Python实现基于3σ原则的异常值检测
异常值是指样本中的个别值明显偏离其余的观测值。异常值的存在会对数据分析、建模产生干扰,因此需要对数据集进行异常值检测并进行异常值删除或修正,以便后续更好地进行数据分析和挖掘。对于异常值检测,有描述性统计、3σ原则方法、箱线图、基于聚类的方法等,而3σ原则是最常使用的异常值检测方法之一。在3σ原则下,一般认为数据的取值99.7%的概率集中在(μ-3σ,μ+3σ)区间内(μ为平均值,σ为标准差),超出
异常值是指样本中的个别值明显偏离其余的观测值。异常值的存在会对数据分析、建模产生干扰,因此需要对数据集进行异常值检测并进行异常值删除或修正,以便后续更好地进行数据分析和挖掘。对于异常值检测,有描述性统计、3σ原则方法、箱线图、基于聚类的方法等,而3σ原则是最常使用的异常值检测方法之一。在3σ原则下,一般认为数据的取值99.7%的概率集中在(μ-3σ,μ+3σ)区间内(μ为平均值,σ为标准差),超出这个范围的可能性仅占0.3%,属于极个别的小概率事件,因此将超出(μ-3σ,μ+3σ)范围的值认为是异常值。3σ原则要求数据服从正态或近似正态分布,且样本数据大于10。若数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。现利用Python实现基于3σ原则的异常值检测,并对从网络上查询的中国1952年-2018年中国GDP(亿元)、GDP指数((上年=100)) 人均GDP(元)、GDP增长率(%)、第二产业增加值(亿元) 、第三产业增加值(亿元)等24个指标数据进行异常值检测。
#基于3sigma的异常值检测
#-*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #导入绘图库
##3sigma原则
def threesigma(data,n):
'''
data:表示时间序列,包括时间和数值两列;
n:表示几倍的标准差
'''
data_x = data.ix[:,0].tolist() ##获取时间序列的时间
#print (data_x)
#print ("**********",j)
mintime=data_x[0] ##获取时间序列的起始年份
maxtime=data_x[-1] ##获取时间序列的结束年份
data_y = data.ix[:,1].tolist() ##获取时间序列数值
ymean = np.mean(data_y) ##求时间序列平均值
ystd = np.std(data_y) ##求时间序列标准差
down = ymean - n * ystd ##计算下界
up = ymean + n * ystd ##计算上界
outlier = [] #将异常值保存
outlier_x = []
for i in range(0, len(data_y)):
if (data_y[i] < down)|(data_y[i] > up):
outlier.append(data_y[i])
outlier_x.append(data_x[i])
else:
continue
return mintime,maxtime,outlier,outlier_x
#设置列表,用于记录结果
indicator=[] ##指标
flag=[] ##是否为异常值
outlier_data=[] ##异常值
outlier_time=[] ##出现异常值的对应时间
max_time=[] ##时间序列的开始时间
min_time=[] ##时间序列的结束时间
time_flag=[] ##异常值是否为起始时间
#读取数据
data = pd.read_csv( 'data.csv', index_col = False,encoding='gb18030') #读取数据
#print(data.head())
col_name=data.columns.tolist()
#print (data.columns.tolist())
#设置参数
n = 3 # n*sigma
print ("******************:n=",n)
##依次检测每一个指标
for j in col_name[1:]:
indicator.append(j)
temp_data=data.ix[:,['时间',j]]
#print ("删除空值前",len(temp_data))
temp_data=temp_data.dropna() #删除空值
#print("删除空值后",len(temp_data))
temp_data=temp_data.sort_values(by = ['时间'],axis = 0,ascending = True) #按时间排序
#print (temp_data)
mintime,maxtime,outlier,outlier_x=threesigma(temp_data,n) #调用3sigma函数
min_time.append(mintime) ##获取时间序列的起始年份
max_time.append(maxtime) ##获取时间序列的结束年份
outlier_data.append(outlier)
outlier_time.append(outlier_x)
if (maxtime in outlier_x) or (mintime in outlier_x):
time_flag.append('异常值为起始端')
#print (time_flag)
else:
time_flag.append("")
if len(outlier)>0:
flag.append('异常')
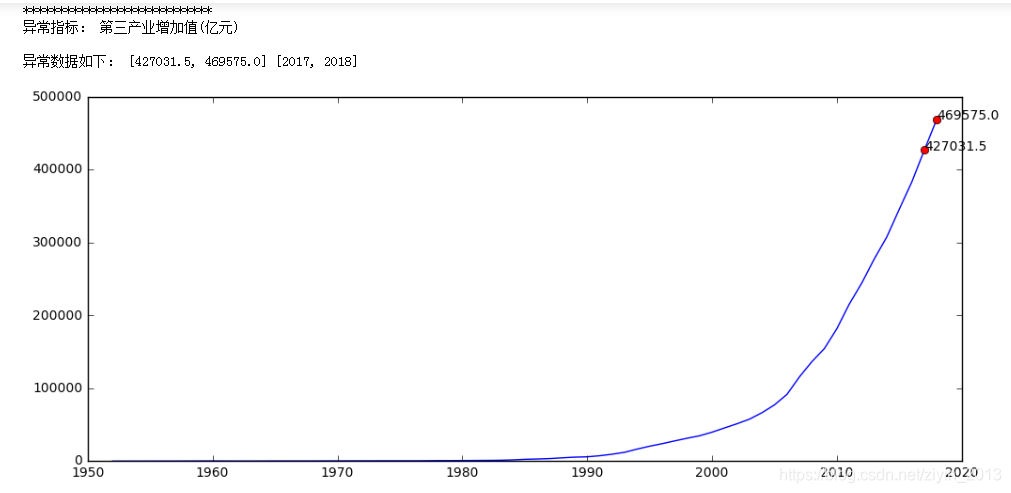
print("***************************")
print ("异常指标:",j)
print('\n异常数据如下:',outlier,outlier_x)
##画出存在异常值的时间序列的折线图,异常值处特殊标注
plt.figure(figsize=(12,5))
plt.plot(temp_data.ix[:,0], temp_data.ix[:,1])
plt.plot(outlier_x, outlier, 'ro')
for j in range(len(outlier)):
plt.annotate(outlier[j], xy=(outlier_x[j], outlier[j]), xytext=(outlier_x[j],outlier[j]))
plt.show()
else:
flag.append('正常')
result=pd.DataFrame()
result['指标']=indicator
result['开始时间']=min_time
result['结束时间']=max_time
result['是否异常']=flag
result['异常数值']=outlier_data
result['异常时间']=outlier_time
result['异常值所处时间标识']=time_flag
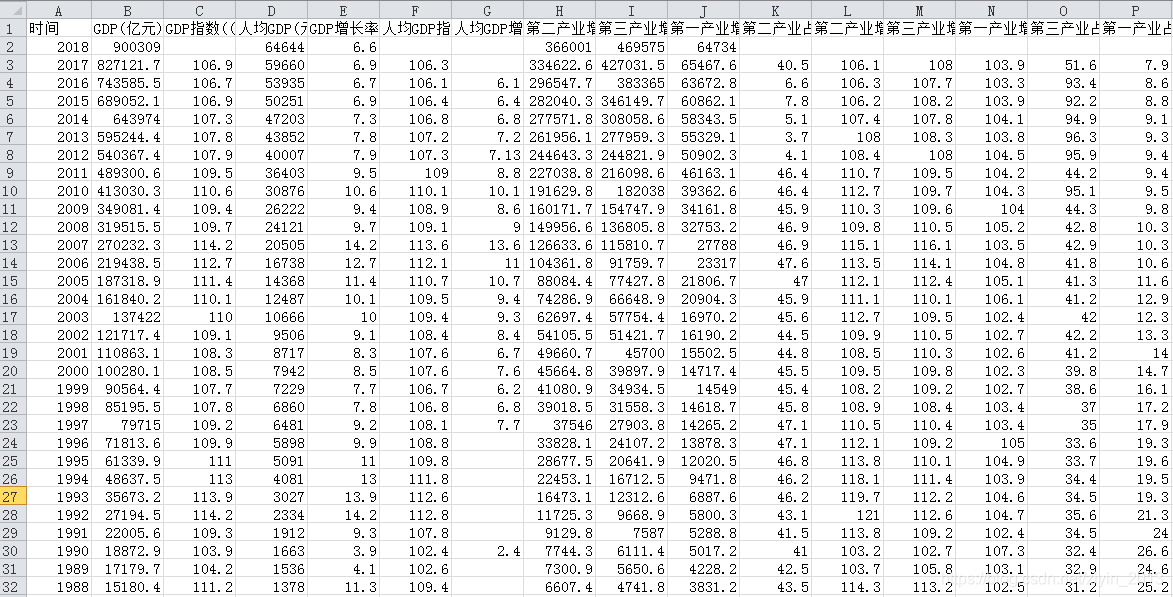
result
对于抛出来的异常值要重点关注,并且结合实际的业务情况来判断数据是否真的存在异常,以及何种原因导致的异常,进而确定异常值的处理方式。
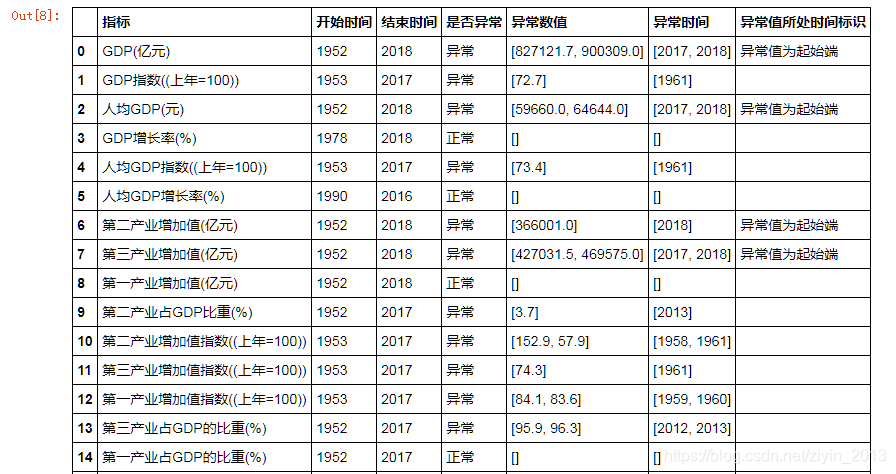
- GDP指数(上年=100):1961年我国刚刚经过三年自然灾害,查询多方面资料证实数据没有问题,不作处理。
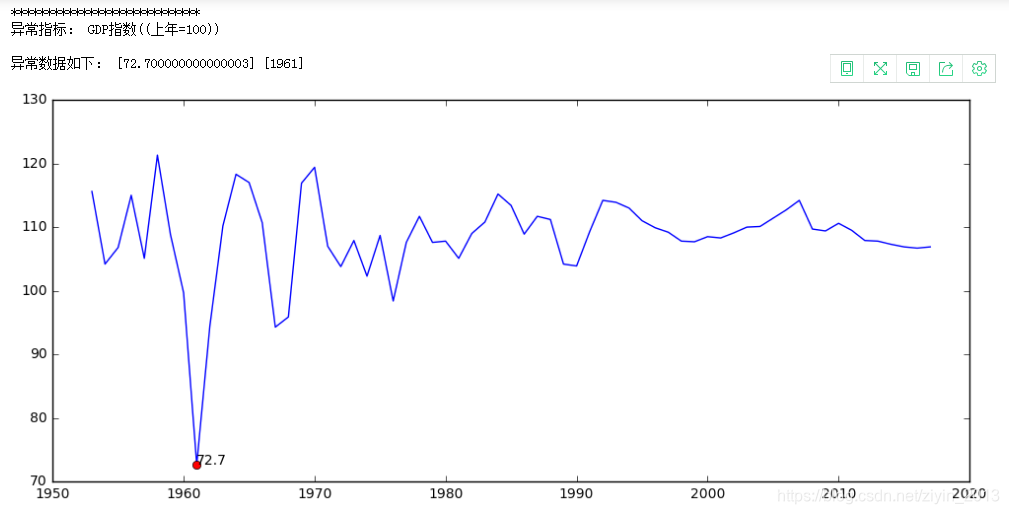
- 第三产业占GDP比重(%):查询多方面资料证实数据确实存在问题,进行修正。
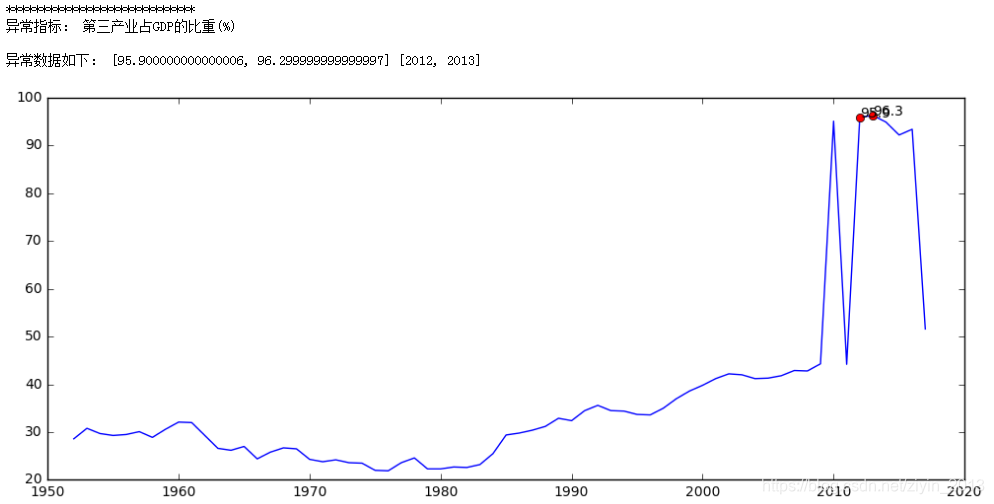
- 第三产业增加值(亿元):异常值出现在时间序列的起始端,通过折线图和多方面资料证实数据没有问题,不作处理。
附数据和源程序。链接:https://pan.baidu.com/s/1RLC6769nJLKUG3woWsv17w 提取码:rmjc
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容
 免费领云主机
免费领云主机


 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)