2021 年“泰迪杯”数据分析技能赛B题:python实现肥料登记数据分析(含原始数据)
这周复习了python数据处理的实战,把之前竞赛的题目重新做了一遍。这里侧重数据分析与数据处理的部分。文末含原始题目与数据,需要的小伙伴自取~
这周复习了python数据处理的实战,把之前竞赛的题目重新做了一遍。这里侧重数据分析与数据处理的部分。文末含原始题目与数据,需要的小伙伴自取~
【事先说明】:本文只是在技术维度上进行分析及展示,在业务维度上没有做过多分析。事实上在竞赛或工作中,数据分析都是离不开业务的,不过现在就先练练技术啦~
肥料登记数据分析
一、背景
肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管 理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府 农业行政主管部门主要负责本行政区域内销售的肥料登记工作,相关数据可从政 府网站上自由下载。
二、目标
1.对肥料登记数据进行预处理。 2. 根据养分的百分比对肥料产品进行细分。 3. 从省份、日期、生产商、肥料构成等维度对肥料登记数据进行对比分析。 4. 对非结构化数据进行结构化处理。
三、任务
请根据附件 1~附件 4 中提供的数据,自行选择分析工具完成以下任务,并 撰写报告。
任务 1 数据的预处理
任务 1.1
附件 1 的产品通用名称存在不规范的情况。请按照复混肥料(掺混肥料归入这一类)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 种类别对附件 1 进行规范化处理。请在报告中给出处理思路、过程及必要的结果,同时 将完整的结果保存到件“result1_1.xlsx”中。
处理思路:
- 利用value_counts()查看类别数据Series的类别分布
- 利用str.replace()\str.strip()这种 字符串向量化的方式对字符串Series数据处理
- 利用map()实现数据转换
导入数据
import pandas as pd
import numpy as np
data1=pd.read_excel('附件1.xlsx')
data1.head()
查看数据前五行
data1['产品通用名称'].value_counts() #查看【产品通用名称】类型
'''
复混肥料 1647
掺混肥料 941
有机肥料 180
有机-无机复混肥料 124
有机-无机 复混肥料 9
床土调酸剂 7
有机无机 复混肥料 5
\n有机肥料\n 3
稻苗床土调酸剂 3
有机-无机复混肥料 2
有机无机 复混肥料 1
掺混肥料 1
有机肥料 1
有机肥料\n 1
Name: 产品通用名称, dtype: int64'''
#先进行简单的处理:去掉空格,简化后续处理
data1['产品通用名称']=data1['产品通用名称'].str.replace(" ","").str.strip()
data1['产品通用名称'].value_counts()#查看处理候的类型
'''
复混肥料 1647
掺混肥料 942
有机肥料 185
有机-无机复混肥料 133
床土调酸剂 7
有机无机复混肥料 6
稻苗床土调酸剂 3
有机-无机复混肥料 2
Name: 产品通用名称, dtype: int64'''
#正式处理
dic={'复混肥料':'复混肥料', '掺混肥料':'复混肥料', '有机肥料':'有机肥料', '有机-无机复混肥料':'有机-无机复混肥料', '床土调酸剂':'床土调酸剂', '有机无机复混肥料':'有机-无机复混肥料', '稻苗床土调酸剂':'床土调酸剂',
'有机-无机复混肥料':'有机-无机复混肥料'}
data1['产品通用名称']=data1['产品通用名称'].map(dic)
print(data1['产品通用名称'].value_counts())#处理后
'''
复混肥料 2589
有机肥料 185
有机-无机复混肥料 141
床土调酸剂 10
Name: 产品通用名称, dtype: int64'''
任务 1.2
计算附件 1 中各肥料产品的氮、磷、钾养分百分比之和,称为总无机养分百分比。请在报告中给出处理思路、过程及必要的结果,同时将完整的 结果保存到文件“result1_2.xlsx”中,结果保留 3 位小数(例如 1.0%,即 0.010)。
data1['总无机养分百分比']=round(data1['总氮百分比']+data1['P2O5百分比']+data1['K2O百分比'],3)

任务 2 肥料产品的数据分析
任务 2.1
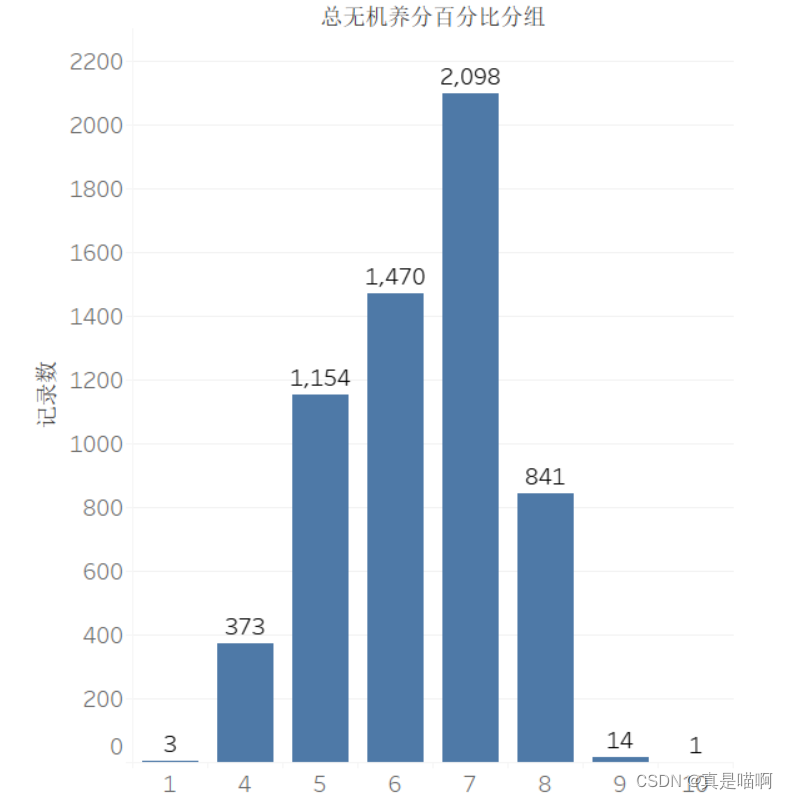
从附件 2 中筛选出复混肥料的产品,将所有复混肥料按照总无机 养分百分比的取值等距分为 10 组。根据每个产品所在的分组,为其打上分组标 签(标签用 1~10 表示),将完整的结果保存到文件“result2_1.xlsx”中。
分析复混肥料产品的分布特点,在报告中绘制产品登记数量的直方图,给出处理思路及 过程,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记 数量。
data2=pd.read_excel('附件2.xlsx')
data2_fh=data2[data2['产品通用名称']=='复混肥料']# 筛选出复混肥料
data2_fh['总无机养分百分比分组']=pd.cut(data2_fh['总无机养分百分比'],10,labels=range(1,11))#对数据分箱
print(data2_fh['总无机养分百分比分组'].value_counts())
'''
7 2098
6 1470
5 1154
8 841
4 373
9 14
1 3
10 1
3 0
2 0
Name: 总无机养分百分比分组, dtype: int64'''
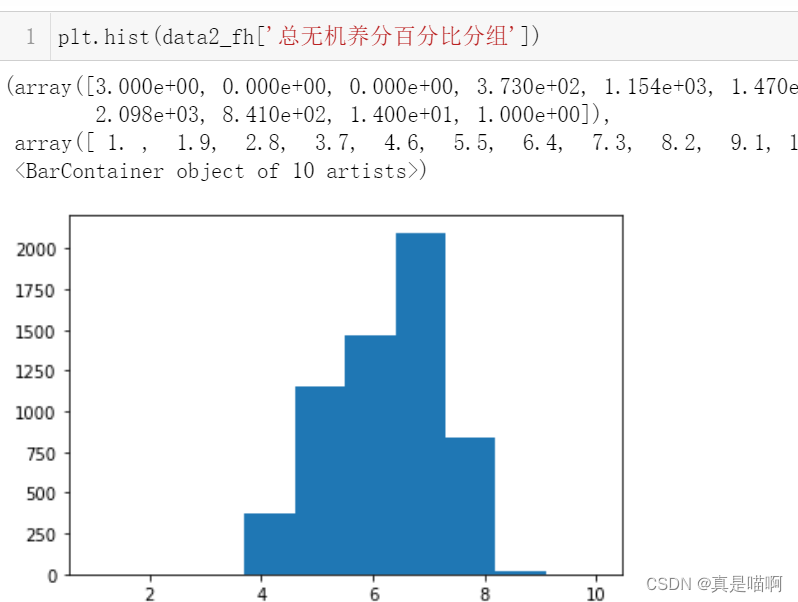
以下是tableau实现的,好看些
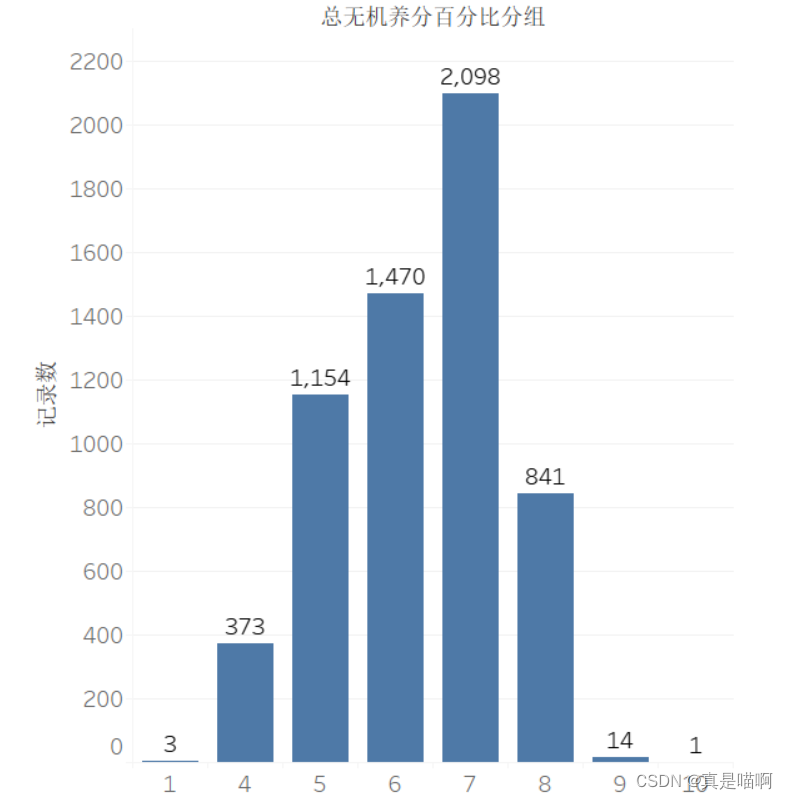
任务 2.2
从附件 2中筛选出有机肥料的产品,将产品按照总无机养分百分 比和有机质百分比分别等距分为 10 组,并为每个产品打上分组标签 (1,1), (1,2), ⋯, (10,10),将完整的结果保存到文件“result2_2.xlsx”中。请在报告中给出处理 思路及过程,并根据分组情况绘制有机肥料产品的分布热力图,其中横轴代表总 无机养分分组,纵轴代表有机质分组。在此基础上,分析有机肥料产品的分布特 点,并按登记数量从大到小列出登记数量最大的前 3 个分组及相应的产品登记数 量。
data2_yj=data2[data2['产品通用名称']=='有机肥料']
data2_yj['总无机养分百分比分组']=pd.cut(data2_yj['总无机养分百分比'],10,labels=range(1,11))
data2_yj['有机质百分比分组']=pd.cut(data2_yj['有机质百分比'],10,labels=range(1,11))
data2_yj['分组']=0
for i in range(len(data2_yj)):
data2_yj.iloc[i,17]='('+str(data2_yj.iloc[i,15])+','+str(data2_yj.iloc[i,16])+')'
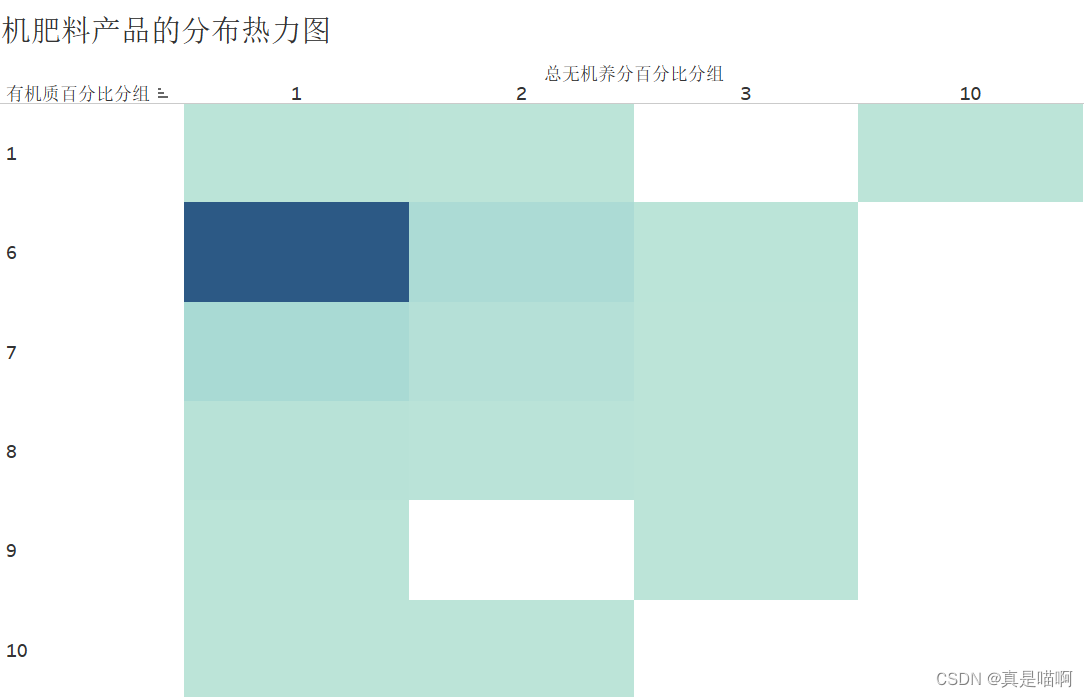
任务 3 肥料产品的多维度对比分析
任务 3.1
从文件**“result2_1.xlsx”**中提取发证日期中的年份,分析比较复混 肥料中各组别不同年份产品登记数量的变化趋势。请在报告中给出处理思路及分 析过程,使用合适的图表对结果进行可视化。
import datetime as dt
data2_fh['发证日期']=pd.to_datetime(data2_fh['发证日期'])
data2_fh['year']=data2_fh['发证日期'].dt.year
fz=pd.crosstab(data2_fh['year'],data2_fh['总无机养分百分比分组'])
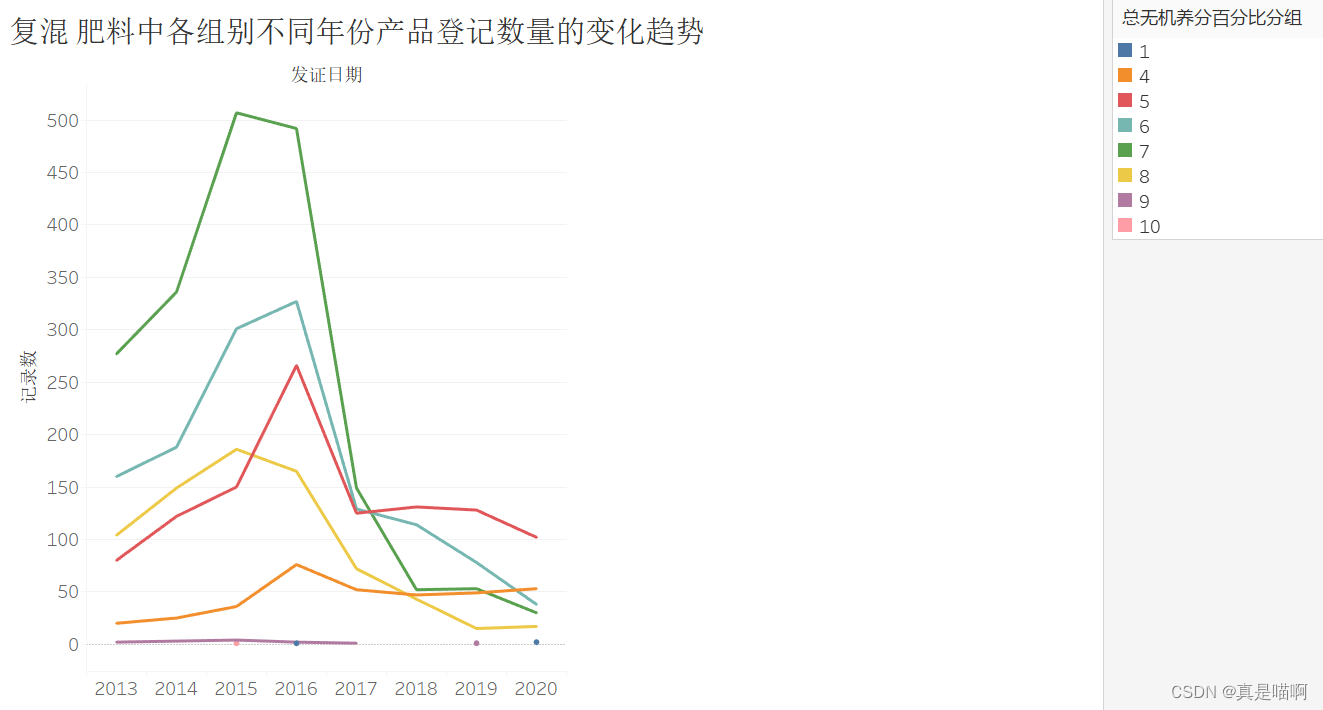
任务 3.2
从文件“result2_2.xlsx”中提取 2021 年 9 月 30 日仍有效的有机 肥料产品,将完整的结果保存到文件“result3_2.xlsx”中。从有效产品中分别筛选出广西和湖北(根据正式登记证号区分)产品登记数量在前 5 的组别,分析两 个省份上述组别的分布差异。请在报告中给出处理过程及分析结果。
#筛选有效期
from datetime import datetime
data2_yj['有效期']=pd.to_datetime(data2_yj['有效期'])
result3_2=data2_yj[data2_yj['有效期']>=datetime(2021,9,30)]
result3_2.to_excel('result3_2.xlsx')
#分组
e=result3_2[result3_2['正式登记证号'].str.startswith('鄂')]
print(e['序号'].groupby(e['分组']).count().sort_values(ascending=False))
g=result3_2[result3_2['正式登记证号'].str.startswith('桂')]
print(g['序号'].groupby(g['分组']).count().sort_values(ascending=False))
'''
分组
(1,6) 385
(1,7) 11
(1,8) 5
(2,6) 3
(2,7) 2
(2,8) 1
(2,10) 1
(1,9) 1
Name: 序号, dtype: int64
分组
(1,6) 346
(1,7) 55
(2,6) 48
(2,7) 23
(1,8) 9
(2,8) 8
(3,6) 6
(1,9) 4
(3,9) 2
(3,8) 2
(3,7) 1
(2,10) 1
(1,10) 1
Name: 序号, dtype: int64'''
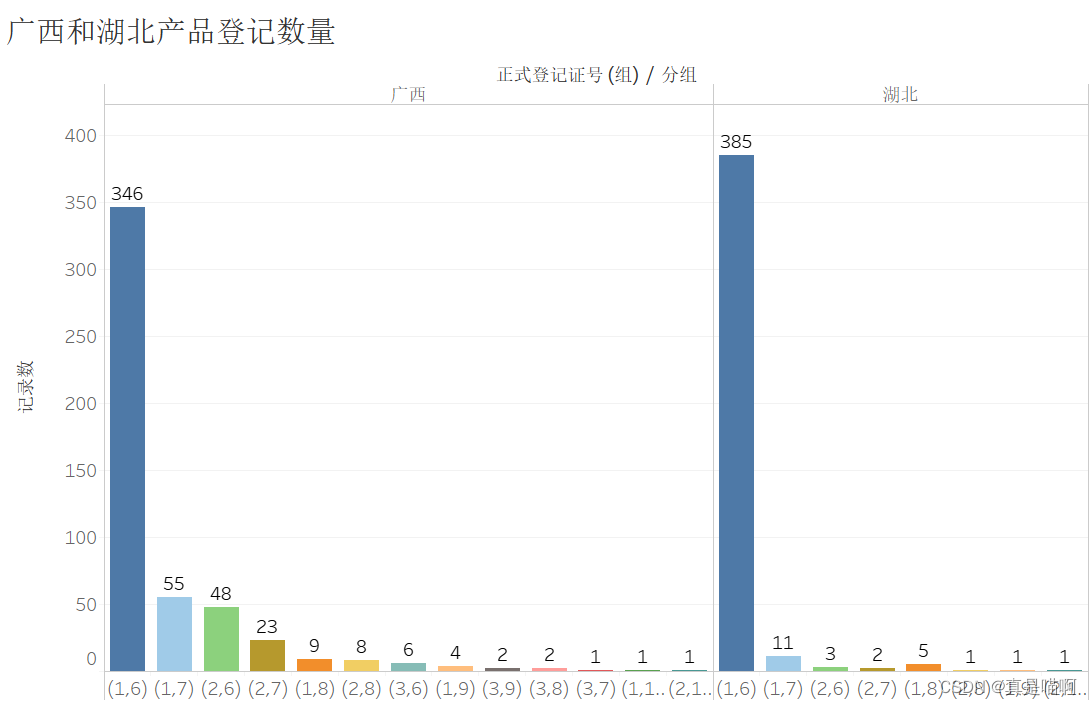
任务 3.3
从附件 3 中提取产品登记数量大于 10 的肥料企业,给出这些企业 所用到的原料集合(发酵菌剂除外)。以各企业用到的原料作为特征,计算企业 之间的杰卡德相似系数矩阵,并将结果(保留4位小数)保存到文件“result3_3.xlsx” 中(不提供模板文件,格式见表 1)。请在报告中给出处理思路、过程及相似系 数矩阵。 注 集合 𝐴 与 𝐵 的杰卡德相似系数定义为 𝐽(𝐴, 𝐵) = |𝐴∩𝐵|/ |𝐴∪𝐵| ,其中 |S| 表示 集合 𝑆 中元素的个数。 表 1 结果文件 result3_3.xlsx 的格式 企业名称 1 企业名称 2 ⋯ 企业名称 n 企业名称 1 企业名称 2 ⋯ 企业名称 n
data3=pd.read_excel('附件3.xlsx')
#筛选登记数量>10的
t=data3['序号'].groupby(data3['企业名称']).count()
print(t[t>10])
names=t[t>10].index
#得到企业原料集合
dic={}
for i in names:
temp=data3[data3['企业名称']==i]
temp=temp.drop(['序号','企业名称','发酵菌剂'],axis=1)
l=temp.dropna(axis=1,how='all').columns
dic[i]=list(l)
#计算杰卡德相似系数
def j(l1,l2):
u=set(l1).union(set(l2))
n=set(l1).intersection(set(l2))
return round(len(n)/len(u),4)
#得到矩阵
l=[]
for i in dic.keys():
k=[]
for p in dic.keys():
k.append(j(dic[i],dic[p]))
l.append(k)
data3_3=pd.DataFrame(l,index=names,columns=names)
data3_3.to_excel('result3_3.xlsx')
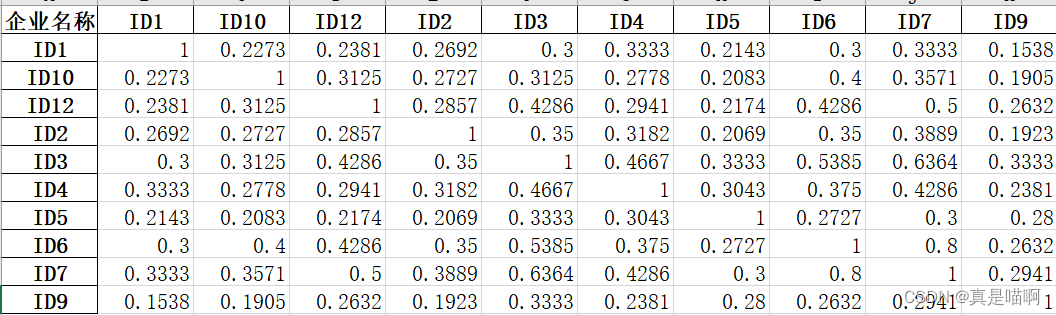
任务 4 肥料产品的多维度对比分析
任务 4.1
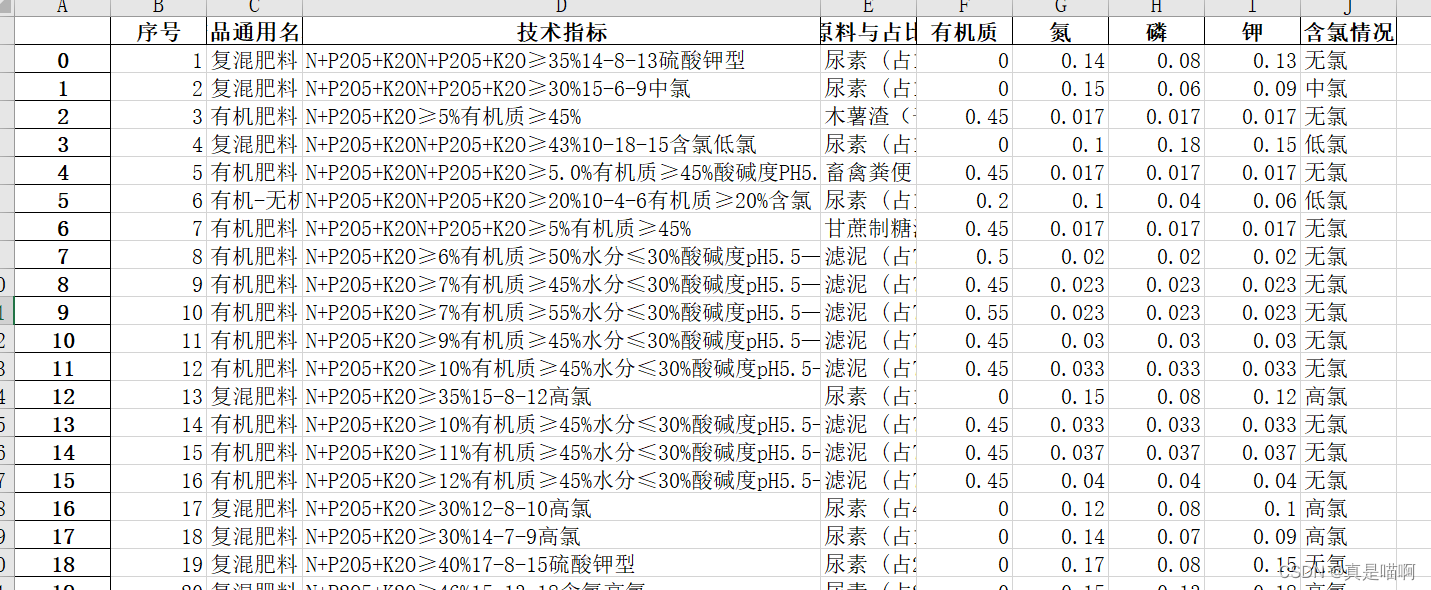
设计算法或处理流程,从附件 4 技术指标中提取出氮、磷、钾养 分和有机质的百分比,以及肥料含氯的程度。请在报告中给出处理思路及过程, 并将结果保存到文件“result4_1.xlsx”中。 注 如果技术指标中只给出总养分百分比(“≥”按照“=”处理)而无明细数据,则氮、磷、钾养分的百分比按照总百分比的 1/3 来计算,结果保留 3 位 小数(例如 1.0%,即 0.010)。复混肥料属于无机肥料,它的有机质百分比设定 为 0。含氯情况分为“无氯”、“低氯”、“中氯”和“高氯”4 种。如果肥料 产品的技术指标中没有给出含氯情况,则视为“无氯”;如果注明“含氯”,则 视为“低氯”。
参考数据说明:
字段技术指标以字符串的形式给出了肥料的营养成分的百分比。例如某复混肥料的技术 指标字段取值为“N+P2O5+K2O≥20%(7-10-3) 有机质≥20% 含氯”,表示肥 料中氮磷钾三大元素的总养分含量不小于 20%;“(7-10-3)”指的是氮磷钾的 配比,氮含量为 7%,磷肥成分(折算为 P2O5)含量为 10%,钾肥成分(折算为 K2O)含量为 3%;“有机质≥20%”表示肥料中有机质的含量不小于 20%;“含 氯”表示肥料中含有氯元素。有机肥料由于不含无机养分或含量较少,有些产品只在技术指标中标明“总养分≥…%”,没有给出氮、磷、钾 3 大元素的具体含 量。
我的整体思路:
1.针对’技术指标‘列的数据做初步清洗
2.用能够满足大部分数据的正则表达式找到题目中要求的数据
3.看哪些数据没有通过正则表达式得到。根据它们对正则表达式进行优化或直接对修改数据的格式
整个过程的,不断修改,得到最终的答案
data4=pd.read_excel('附件4.xlsx')
#清洗数据,可以不断迭代修改的
def rp(s):
for i in r' ()()::,,':
s=str(s)
s=s.replace(i,'')
#对无机总养分的表达进行规范
list1=['总氧份','总养分','总养份','N+P₂O5+K20','N-P-K','总含量','N+P2O5+K2O的质量分数','N+P₂O5+K₂O','NPK','N+P2O5+K2O含量','氮+五氧化二磷+氧化钾','N+P2O5+K2O%']
for i in list1:
s=s.replace(i,'N+P2O5+K2O')
s=s.replace('%','%')
s=s.replace('―','-')
s=s.replace('o','O')
s=s.replace('≧','≥')
#对有机质的表达进行规范
list2=['有机质含量','有%机质','有机质的质量分数以烘干基计','有机质以干基计','有机质的质量分数','有机质%','有机质以烘干基']
for i in list2:
s=s.replace(i,'有机质')
return s
#获取我们想要的字符串
regex_npk=re.compile('\d+-\d+-\d+')#氮磷钾的比例
regex1=re.compile(r'(?<=K2O≥)\d+')#无机盐比例
regex2=re.compile(r'(?<=有机质≥)\d+')#有机质比例
data4['技术指标']=data4['技术指标'].apply(rp)#对技术指标列进行清洗
data4['npk']=data4['技术指标'].str.findall(regex_npk)#先准备一列,记录氮磷钾比例
data4['无机盐']=data4['技术指标'].str.findall(regex1)#获取匹配后的结果
data4['有机质']=data4['技术指标'].str.findall(regex2)
#注意,利用series.str.findall得到的是list
data4['氮']=0
data4['磷']=0
data4['钾']=0
for i in range(len(data4)):
if i!=173:#173是空值
if((len(data4['npk'][i])>0) & (len(data4['无机盐'][i])>0)):
#给了氮磷钾比例的
npk=str(data4['npk'][i][0])
l=re.findall('\d+',npk)
l=[int(x) for x in l]
al=str(data4['无机盐'][i][0])
data4.iloc[i,7]=l[0]/sum(l)*int(al)*0.01
data4.iloc[i,8]=l[1]/sum(l)*int(al)*0.01
data4.iloc[i,9]=l[2]/sum(l)*int(al)*0.01
#没给氮磷钾比例的
if (len(data4['npk'][i])==0)& (len(data4['无机盐'][i])>0):
al=str(data4['无机盐'][i][0])
data4.iloc[i,7]=round(1/3*int(al)*0.01,3)
data4.iloc[i,8]=round(1/3*int(al)*0.01,3)
data4.iloc[i,9]=round(1/3*int(al)*0.01,3)
#有机质的
if (len(data4['有机质'][i])>0):
data4.iloc[i,6]=round(float(data4.iloc[i,6][0])*0.01,3)
else:
data4.iloc[i,6]=0
#对含氯情况的处理
data4['含氯情况']=0#默认0,方面后续检查未处理数据
#注意顺序之间逻辑
data4.iloc[data4[data4['技术指标'].str.contains('含氯')].index,10]='低氯'
data4.iloc[data4[data4['技术指标'].str.contains('不含氯')].index,10]='无氯'
index=data4[data4['技术指标'].str.contains('高氯')].index
data4.iloc[index,10]='高氯'
index=data4[data4['技术指标'].str.contains('中氯')].index
data4.iloc[index,10]='中氯'
index=data4[data4['技术指标'].str.contains('低氯')].index
data4.iloc[index,10]='低氯'
index=data4[data4['技术指标'].str.contains('氯')==False].index
data4.iloc[index,10]='无氯'
result4_1=data4.drop(['npk','无机盐'],axis=1)
result4_1.to_excel('result4_1.xlsx')
结果:
任务 4.2
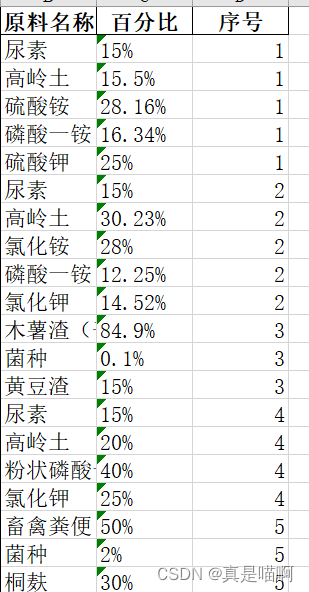
设计算法或处理流程,从附件 4 原料与百分比中提取各种原料的 名称及其百分比。请在报告中给出处理思路及过程,并将结果保存到文件 “result4_2.xlsx”中(参见表 2)。 表 2 结果文件 result4_2.xlsx 的示例 序号 原料名称 百分比 001 酒精废液 45% 001 蔗渣 3.52% ⋯ ⋯ ⋯ 002 滤泥 0.153%
这里的思路与同上
data4_2=pd.read_excel('附件4.xlsx')
#第122条特殊处理
data4_2.iloc[122,3]='尿素 (占10%),硫酸锌 (占1%),氯化铵 (占15%),氯化钾 (占20.2%),硫酸铵 (占24.8%),磷酸一铵 (占25%),过磷酸钙 (占4%)'
#数据清洗
data4_2['原料与占比']=data4_2['原料与占比'].str.replace(' ','')
data4_2['原料与占比']=data4_2['原料与占比'].str.replace('(','(')
#转成中文的括号方面正则化匹配
data4_2['原料与占比']=data4_2['原料与占比'].str.replace(')',')')
data4_2['原料与占比']=data4_2['原料与占比'].str.replace(',',',')
data4_2['原料与占比']=data4_2['原料与占比'].str.replace('(占0%),','')
#进行初步的提取
def tiqu(data4_2,i):
dic={}
l1=data4_2['原料与占比'][i].split(',')
l2=re.findall('(占\d+%)|(占\d+.\d+%)',data4_2['原料与占比'][i])
dic['原料名称']=l1
dic['百分比']=l2
d=pd.DataFrame(dic)
d['序号']=data4_2['序号'][i]
return d
d1=tiqu(data4_2,0)
for i in range(1,len(data4_2)):
##第22条是缺失值
if i not in[22]:
d1=pd.concat([d1,tiqu(data4_2,i)])
d1['原料名称']=d1['原料名称'].str.replace('(占\d+%)|(占\d+.\d+%)','')
d1['百分比']=d1['百分比'].str.replace('(占|)','')
d1.to_excel('result4_2.xlsx')
结果展示:
四、数据说明
附件 1~附件 4 的数据收集自农业部门官方网站,部分数据细节与实际有差 别,仅供比赛使用。
附件 1 为安徽肥料登记数据,
附件 2 为广西、湖北肥料登记数据。
这两个附 件中表的主要字段有企业名称、产品通用名称、正式登记证编号、发证日期、有 效时间、产品形态、营养成分百分比、含氯情况等。其中产品通用名称实际上是 肥料产品的类型,需要在省级农业行政主管部门登记的肥料有复混肥料(包括掺 混肥料)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 类。肥料的营养成 分百分比指标,通常标记出属于无机成分的氮、磷、钾的含量,以及有机质的含 量。我国规定,氮肥成分以总氮的质量来计算含量,磷肥成分按磷元素的量折算 成五氧化二磷(P2O5)的质量来计算含量,钾肥成分按钾元素的量折算成氧化钾 (K2O)的质量来计算含量。注意,肥料正式登记证有效期为 5 年,可以续期, 会出现有效期距发证日期大于 5 年的情况。
附件 3
给出了某省登记肥料的产品配方,相比附件 1 和附件 2 增加了关于肥 料原料的信息。
2 为广西、湖北肥料登记数据。
这两个附 件中表的主要字段有企业名称、产品通用名称、正式登记证编号、发证日期、有 效时间、产品形态、营养成分百分比、含氯情况等。其中产品通用名称实际上是 肥料产品的类型,需要在省级农业行政主管部门登记的肥料有复混肥料(包括掺 混肥料)、有机-无机复混肥料、有机肥料和床土调酸剂这 4 类。肥料的营养成 分百分比指标,通常标记出属于无机成分的氮、磷、钾的含量,以及有机质的含 量。我国规定,氮肥成分以总氮的质量来计算含量,磷肥成分按磷元素的量折算 成五氧化二磷(P2O5)的质量来计算含量,钾肥成分按钾元素的量折算成氧化钾 (K2O)的质量来计算含量。注意,肥料正式登记证有效期为 5 年,可以续期, 会出现有效期距发证日期大于 5 年的情况。
附件 3
给出了某省登记肥料的产品配方,相比附件 1 和附件 2 增加了关于肥 料原料的信息。
附件 4 给出了某省肥料登记数据中营养成分及原料构成的原始数据。字段技 术指标以字符串的形式给出了肥料的营养成分的百分比。例如某复混肥料的技术 指标字段取值为“N+P2O5+K2O≥20%(7-10-3) 有机质≥20% 含氯”,表示肥 料中氮磷钾三大元素的总养分含量不小于 20%;“(7-10-3)”指的是氮磷钾的 配比,氮含量为 7%,磷肥成分(折算为 P2O5)含量为 10%,钾肥成分(折算为 K2O)含量为 3%;“有机质≥20%”表示肥料中有机质的含量不小于 20%;“含 氯”表示肥料中含有氯元素。有机肥料由于不含无机养分或含量较少,有些产品 只在技术指标中标明“总养分≥…%”,没有给出氮、磷、钾 3 大元素的具体含 量。字段原料与百分比以字符串的形式给出了肥料的原料构成及质量百分比,例 如某有机肥料的原料与百分比字段取值为“糖蜜酒精废液 (占 25%),发酵菌种 (占 1%),木糠 (占 25%),滤泥 (占 49%)”,表明了该有机肥料由蜜糖酒精废液、 发酵菌种、木糠和滤泥四种原料构成,质量百分比分别是 25%、1%、25%及 49%。 注 本赛题中,不同的正式登记证号代表不同的产品。
数据
百度网盘:
链接:https://pan.baidu.com/s/1Zs24s1UMXJcnZ-ooq38pQA
提取码:56qa
ps:第一次练任务四正则表达式这种题型,个人感觉处理得还不够简便,若有好的建议,欢迎提出。
- 考察点:字符串向量的处理、函数应用、正则表达式、时间序列
- 难易程度:中

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 27
27 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)