粒子群算法求解带约束优化问题 源码实现
粒子群算法求解带约束优化问题 源码实现python实现。带你体验下粒子群算法是如何求解带等式约束、不等式约束、上下限约束的问题。
算法原理
之前求解的无约束的问题。
粒子群算法求解无约束优化问题 源码实现
算法原理如下

今天讲解下求解约束优化的问题。该问题常用的方法是罚函数法。即如果一个解x不满足约束条件,就对适应度值设置一个惩罚项。它的思想类似线性规划内点法,都是通过增加罚函数,迫使模型在迭代计算的过程中始终在可行域内寻优。
假设有如下带约束的优化问题

问题中既含有等式约束,也含有不等式约束,当一个解x不满足约束条件时,则会对目标函数增加惩罚项,这样就把带约束优化问题变成无约束优化问题,新的目标函数如下:

其中σ是惩罚因子,一般取σ=t√t ,P(x)是整体惩罚项,P(x)的计算方法如下:
-
对于不等式gi(x)<=0,惩罚项

即如果gi(x)<=0,则ei(x)=0,否则ei(x)=-gi(x) -
对于等式约束需要先转换成不等式约束,一个简单的方法设定一个等式约束容忍度值ε,新的不等式约束为

因此等式约束的惩罚项为

整体惩罚性P(x)是各个约束惩罚项的和,即:

由于约束条件之间的差异,某些约束条件可能对个体违反程度起着决定性的作用,为了平衡这种差异,对惩罚项做归一化处理,下面的公式推导将不区分等式约束和不等式约束,在实际处理中做区分即可:

其中Lj表示每个约束条件的违背程度,m为约束条件的个数。公式中分子的意思是,对每个粒子xi计算违反第j个约束的惩罚项,然后求和;分母的意思:对每个粒子xi计算违背每个约束的惩罚项,然后求和,因此Lj也可以看成是第j个约束惩罚项的权重。
最后得到的粒子xi的整体惩罚项P(x)的计算公式:

在粒子群算法中,每一步迭代都会更新Pbest和Gbest,虽然可以将有约束问题转换为无约束问题进行迭代求解,但是问题的解xi依然存在不满足约束条件的情况,因此需要编制一些规则来比较两个粒子的优劣,规则如下:
- 如果两个粒子xi和xj都可行,则比较其适应度函数f(xi)和f(xj),值小的粒子为优。
- 当两个粒子xi和xj都不可行,则比较惩罚项P(xi)和P(xj),违背约束程度小的粒子更优。
- 当粒子xi可行而粒子xj不可行,选可行解。
对于粒子的上下限约束 可以体现在位置更新函数里,不必加惩罚项。 具体思路就是遍历每一个粒子的位置,如果超除上下限,位置则更改为上下限中的任何一个位置
算例
语言python3.7
问题如下:

此函数图像

为方便粒子群算法的迭代写代码,肯定要如下格式矩阵,用来存储粒子群每个粒子xi的历史最优位置Pbest、总的适应度值fitness、目标函数的值、约束1的惩罚项e1、约束2的惩罚项e2
| 粒子序号 | Pbest_fitness | Pbest_e | fitness | f | e1 | e2 | e |
|---|---|---|---|---|---|---|---|
| x1 | l历史最优位置对应的适应度 | 历史最优位置对应的惩罚项 | 当前的适应度fitness=f+e | 当前目标函数值 | 约束1的惩罚项e1 | 约束2的惩罚项e2 | 惩罚项的和e=L1e1+L2e2 |
| x2 | |||||||
| … |
步骤1:初始化参数
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# PSO的参数
w = 1 # 惯性因子,一般取1
c1 = 2 # 学习因子,一般取2
c2 = 2 #
r1 = None # 为两个(0,1)之间的随机数
r2 = None
dim = 2 # 维度的维度#对应2个参数x,y
size = 100 # 种群大小,即种群中小鸟的个数
iter_num = 1000 # 算法最大迭代次数
max_vel = 0.5 # 限制粒子的最大速度为0.5
fitneess_value_list = [] # 记录每次迭代过程中的种群适应度值变化
步骤2:这里定义一些参数,分别是计算适应度函数和计算约束惩罚项函数
def calc_f(X):
"""计算粒子的的适应度值,也就是目标函数值,X 的维度是 size * 2 """
A = 10
pi = np.pi
x = X[0]
y = X[1]
return 2 * A + x ** 2 - A * np.cos(2 * pi * x) + y ** 2 - A * np.cos(2 * pi * y)
def calc_e1(X):
"""计算第一个约束的惩罚项"""
e = X[0] + X[1] - 6
return max(0, e)
def calc_e2(X):
"""计算第二个约束的惩罚项"""
e = 3 * X[0] - 2 * X[1] - 5
return max(0, e)
def calc_Lj(e1, e2):
"""根据每个粒子的约束惩罚项计算Lj权重值,e1, e2列向量,表示每个粒子的第1个第2个约束的惩罚项值"""
# 注意防止分母为零的情况
if (e1.sum() + e2.sum()) <= 0:
return 0, 0
else:
L1 = e1.sum() / (e1.sum() + e2.sum())
L2 = e2.sum() / (e1.sum() + e2.sum())
return L1, L2
步骤3:定义粒子群算法的速度更新函数,位置更新函数
def velocity_update(V, X, pbest, gbest):
"""
根据速度更新公式更新每个粒子的速度
种群size=20
:param V: 粒子当前的速度矩阵,20*2 的矩阵
:param X: 粒子当前的位置矩阵,20*2 的矩阵
:param pbest: 每个粒子历史最优位置,20*2 的矩阵
:param gbest: 种群历史最优位置,1*2 的矩阵
"""
r1 = np.random.random((size, 1))
r2 = np.random.random((size, 1))
V = w * V + c1 * r1 * (pbest - X) + c2 * r2 * (gbest - X) # 直接对照公式写就好了
# 防止越界处理
V[V < -max_vel] = -max_vel
V[V > max_vel] = max_vel
return V
def position_update(X, V):
"""
根据公式更新粒子的位置
:param X: 粒子当前的位置矩阵,维度是 20*2
:param V: 粒子当前的速度举着,维度是 20*2
"""
X=X+V#更新位置
size=np.shape(X)[0]#种群大小
for i in range(size):#遍历每一个例子
if X[i][0]<=1 or X[i][0]>=2:#x的上下限约束
X[i][0]=np.random.uniform(1,2,1)[0]#则在1到2随机生成一个数
if X[i][1] <= -1 or X[i][0] >= 0:#y的上下限约束
X[i][1] = np.random.uniform(-1, 0, 1)[0] # 则在-1到0随机生成一个数
return X
步骤4:每个粒子历史最优位置更优函数,以及整个群体历史最优位置更新函数,和无约束约束优化代码类似,所不同的是添加了违反约束的处理过程
def update_pbest(pbest, pbest_fitness, pbest_e, xi, xi_fitness, xi_e):
"""
判断是否需要更新粒子的历史最优位置
:param pbest: 历史最优位置
:param pbest_fitness: 历史最优位置对应的适应度值
:param pbest_e: 历史最优位置对应的约束惩罚项
:param xi: 当前位置
:param xi_fitness: 当前位置的适应度函数值
:param xi_e: 当前位置的约束惩罚项
:return:
"""
# 下面的 0.0000001 是考虑到计算机的数值精度位置,值等同于0
# 规则1,如果 pbest 和 xi 都没有违反约束,则取适应度小的
if pbest_e <= 0.0000001 and xi_e <= 0.0000001:
if pbest_fitness <= xi_fitness:
return pbest, pbest_fitness, pbest_e
else:
return xi, xi_fitness, xi_e
# 规则2,如果当前位置违反约束而历史最优没有违反约束,则取历史最优
if pbest_e < 0.0000001 and xi_e >= 0.0000001:
return pbest, pbest_fitness, pbest_e
# 规则3,如果历史位置违反约束而当前位置没有违反约束,则取当前位置
if pbest_e >= 0.0000001 and xi_e < 0.0000001:
return xi, xi_fitness, xi_e
# 规则4,如果两个都违反约束,则取适应度值小的
if pbest_fitness <= xi_fitness:
return pbest, pbest_fitness, pbest_e
else:
return xi, xi_fitness, xi_e
def update_gbest(gbest, gbest_fitness, gbest_e, pbest, pbest_fitness, pbest_e):
"""
更新全局最优位置
:param gbest: 上一次迭代的全局最优位置
:param gbest_fitness: 上一次迭代的全局最优位置的适应度值
:param gbest_e:上一次迭代的全局最优位置的约束惩罚项
:param pbest:当前迭代种群的最优位置
:param pbest_fitness:当前迭代的种群的最优位置的适应度值
:param pbest_e:当前迭代的种群的最优位置的约束惩罚项
:return:
"""
# 先对种群,寻找约束惩罚项=0的最优个体,如果每个个体的约束惩罚项都大于0,就找适应度最小的个体
pbest2 = np.concatenate([pbest, pbest_fitness.reshape(-1, 1), pbest_e.reshape(-1, 1)], axis=1) # 将几个矩阵拼接成矩阵 ,4维矩阵(x,y,fitness,e)
pbest2_1 = pbest2[pbest2[:, -1] <= 0.0000001] # 找出没有违反约束的个体
if len(pbest2_1) > 0:
pbest2_1 = pbest2_1[pbest2_1[:, 2].argsort()] # 根据适应度值排序
else:
pbest2_1 = pbest2[pbest2[:, 2].argsort()] # 如果所有个体都违反约束,直接找出适应度值最小的
# 当前迭代的最优个体
pbesti, pbesti_fitness, pbesti_e = pbest2_1[0, :2], pbest2_1[0, 2], pbest2_1[0, 3]
# 当前最优和全局最优比较
# 如果两者都没有约束
if gbest_e <= 0.0000001 and pbesti_e <= 0.0000001:
if gbest_fitness < pbesti_fitness:
return gbest, gbest_fitness, gbest_e
else:
return pbesti, pbesti_fitness, pbesti_e
# 有一个违反约束而另一个没有违反约束
if gbest_e <= 0.0000001 and pbesti_e > 0.0000001:
return gbest, gbest_fitness, gbest_e
if gbest_e > 0.0000001 and pbesti_e <= 0.0000001:
return pbesti, pbesti_fitness, pbesti_e
# 如果都违反约束,直接取适应度小的
if gbest_fitness < pbesti_fitness:
return gbest, gbest_fitness, gbest_e
else:
return pbesti, pbesti_fitness, pbesti_e
步骤5:PSO
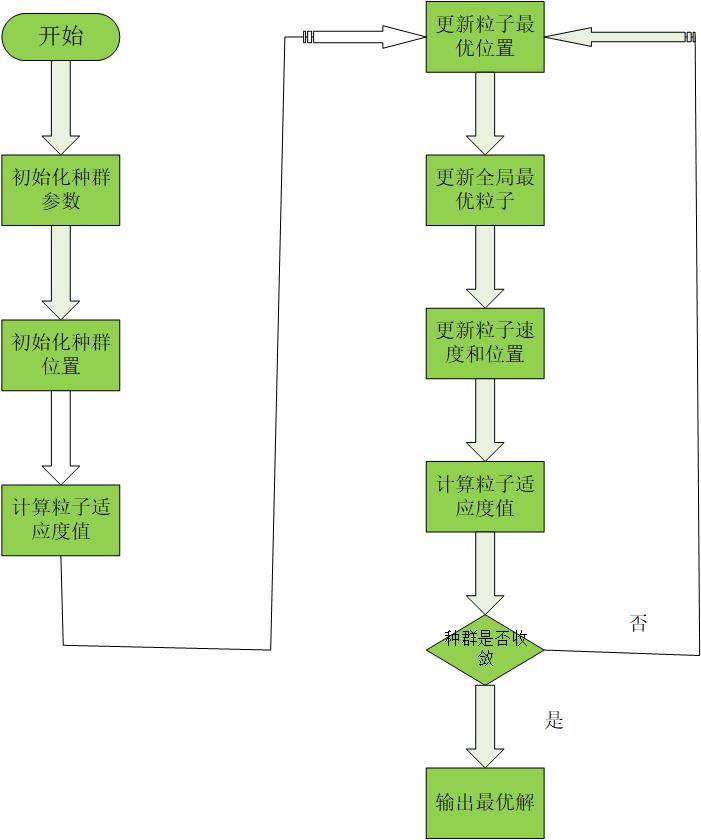
流程图如图:

约束体现在更新粒子最优 ,和全局最优上。
# 初始化一个矩阵 info, 记录:
# 0、种群每个粒子的历史最优位置对应的适应度,
# 1、历史最优位置对应的惩罚项,
# 2、当前适应度,
# 3、当前目标函数值,
# 4、约束1惩罚项,
# 5、约束2惩罚项,
# 6、惩罚项的和
# 所以列的维度是7
info = np.zeros((size, 7))
# 初始化种群的各个粒子的位置
# 用一个 20*2 的矩阵表示种群,每行表示一个粒子
X = np.random.uniform(-5, 5, size=(size, dim))
# 初始化种群的各个粒子的速度
V = np.random.uniform(-0.5, 0.5, size=(size, dim))
# 初始化粒子历史最优位置为当当前位置
pbest = X
# 计算每个粒子的适应度
for i in range(size):
info[i, 3] = calc_f(X[i]) # 目标函数值
info[i, 4] = calc_e1(X[i]) # 第一个约束的惩罚项
info[i, 5] = calc_e2(X[i]) # 第二个约束的惩罚项
# 计算惩罚项的权重,及适应度值
L1, L2 = calc_Lj(info[i, 4], info[i, 5])
info[:, 2] = info[:, 3] + L1 * info[:, 4] + L2 * info[:, 5] # 适应度值
info[:, 6] = L1 * info[:, 4] + L2 * info[:, 5] # 惩罚项的加权求和
# 历史最优
info[:, 0] = info[:, 2] # 粒子的历史最优位置对应的适应度值
info[:, 1] = info[:, 6] # 粒子的历史最优位置对应的惩罚项值
# 全局最优
gbest_i = info[:, 0].argmin() # 全局最优对应的粒子编号
gbest = X[gbest_i] # 全局最优粒子的位置
gbest_fitness = info[gbest_i, 0] # 全局最优位置对应的适应度值
gbest_e = info[gbest_i, 1] # 全局最优位置对应的惩罚项
# 记录迭代过程的最优适应度值
fitneess_value_list.append(gbest_fitness)
# 接下来开始迭代
for j in range(iter_num):
# 更新速度
V = velocity_update(V, X, pbest=pbest, gbest=gbest)
# 更新位置
X = position_update(X, V)
# 计算每个粒子的目标函数和约束惩罚项
for i in range(size):
info[i, 3] = calc_f(X[i]) # 目标函数值
info[i, 4] = calc_e1(X[i]) # 第一个约束的惩罚项
info[i, 5] = calc_e2(X[i]) # 第二个约束的惩罚项
# 计算惩罚项的权重,及适应度值
L1, L2 = calc_Lj(info[i, 4], info[i, 5])
info[:, 2] = info[:, 3] + L1 * info[:, 4] + L2 * info[:, 5] # 适应度值
info[:, 6] = L1 * info[:, 4] + L2 * info[:, 5] # 惩罚项的加权求和
# 更新历史最优位置
for i in range(size):
pbesti = pbest[i]
pbest_fitness = info[i, 0]
pbest_e = info[i, 1]
xi = X[i]
xi_fitness = info[i, 2]
xi_e = info[i, 6]
# 计算更新个体历史最优
pbesti, pbest_fitness, pbest_e = \
update_pbest(pbesti, pbest_fitness, pbest_e, xi, xi_fitness, xi_e)
pbest[i] = pbesti
info[i, 0] = pbest_fitness
info[i, 1] = pbest_e
# 更新全局最优
pbest_fitness = info[:, 2]
pbest_e = info[:, 6]
gbest, gbest_fitness, gbest_e = \
update_gbest(gbest, gbest_fitness, gbest_e, pbest, pbest_fitness, pbest_e)
# 记录当前迭代全局之硬度
fitneess_value_list.append(gbest_fitness)
# 最后绘制适应度值曲线
print('迭代最优结果是:%.5f' % calc_f(gbest))
print('迭代最优变量是:x=%.5f, y=%.5f' % (gbest[0], gbest[1]))
print('迭代约束惩罚项是:', gbest_e)
#迭代最优结果是:1.00491
#迭代最优变量是:x=1.00167, y=-0.00226
#迭代约束惩罚项是: 0.0
# 从结果看,有多个不同的解的目标函数值是相同的,多测试几次就发现了
# 绘图
plt.plot(fitneess_value_list[: 30], color='r')
plt.title('迭代过程')
plt.show()



作者:电气 余登武


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 78
78 1
1- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)