文本聚类!
目录第10章 文本聚类10.1 概述10.2 文档的特征提取10.3 k均值算法10.4 重复二分聚类算法10.5 标准化评测10.6 总结第10章 文本聚类上一章我们在字符、词语和句子的层级上应用了一些无监督学习方法。这些方法可以自动发现字符与字符、词语与词语、乃至句子与句子之间的联系,而不需要标注语料。同样,在文档层级上,无监督方法也可以在缺乏标注数据的条件下自动找出文档与文档之间的关联。正所
目录
第10章 文本聚类
10.1 概述
10.2 文档的特征提取
10.3 k均值算法
10.4 重复二分聚类算法
10.5 标准化评测
10.6 总结
第10章 文本聚类
上一章我们在字符、词语和句子的层级上应用了一些无监督学习方法。这些方法可以自动发现字符与字符、词语与词语、乃至句子与句子之间的联系,而不需要标注语料。同样,在文档层级上,无监督方法也可以在缺乏标注数据的条件下自动找出文档与文档之间的关联。
正所谓物以类聚,人以群分。人类获取并积累信息时常常需要整理数据,将相似的数据归档到一起。许多数据分析需求都归结为自动发现大量样本之间的相似性,并将其划分为不同的小组。这种根据相似性归档的任务称为聚类,本章介绍一种文挡层级上的聚类任务,即文本聚类。
10.1 概述
文本聚类是聚类在文本上的应用,下面先介绍聚类的概念。
10.1.1 聚类
聚类(cluster analysis)指的是将给定对象的集合划分为不同子集的过程,目标是使得每个子集内部的元素尽量相似,不同子集间的元素尽量不相似。这些子集又被称为簇(cluster),一般没有交集。聚类的概念如图10-1所示: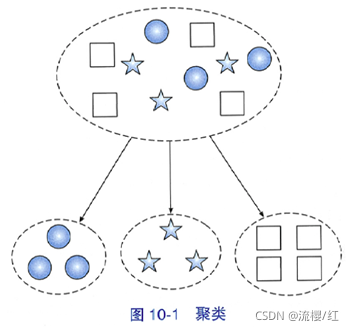
根据元素从属于集合的确定程度,聚类分为硬聚类和软聚类。
- 硬聚类(hard clustering):每个元素被确定地归入一个簇。
- 软聚类(soft clustering):每个元素与每个簇都存在一定的从属程度(隶属度),只不过该程度有大有小。
硬软聚类的区别类似于规则与统计的区别:硬聚类中从属关系是离散的,非常强硬,而软聚类中的从属关系则用一个连续值来衡量,比较灵活。比如图10-2(左图)中的一维数据点大致可划分为2个簇,硬软聚类的结果分别如图10-2的中图和右图所示。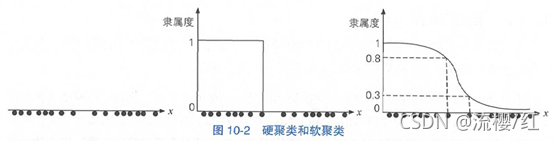
其中,纵坐标表示每个元素与第一个簇的隶属程度。可见硬聚类在簇的边界处采用“一刀切”的方式划分,而软聚类则没有。另一个例子如图10-3所示,如果将元素所属聚类视作离散型随机变量的话,软聚类相当于为每个元素都预测了一个概率分布。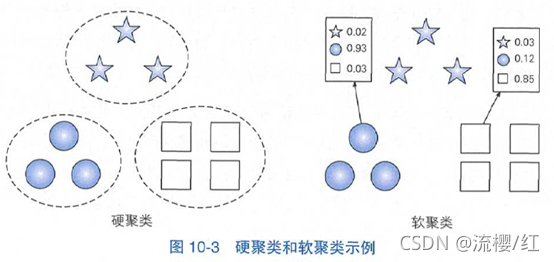 图10-3硬聚类和软聚类示例
图10-3硬聚类和软聚类示例
在实际工程特别是NLP中,由于硬聚类更加简洁,所以使用得更频繁。
一般将聚类时簇的数量视作由使用者指定的超参数,虽然存在许多自动判断的算法(这些方法包括X-means、elbow method等在内不下三十余种,通常需要比较多份不同簇数的聚类结果,计算某个统计量,根据该统计量决定最优簇数。),但它们往往需要人工指定其他超参数,或者比较多份聚类结果。另外,还可以通过层次聚类来得到树形结构的聚类,通过实际需要选取树的某一层作为聚类结果。
根据聚类结果的结构,聚类算法也可以分为划分式(partitional)和层次化(hierarchieal)两种。划分式聚类的结果是一系列不相交的子集,而层次化聚类的结果是一棵树,叶子节点是元素,父节点是簇。本章主要介绍划分聚类。
总之,聚类算法是一个大家族,我们要根据实际需求选择具体方案。
10.1.2 聚类的应用
聚类通常用于数据的预处理,或归档相似的数据。其流程除了不需要标注数据外,与其它已知的大多数任务相同,都是提取特征后交给某个机器学习算法。
不光文本可以聚类,任何事物,只要能够提取特征,都可以聚类。比如电商网站根据价格颜色等特征对商品聚类,应用商店根据App的用户年龄层和下载量等特征进行聚类,电影网站根据影片的题材和年份等特征进行聚类。只要将现实生活中的对象通过特征提取转换为数学世界中的一个向量,就可以进行包括聚类在内的机器学习。
通过聚类,网站可以为用户提供大众化的推荐。比如科幻题材的影片可能被自动归入同一个簇中,当用户点播了其中一部之后,网站就会为其推荐与该影片最相似的另外几部。这种推荐并非针对每个用户的个性化推荐,因为聚类发生时并没有考虑用户个人的喜好因素,而是仅仅提取了电影本身的特征。大众化推荐对新用户而言特别友好,因为刚注册的用户没有多少播放历史,难以预测喜好,这时通过聚类推荐相似影片常常是一个平稳的“冷启动”策略。
辅以少量的人工抽查,聚类还可以自动筛选出包含某些共同特质的样本。比如刷好评的App通常好评数和下载量的比值较高,而用户日活跃数和留存率较低。这些指标的具体数值很难人工确定,但应该存在一个固定的区间。通过聚类将新上架的App归入几个簇之后,每个簇随机选几个样本人工抽查。那些被人工鉴定为刷好评的App所在的簇很可能还含有更多类似的App,从而缩小了抽查范围,降低了人力成本。
总之,聚类是一项非常实用的技术。特别是数据量很大、标注成本过高时,聚类常常是唯一可行的方案。
10.1.3 文本聚类
文本聚类(text clustering,也称文档聚类或document clustering)指的是对文档进行的聚类分析,被广泛用于文本挖掘和信息检索领域。最初文本聚类仅用于文本归档,后来人们又挖掘出了许多新用途,比如改善搜索结果、生成同义词,等等。
在文本的预处理中,聚类同样可以发挥作用。比如在标注语料之前,通常需要从生语料中选取一定数量有代表性的文档作为样本。假设需要标注NN篇,则可以将这些生语料聚类为NN个簇,每个簇随机选取一篇即可。利用每个簇内元素都是相似的这个性质,聚类甚至可以用于文本去重。
文本聚类的基本流程分为特征提取和向量聚类两步,如图10-2所示,聚类的对象是抽象的向量(一维数据点)。如果能将文档表示为向量,就可以对其应用聚类算法。这种表示过程称为特征提取,在10.2节中详细介绍。而一旦将文挡表示为向量,剩下的算法就与文档无关了。这种抽象思维无论是从软件工程的角度,还是从数学应用的角度都十分简洁有效。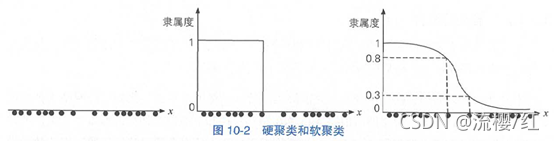
10.2 文档的特征提取
文档是一系列单词(包括标点符号)的有序不定长列表,这些单词的种数无穷大,且可能反复出现。单词本身已然千变万化,它们的不定长组合更加无穷无尽。从细节上尽善尽美地表示一篇文档并不现实,我们必须采用一些有损的模型。
10.2.1 词袋模型
词袋(bag-of-words)是信息检索与自然语言处理中最常用的文档表示模型,它将文档想象为一个装有词语的袋子,通过袋子中每种词语的计数等统计量将文档表示为向量。一个形象的例子如图10-4所示。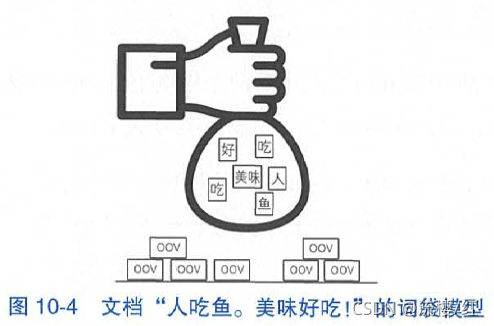
文档含有如下两句话:
人 吃 鱼。
美味 好 吃!
假设这两句话经过分词与停用词过滤后的结果为:
人 吃 鱼
美味 好 吃
将这6个共计5种词语装人袋子后摇一摇,得到的词袋模型如图10-4所示。不在这5种词语之内的词语为OOV,它们散落在词袋之外,为模型所忽略。
假设我们选用词频作为统计指标的话,则该文档的词频统计为:
人=1
吃=2
鱼=1
美味=1
好=1
文档经过该词袋模型得到的向量表示为[1,2,1,1,1],这 5 个维度分别表示这 5 种词语的词频。
一般选取训练集文档的所有词语构成一个词表,词表之外的词语称为 OOV,不予考虑。一旦词表固定下来,假设大小为 NN。则任何一个文档都可以通过这种方法转换为一个NN维向量,比如对于“人吃大鱼”这个文档,它的词频统计为:
人=1
吃=1
鱼=1
美味=0
好=0
那么它的词袋向量就是[1,1,1,0,0],其中后两个维度上的词语都没有出现,所以都是0。而“大”这个词语属于OOV,散落在词袋之外,所以不影响词袋向量。
由于词袋模型不考虑词序,它的计算成本非常低。也正因为这个原因,词袋模型损失了词序中蕴含的语义。比如,对于词袋模型来讲,“人吃鱼”和“鱼吃人”的词袋向量是一模一样的。这听上去很荒谬,但在实际工程中,词袋模型依然是一个很难打败的基线模型。
此外,目前工业界已经发展出很好的词向量表示方法了,如 word2vec/bert 模型等。
10.2.2 词袋中的统计指标
词袋模型并非只是选取词频作为统计指标,而是存在许多选项。常见的统计指标还包括如下几个:
- 布尔词频: 词频非零的话截取为1,否则为0,适合长度较短的数据集
- TF-IDF: 参考9.2.2节,将每个词语的倒排频次也纳入考虑,适合主题较少的数据集
- 词向量: 如果词语本身也是某种向量的话,则可以将所有词语的词向量求和作为文档向量。适合处理 OOV 问题严重的数据集。
- 词频向量: 适合主题较多的数据集
它们的效果与具体数据集相关,需要通过实验验证。一般而言,词频向量适合主题较多的数据集;布尔词频适合长度较短的数据集;TF-IDF适合主题较少的数据集;而词向量则适合处理OOV问题严重的数据集。对新手而言,词频指标通常是一个入门选择。
除了词袋模型之外,神经网络模型也能无监督地生成文档向量,比如自动编码器和受限玻尔兹曼机等。通过神经网络得到的文档向量一般优于词袋向量,但代价是计算开销较大。
本章以词频作为统计指标,用词袋模型来提取文档的特征向量。至此,特征提取介绍完毕。为了清晰地叙述接下来的聚类算法,我们用数学记号正式地描述特征向量。
定义由 nn 个文档组成的集合为 SS,定义其中第 ii 个文档 didi 的特征向量为 didi,其公式如下:
di=(TF(t1,di),TF(t2,di),⋯,TF(tj,di),⋯,TF(tm,di))di=(TF(t1,di),TF(t2,di),⋯,TF(tj,di),⋯,TF(tm,di))
其中 tjtj表示词表中第 jj 种单词,mm 为词表大小, TF(tj,di)TF(tj,di) 表示单词 tjtj 在文档 didi 中的出现次数。为了处理长度不同的文档,通常将文档向量处理为单位向量,即缩放向量使得 ||d||=1||d||=1。
至此,从文本到向量的转换已经执行完毕。转换后得到了一系列向量,或者说一系列数据点。接下来,我们将使用一些聚类算法将这些数据点聚集成不同的簇。
10.3 k均值算法
一种简单实用的聚类算法是k均值算法(k-means),由Stuart Lloyd于1957年提出。该算法虽然无法保证一定能够得到最优聚类结果,但实践效果非常好。基于kk均值算法衍生出许多改进算法,本章先介绍朴素的kk均值算法,然后推导它的一个变种。
10.3.1 基本原理
定义kk均值算法所解决的问题:给定nn个向量 d1,⋯,dn∈ℝld1,⋯,dn∈Rl以及一个整数kk,要求找出kk个簇S1,⋯,SkS1,⋯,Sk以及各自的质心c1,⋯,ck∈ℝlc1,⋯,ck∈Rl,使得下式最小: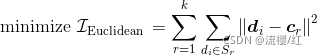
(10.1)(10.1)
其中||di−cr||||di−cr|| 是向量与质心的欧拉距离,EuclideanIEuclidean称作聚类的准则函数(criterion function)。也就是说,kk均值以最小化每个向量到质心的欧拉距离的平方和为准则进行聚类,所以该准则函数有时也称作平方误差和(sum-of-squared-errors)函数。而质心的计算就是簇内数据点的几何平均:![]()
(10.2)(10.2)
其中,sisi 是簇 SiSi 内所有向量之和,称作合成向量(composite vector)。
生成 kk 个簇的 kk均值算法是一种迭代式算法,每次迭代都在上一步的基础上优化聚类结果,步骤如下:
- (1)选取kk个点作为kk个簇的初始质心;
- (2)将所有点分别分配给最近的质心所在的簇;
- (3)重新计算每个簇的质心;
- (4)重复步骤(2)和步骤(3)直到质心不再发生变化。
kk均值算法虽然无法保证收敛到全局最优,但能够有效地收敛到一个局部最优点。对于该算法,重点需要关注两个问题,即初始质心的选取和两点距离的度量。
10.3.2 初始质心的选取
由于kk均值不保证收敛到全局最优,所以初始质心的选取对kk均值的运行结果影响非常大,如果选取不当,则可能收敛到一个较差的局部最优点。
朴素实现经常用随机选取的方式确定初始质心,相当于逃避了这个问题。使用这种实现时,用户必须多运行几次,根据准则函数选取最佳结果。当数据量很大时,往往不够经济。
一种更高效的方法是,将质心的选取也视作准则函数进行迭代式优化的过程。其具体做法是,先随机选择第一个数据点作为质心,视作只有一个簇计算准则函数。同时维护每个点到最近质心的距离的平方,作为一个映射数组MM。接着,随机取准则函数值的一部分记作ΔΔ。遍历剩下的所有数据点,若该点到最近质心的距离的平方小于ΔΔ,则选取该点添加到质心列表,同时更新准则函数与MM。如此循环多次,直至凑足kk个初始质心。这种方法可行的原理在于,每新增一个质心,都保证了准则函数的值下降一个随机比率。而朴素实现相当于每次新增的质心都是完全随机的,准则函数的增减无法控制。
考虑到kk均值是一种迭代式的算法, 需要反复计算质心与两点距离,这部分计算通常是效瓶颈。为了改进朴素 kk均值算法的运行效率,HanLP利用种更快的准则函数实现了kk均值的变种。
10.3.3 更快的准则函数
将一个点移入最近的质心所属的簇,等价于这次移动让准则函数减小最快。在kk均值的迭代过程中,数据点被分配给最近的质心,导致簇中的元素频繁发生变动。当移动发生时,我们希望快速计算准则函数的变化。本节介绍另一种准则函数以及它的优势。除了式(10.1)所示的欧拉准则函数,还存在一种基于余弦距离的准则函数: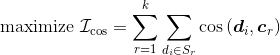
该函数使用余弦函数衡量点与质心的相似度,目标是最大化同簇内点与质心的相似度。将向量夹角计算公式代入,该准则函数变换为: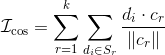
代入后变换为:
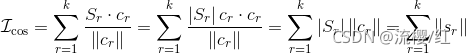
(10.4)(10.4)
也就是说,余弦准则函数等于 kk 个簇各自合成向量的长度之和。比较之前的准则函数会发现在数据点从原簇移动到新簇时,EuclideanIEuclidean需要重新计算质心,以及两个簇内所有点到新质心的距离。而对于cosIcos,由于发生改变的只有原簇和新簇两个合成向量,只需求两者的长度即可,计算量减小不少。
基于新准则函数cosIcos,kk均值变种算法的流程如下:
- (1)选取kk个点作为kk个簇的初始质心;
- (2)将所有点分别分配绐最近的质心所在的簇;
- (3)对每个点,计算将其移入另一个簇时cosIcos的增大量,找出最大增大量,并完成移动;
- (4)重复步骤(3)直到达到最大迭代次数,或簇的划分不再变化。
该算法的实现位于com.hankcs.hanlp.mining.cluster.ClusterAnalyzer#refine_clusters,接口如下:
该接口不仅在kk均值中反复调用,在后面的新算法中也会反复用到。
10.3.4 实现
在 HanLP 中,聚类算法实现为 ClusterAnalyzer,用户可以将其想象为一个文档 id 到文档向量的映射容器。创建对象后,往容器中加入若干文档之后即可调用kk均值接口得到指定数量的簇。
此处以某音乐网站中的用户聚类为案例讲解聚类模块的用法。假设该音乐网站将 6 位用户点播的歌曲的流派记录下来,并且分别拼接为 6 段文本。给定用户名称与这 6 段播放历史,要求将这 6 位用户划分为 3 个簇。实现代码如下:
from pyhanlp import *
ClusterAnalyzer = JClass('com.hankcs.hanlp.mining.cluster.ClusterAnalyzer')
if __name__ == '__main__':
analyzer = ClusterAnalyzer()
analyzer.addDocument("赵一", "流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 摇滚, 摇滚, 摇滚, 摇滚")
analyzer.addDocument("钱二", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("张三", "古典, 古典, 古典, 古典, 民谣, 民谣, 民谣, 民谣")
analyzer.addDocument("李四", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 金属, 金属, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("王五", "流行, 流行, 流行, 流行, 摇滚, 摇滚, 摇滚, 嘻哈, 嘻哈, 嘻哈")
analyzer.addDocument("马六", "古典, 古典, 古典, 古典, 古典, 古典, 古典, 古典, 摇滚")文档加入后,ClusterAnalyzer内部会自动对其分词、去除停用词、转换为词袋向量,如表10-1所示。
表10-1文本聚类中的词袋向量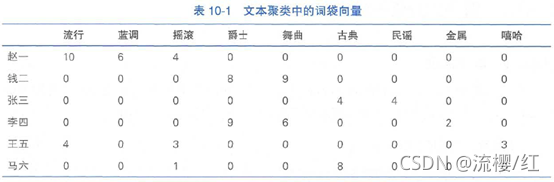
有了这些向量后,只需调用ClusterAnalyzer的kmeans方法就可以得到指定数量的簇,以3为例:
print(analyzer.kmeans(3))该方法返回指定数量的簇构成的集合,每个簇是一个Set,内部元素为文档的id。此处由于id是姓名,所以可以打印出来直观地感受效果:
[[李四, 钱二], [王五, 赵一], [张三, 马六]]
根据该结果,李四和钱二同属一个簇。对照表10-1,这二人都喜欢爵士和舞曲。类似地,王五和赵一都喜欢流行和摇滚音乐,张三和马六都喜欢古典音乐。通过kk均值聚类算法,我们成功地将用户按兴趣分组,获得了“人以群分”的效果。
聚类结果中簇的顺序是随机的,每个簇中的元素也是无序的。由于kk均值是个随机算法,有小概率得到不同的结果。
该聚类模块可以接受任意文本作为文档,而不需要用特殊分隔符隔开单词。另外,该模块还接受单词列表作为输入,用户可以将英文、日文等预先切分为单词列表后输入本模块。统计方法适用于所有语种,不必拘泥于中文。
无论朴素实现还是变种,kk均值算法的复杂度都是O(n)O(n),其中nn是向量的个数。虽然任何变种都无法突破该理论值,但当kk较大时,还存在另一种更快的改进kk均值算法。
10.4 重复二分聚类算法
10.4.1 基本原理
重复二分聚类(repeated bisection clustering)是kk均值算法的效率加强版,其名称中的bisection是“二分”的意思,指的是反复对子集进行二分。该算法的步骤如下:
- (1)挑选一个簇进行划分;
- (2)利用kk均值算法将该簇划分为2个子集;
- (3)重复步骤(1)和步骤(2),直到产生足够数量的簇。
该算法的流程如图10-5所示,每次产生的簇由上到下形成了一棵二叉树结构。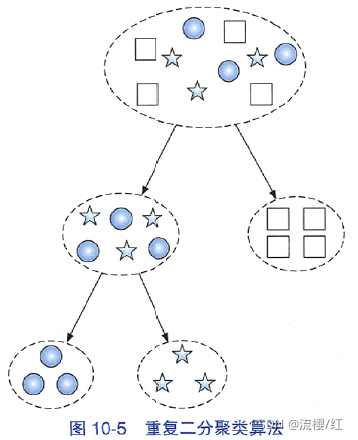
正是由于这个性质,重复二分聚类算得上一种基于划分的层次聚类算法。如果我们把算法运行的中间结果存储起来,就能输出一棵具有层级关系的树。树上每个节点都是一个簇,父子节点对应的簇满足包含关系。虽然每次划分都基于kk均值,由于每次二分都仅仅在一个子集上进行,输入数据少,算法自然更快。
至于步骤(1)中如何挑选簇进行划分,有多种方案。可用的标准有:
- 簇的体积最大;
- 簇内元素到质心的相似度最小;
- 二分后准则函数的增幅(gain)最大。
HanLP采用了最后一种策略,每产生一个新簇,都试着将其二分并计算准则函数的增幅。然后对增幅最大的簇执行二分,重复多次直到满足算法停止条件。
10.4.2 自动判断聚类个数kk
在重复二分聚类算法中,有一种变通的方法,那就是通过给准则函数的增幅设定阈值 ββ 来自动判断 kk。此时算法的停止条件为,当一个簇的二分增幅小于 ββ 时不再对该簇进行划分,即认为这个簇已经达到最终状态,不可再分。当所有簇都不可再分时,算法终止,最终产生的聚类数量就不再需要人工指定了。
在HanLP中,重复二分聚类算法提供了3种接口,分别需要指定kk、ββ或两者同时指定。当同时指定kk和ββ时,满足两者的停止条件中任意一个算法都会停止。当只指定一个时,另一个停止条件不起作用。这3个接口列举如下:![]()
对于上一个例子,以β=1.0作为参数试试自动判断聚类个数k,发现恰好可以得到理想的结果,示例如下:
print(analyzer.repeatedBisection(1.)) #自动判断聚类数量k当然,β的取值也很难确定,也许这些所谓的自动判断算法只是用一种麻烦替换了另一种麻烦而已。
10.4.3 实现
from pyhanlp import *
ClusterAnalyzer = JClass('com.hankcs.hanlp.mining.cluster.ClusterAnalyzer')
if __name__ == '__main__':
analyzer = ClusterAnalyzer()
analyzer.addDocument("赵一", "流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 摇滚, 摇滚, 摇滚, 摇滚")
analyzer.addDocument("钱二", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("张三", "古典, 古典, 古典, 古典, 民谣, 民谣, 民谣, 民谣")
analyzer.addDocument("李四", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 金属, 金属, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("王五", "流行, 流行, 流行, 流行, 摇滚, 摇滚, 摇滚, 嘻哈, 嘻哈, 嘻哈")
analyzer.addDocument("马六", "古典, 古典, 古典, 古典, 古典, 古典, 古典, 古典, 摇滚")
print(analyzer.repeatedBisection(3)) # 重复二分聚类
print(analyzer.repeatedBisection(1.0)) # 自动判断聚类数量k10.5 标准化评测
前面介绍的音乐案例只有6个样本,只能说是玩具数据(toy data)。用玩具数据来调试算法很方便,但不足以说明算法的实用性。本节我们将介绍聚类任务的标准化评测手段,并且给出两种算法的分值。
10.5.1 PP、RR和F1F1值
聚类任务常用的一种评测手段是沿用分类任务的F1F1值,将一些人工分好类别的文挡去掉标签交给聚类分析器,统计结果中有多少同类别的文档属于同一个簇。形式化描述,给定簇jj以及类别ii,定义nijnij表示簇中有多少类别ii的文档,njnj为簇jj中的文档总数,nini为类别ii中的文档总数。对每种ii和jj的组合,都计算如下指标: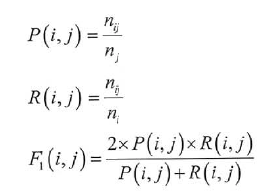
为了可读性,我们并不需要那么多的F1F1值。对整个评测任务而言,它的综合F1F1值是所有类目上分值的加权平均,如下式所述:
F1=∑ininmax{F1(i,j)}F1=∑ininmax{F1(i,j)}
其中,nn为文档总数,即
n=∑inin=∑ini
10.5.2 语料库
本次评测选择搜狗实验室提供的文本分类语料的一个子集,我称它为“搜狗文本分类语料库迷你版”。该迷你版语料库分为5个类目,每个类目下1000篇文章,共计5000篇文章。配套代码将自动下载该语料到data/test/搜狗文本分类语料库迷你版,其目录结构如下:
第10.5.3节和第11章将用到这个语料库,搜狗实验室发布的原版语料库为GBK编码,现已转换为UTF-8编码。
10.5.3 评测试验
评测程序遍历子目录读取文档,以子目录+文件名作为id将文档传入聚类分析器进行聚类,并且计算F1F1值返回。
代码(tests/book/ch10/demo_clustering_f.py)如下:
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
def test_data_path():
"""
获取测试数据路径,位于$root/data/test,根目录由配置文件指定。
:return:
"""
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在 MSR语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
sogou_corpus_path = ensure_data('搜狗文本分类语料库迷你版', 'http://file.hankcs.com/corpus/sogou-text-classification-corpus-mini.zip')
## ===============================================
## 以下开始聚类
ClusterAnalyzer = JClass('com.hankcs.hanlp.mining.cluster.ClusterAnalyzer')
if __name__ == '__main__':
for algorithm in "kmeans", "repeated bisection":
print("%s F1=%.2f\n" % (algorithm, ClusterAnalyzer.evaluate(sogou_corpus_path, algorithm) * 100))运行结果如下:
kmeans F1=83.74
repeated bisection F1=85.58
评测结果如下表:
| 算法 | F1 | 耗时 |
|---|---|---|
| k均值 | 83.74 | 67秒 |
| 重复二分聚类 | 85.58 | 24秒 |
对比两种算法,重复二分聚类不仅准确率比kk均值更高,而且速度是kk均值的3倍。然而重复二分聚类成绩波动较大,需要多运行几次才可能得出这样的结果。也许85%左右的准确率并不好看,但考虑到聚类是一种无监督学习,其性价比依然非常可观。
10.6 总结
本章我们在文档上应用了kk均值和重复二分聚类两种聚类算法,并且比较了它们的性能。围绕这两个算法,我们还学习了词袋模型和文档向量等重要概念。这些概念不仅用于文本聚类,还可以用于其他NLP任务。
在评测试验中,HanLP实现的无监督聚类算法能够给出85%左右的准确率,展示了极高的性价比。然而无监督聚类算法无法学习人类的偏好对文档进行划分,也无法学习每个簇在人类那里究竟叫做什么,下一章我们将解决这两个问题。
本章其它相关代码
# -*- coding:utf-8 -*-
# Author: hankcs
# Date: 2020-07-31 20:55
# 《自然语言处理入门》第 10 章 文本聚类 (这段代码来自书籍之外的附赠答疑)
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
import os
from pyhanlp.static import STATIC_ROOT, HANLP_JAR_PATH
java_code_path = os.path.join(STATIC_ROOT, 'MyClusterAnalyzer.java')
with open(java_code_path, 'w') as out:
java_code = """
import com.hankcs.hanlp.mining.cluster.ClusterAnalyzer;
import com.hankcs.hanlp.mining.cluster.SparseVector;
public class MyClusterAnalyzer<K> extends ClusterAnalyzer<K>
{
public SparseVector toVector(String document)
{
return toVector(preprocess(document));
}
}
"""
out.write(java_code)
os.system('javac -cp {} {} -d {}'.format(HANLP_JAR_PATH, java_code_path, STATIC_ROOT))
# 编译结束才可以启动hanlp
from pyhanlp import *
ClusterAnalyzer = JClass('MyClusterAnalyzer')
if __name__ == '__main__':
analyzer = ClusterAnalyzer()
vec = analyzer.toVector("古典, 古典, 古典, 古典, 古典, 古典, 古典, 古典, 摇滚")
print(vec)
# print(analyzer.kmeans(3))
# print(analyzer.repeatedBisection(3))
# print(analyzer.repeatedBisection(1.0)) # 自动判断聚类数量k

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)