泰坦尼克号数据集处理
1、导入数据库import tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport urllib.requestimport os%matplotlib inlineprint("Tensorflow版本是:",tf.__version__)2、下载泰坦尼克号上旅客的数据集
·
1、导入数据库
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import urllib.request
import os
%matplotlib inline
print("Tensorflow版本是:",tf.__version__)
2、下载泰坦尼克号上旅客的数据集
下载旅客数据集
data_url="http://biostat.mc.vanderbilt.edu/wili/pub/Main/DataSets/titanic3.xls"
data_file_path="E:/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded;',result)
else:
print(data_file_path,'data file already eists.')

3、使用Pandas读取处理数据
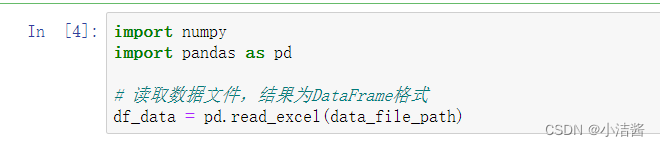
import numpy
import pandas as pd
# 读取数据文件,结果为DataFrame格式
df_data = pd.read_excel(data_file_path)
4、筛选提取字段
survival(是否生存)是标签字段,其他是候选特征字段
筛选提取需要的特征字段,去掉ticket,cabin等
# 筛选提取字段
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
selected_df_data=df_data[selected_cols]
注意:

5、找出有null值的字段
Pandas判断缺失值一般采用 isnull(),生成所有数据的True/False矩阵,这是元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True, 否则就是False
判断哪些”列”存在缺失值
列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
# 找出存在缺失值的"列"
selected_df_data.isnull().any()
selected_df_data.isnull().sum()
selected_df_data[selected_df_data.isnull().values==True]

6、填充null值
# 为缺失age记录填充值 设置为平均值
age_mean_value= selected_df_data['age'].mean()
selected_df_data['age'] = selected_df_data['age'].fillna(age_mean_value)
# 为缺失fare记录填充值
fare_mean_value=selected_df_data['fare'].mean()
selected_df_data['fare'] = selected_df_data['fare'].fillna(fare_mean_value)
# 为缺失embarked记录填充值
selected_df_data['embarked']=selected_df_data['embarked'].fillna('S')
7、转换编码
# 性别sex由字符串转换为数字编码
selected_df_data['sex'] = selected_df_data['sex'].map({'female':0,'male':1}).astype(int)
# 港口embarked由字母表示转换为数字编码
selected_df_data['embarked'] = selected_df_data['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)
8、删除name字段
drop不改变原有的df中的数据,而是返回另一个DataFrame来存放删除后的数据
axis = 1 表示删除列
# 删除name字段
selected_df_data = selected_df_data.drop(['name'],axis=1) # axis=1表示删除列
# 显示前3行数据
selected_df_data[:3]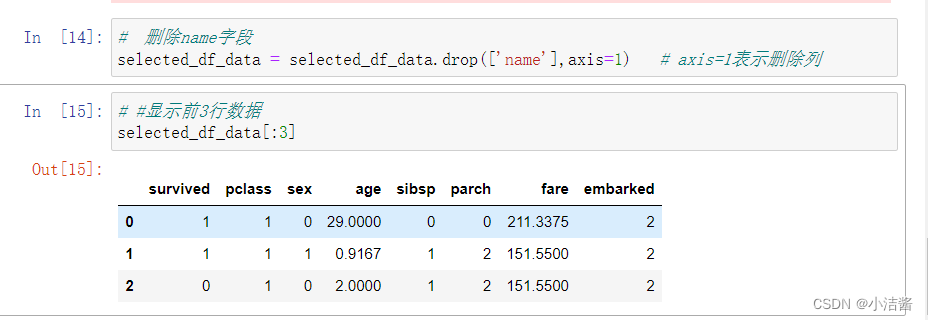
9、分离特征值和标签值
# 转换为ndarray数组
ndarray_data = selected_df_data.values
# 后7列是特征值
features = ndarray_data[:,1:]
# 第0列是标签值
label = ndarray_data[:,0]
features[:3]
label[:3]
10、特征值标准化处理
from sklearn import preprocessing
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features = minmax_scale.fit_transform(features)
norm_features[:3]
11、定义数据预处理函数
把前面数据预处理的命令全部封装到prepare_data函数中,方便后面调用
# 定义数据预处理函数
from sklearn import preprocessing
def prepare_data(df_data):
df = df_data.drop(['name'],axis=1) # 删除姓名列
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean) # 为缺失age记录填充值
fare_mean = df['fare'].mean()
df['fare'] = df['fare'].fillna(fare_mean) # 为缺失fare记录填充值
df['sex'] = df['sex'].map({'female':0,'male':1}).astype(int) # 把sex值由字符串转换为数值
df['embarked'] = df['embarked'].fillna('S') # 为缺失embarked记录填充值
df['embarked'] = df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int) # 把embarked值由字符串转换为数值
ndarray_data = df.values # 转换为ndarray数组
features = ndarray_data[:,1:] # 后7列是特征值
label = ndarray_data[:,0] # 第0列是标签值
# 特征值标准化
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features = minmax_scale.fit_transform(features)
return norm_features,label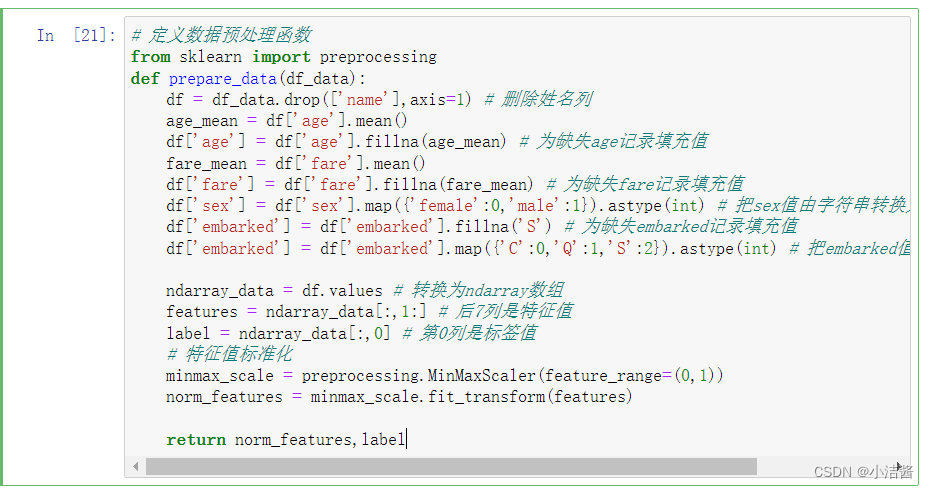

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)