源码,如下图:

在这里,我就以刚刚这个网站为例,网址:世界名猫品种大全
抓爬网页源代码如下:
import requests
page=requests.get('http://www.360doc.com/content/19/0113/16/276037_808591294.shtml')
print(page.text)
通过这段代码,我们可以看到网页的全部代码,而我们需要的文本内容也就藏在这些代码之中:

自此,我们思维导图的第一部分就算完成了。
接下来,我们需要读懂这些代码是什么意思。这里我们需要引进一些新的词语:我们在源码中会看到这样的格式<div class="xxx" "猫咪是·······" </div>这样的格式。这里的<div我们把它称之为标记名,class(也可为其他的)=“xxx”我们称之为标记属性。这两点内容也就是我们抓爬定位文本的重要要素。
第二步就是要定位到文本了,通过观察代码我们不难发现,该网站许多文本开头标记都为“p”,而class标记属性为class=similar-text
定位到文本就可以开始我们接下来的代码了:
import requests #导入requests包
from bs4 import BeautifulSoup #导入BS4
req = requests.get(url="http://www.360doc.com/content/19/0113/16/276037_808591294.shtml") #抓爬网站
req.encoding = "utf-8" #解码(如果不进行解码很大概率会出现乱码)
html=req.text #用text将乱码去除
soup = BeautifulSoup(req.text,features="html.parser") #获取内容
x = soup.find_all("p",class_="similar-text") #抓取相关标记的内容
for y in x: #如果想要抓取全部符合属性的文本就需要加入循环
dd = y.text.strip() #text.strip可以将标记删除干净
print(dd) #打印内容通过这个代码就可以抓取文章里面的文本了。
总结一下:抓爬的关键因素在于找标记,找到后通过BS4包来抓取就行了。
如果学会的话就点个赞吧

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)