SVM(支持向量机)基于Python的简单可视化实现
个人学习SVM的心得
本篇内容参考了这篇博客且内容不涉及数学证明,只是自己学习SVM时记下的内容,方便回顾
一、概念
什么是SVM?维基百科中对于SVM的定义是这样的:
支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。
看上去很深奥对吧,简单来说,个人认为,SVM其实就是一个二类分类的模型,将两类特征点分类,他的基本模型是的定义在特征空间上的间隔最大的线性分类器,而SVM的学习策略就是间隔最大化。
二、对于SVM的直观理解
1.线性分类模型
我们将两类特征点以散点图的形式画在直角坐标系上,每个点以(x, y)的方式表现,其中x为特征点的特征向量(图中我们默认每个点的特征都是一个,以二维的形式方便理解),而y为分类的标签(我们一般选择-1和1作为分类的标签)
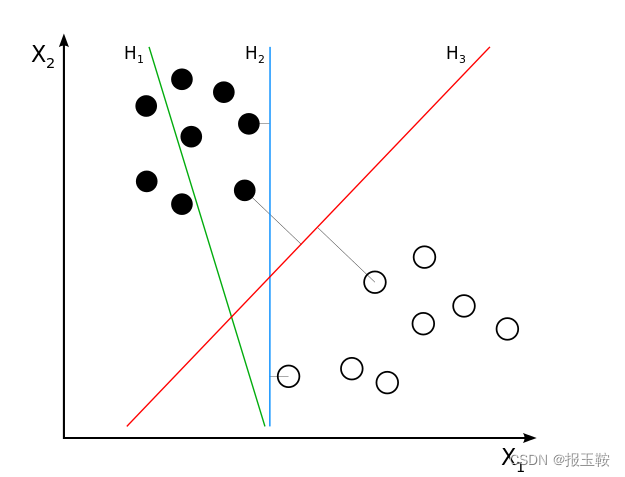
假设该坐标上的黑点和白点分别代表了两种特征点,而三根线(H1, H2, H3)是三种分类器,那么那个分类器是最好的呢。
以我们的直观来说,肯定是H3更适合
虽然看上去H2也能够完美地将图中地两种点分开,但是,这些点是我们观测的数据,既然是观测的,那么数据肯定多少会有点误差,也就是说,这些点的真实位置可能还要改变;况且,这仅仅只是我们训练集的数据,但凡测试集的数据和训练集的差别过大,这个分类器就不起作用了。因此我们需要一个容差率大一点的分类器
所以,H3确实是最适合的分类器,但是,为什么呢?为什么H3是最合适的?
SVM的提出者认为,这根线(分类器)分别向两边的两类点移动,一旦碰到一边的向量就停止,另一边也是如此,这些碰到的向量就被称为支持向量(Support Vector),他认为,支持向量到分割线(分类器)的距离最大即是最适合的分类器。然而,这里又有一个问题出现了,只要支持向量到分割线的距离最大就行,那这样的线不是有无数个吗?
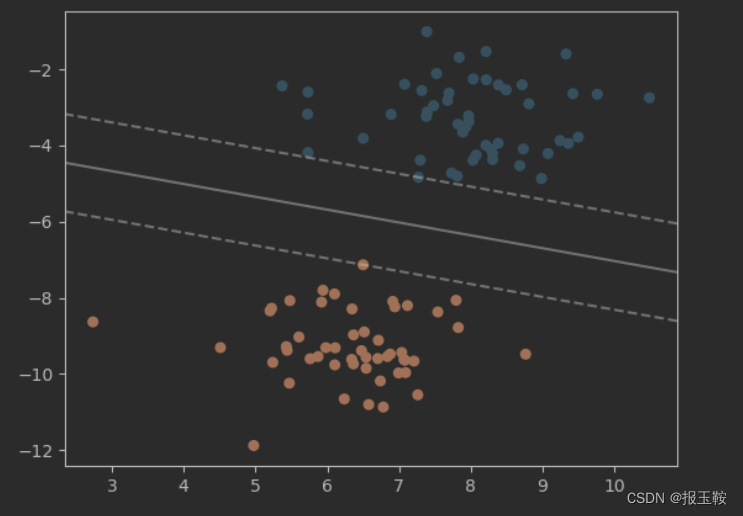
如上图所示,虚线所触碰到的向量即为支持向量,那么,按照之前的说法,其实只要是在两根虚线包围的区域内,且和虚线平行的线,都可以作为我们目前来说的最佳的分类器。这显然是不合理的,我们必须得要确定分类器的唯一性,因此,他又提出,分类器的位置应该位于中间,即支持向量到分类器的位置是一样的(即如果两根虚线的间距是d,那么支持向量到分类器的位置应该是
d
2
{d \over 2}
2d),而这个间距则被称之为硬间距(Hard Margin),分类器称之为超平面(Hyper Plane)
因此,对于这种模型来说,我们就是通过硬间距最大化来训练学习得到一个分类器,即为硬间距SVM
2.非线性分类器
当然,以上的说法都是基于训练数据都是线性可分的为前提来说的,但是在通常的实际情况下,我们的训练数据大多都是线性不可分的,那么该怎么解决呢?
这时,我们引入核函数(Kernel)的概念,将低维的训练数据向高维空间(甚至是无穷维的空间)中映射,此时的数据再高维空间中就会变得线性可分(这个在数学上是可以证明的)
常用的核函数:
- Linear(线性内核): K ( x , y ) = x T y {K(x, y) = x^Ty} K(x,y)=xTy
- Poly(多项式核): K ( x , y ) = ( x T y + 1 ) d {K(x, y) = (x^Ty + 1)^d} K(x,y)=(xTy+1)d
- Rbf(高斯径向基函数核): K ( x , y ) = e ∣ ∣ x − y ∣ ∣ 2 σ 2 {K(x, y) = e^{||x - y||^2 \over \sigma^2}} K(x,y)=eσ2∣∣x−y∣∣2
- Tanh(Tanh核):
K
(
x
,
y
)
=
t
a
n
h
(
β
x
T
y
+
b
)
K(x, y) = tanh(\beta x^Ty + b)
K(x,y)=tanh(βxTy+b)
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = {e^x-e^{-x} \over e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
三、Python代码实现
首先是导包
# 导库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
然后是创建训练样本并分类,然后呈现出来
# 创建数据点并分类
a, b = make_blobs(n_samples=100, centers=2, random_state=6)
# 以散点图的形式把数据画出来
plt.scatter(a[:, 0], a[:, 1], c=b, s=30, cmap=plt.cm.Paired)
利用sklearn中的内置库创建一个支持向量机模型(核函数我这里选择使用Ploy核)
# 创建一个多项式内核的支持向量机模型
clf = svm.SVC(kernel='poly', C=1000)
clf.fit(a, b)
其余部分
# 建立图像坐标
axis = plt.gca()
xlim = axis.get_xlim()
ylim = axis.get_ylim()
# 生成两个等差数列
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
# print("xx:", xx)
# print("yy:", yy)
X, Y = np.meshgrid(xx, yy)
# print("X:", X)
# print("Y:", Y)
xy = np.vstack([X.ravel(), Y.ravel()]).T
Z = clf.decision_function(xy).reshape(X.shape)
# 画出分界线
axis.contour(X, Y, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
axis.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100, linewidths=1, facecolors='none')
plt.show()
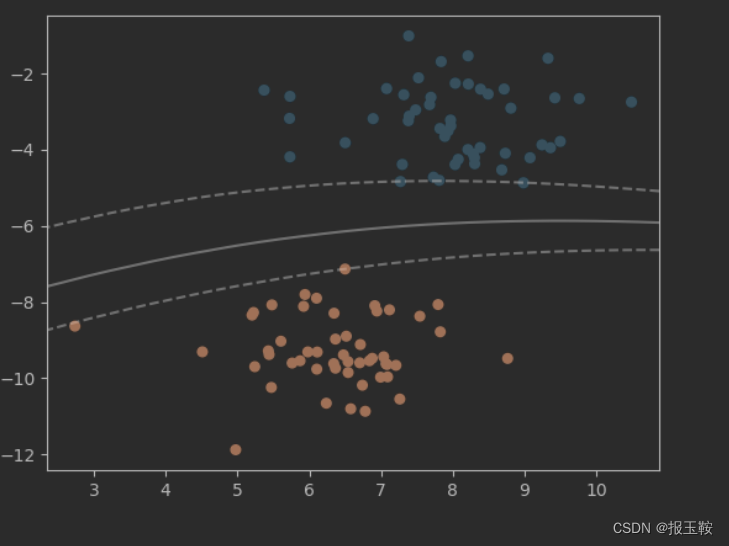
最终的效果

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 11
11 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容
 免费领云主机
免费领云主机




 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)