Python爬虫-使用Jupyter爬虫
Python 使用Jupyter工具爬取环境配置:Window10、Python3.8、Jupyter
Python 使用Jupyter爬取练习网站-仅供学习参考
爬取简介
选择广州二手房作为爬取对象,链接地址为某家网房源,作为期末作业写的,也作为第一篇在CSDN发布的文章。同时通过爬取时的问题总结,供大家参考。
一、环境配置
- Windows 10
- Python 3.8
- Jupyter notebook
二、网页分析
首先进入网站查看网页URL,找到其中的共同点,方便后面爬取多页信息。
可以发现爬取网页的顺序
第一页为:
https://gz.lianjia.com/ershoufang/
第二页为:
https://gz.lianjia.com/ershoufang/pg2/
不难发现,通过构造最后面的pg[i]的参数可以爬取每页信息,虽然显示了7万8千多套房源,不过这样只能爬取前100页信息,总共也就3000条房源信息。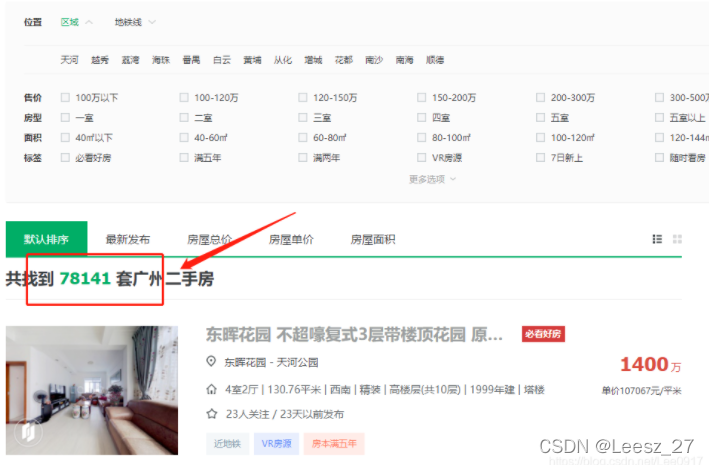
后来发现可以通过先爬取小区网址url,再通过小区爬取房源信息,可以爬取到更多的房源信息。点击小区只会显示30个小区,需要自己点击返回全部小区列表。
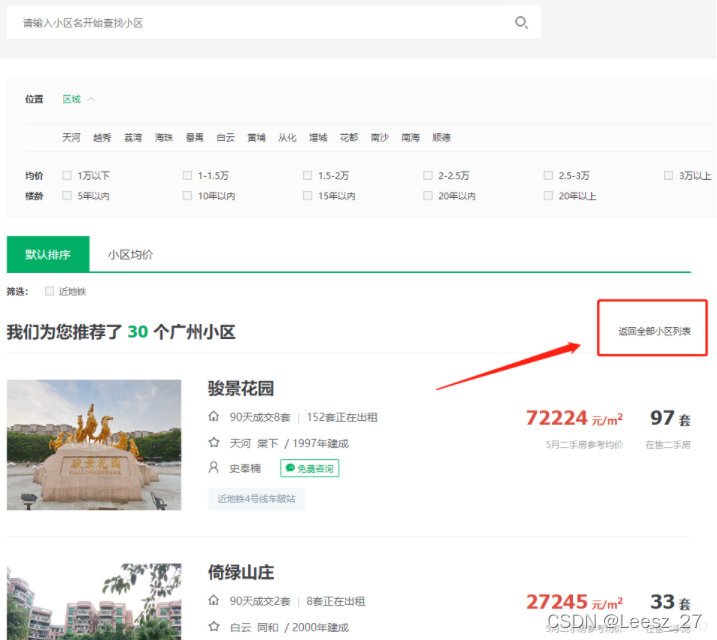
进去小区列表后的URL
可以看到首页为:
https://gz.lianjia.com/xiaoqu/?from=rec
第二页为:
https://gz.lianjia.com/xiaoqu/pg2/?from=rec
以此类推,可以看出格式为:
变量i为页码
https://gz.lianjia.com/xiaoqu/pg[i]/?from=rec
可以看出小区页爬取只能到第30页,但我们通过构造URL实测可以可以爬取100页,通过控制变量i即可。

三、网页爬取步骤
通过上述的了解,现在可以进入到爬取阶段了。首先需要爬取小区有多少套在售二手房,及该小区二手房的URL。实测可以通过点击套数来进去下一级页面,就可以看到小区的在售二手房源。


爬取方式,通过 右键【‘检查’】 该数字,可以查看到跳转页面的a标签下的href,然后通过爬取该标签下的信息来获取网址和套数。
这里有个问题,在我使用soup = BeatuifulSoup(data, “html.parser”),"html.parser"在爬取数据时会报错,换成”html5lib”就不会产生问题,可以正常爬取,不太清楚原理,希望看到帖子的大佬能帮忙解答一下。
爬取小区URL代码如下:
garden_id_list = [] #小区网址id列表
garden_num_list = [] #小区房源套数列表
ex_list = [] #存储丢失页编号
#爬取链家网小区,通过小区爬取房源
def xiaoqu(x):
try:
for a in range(x, 101):
url_xiaoqu = "https://gz.lianjia.com/xiaoqu/pg" + str(a) + "/?from=rec"
response = requests.get(url_xiaoqu, headers = headers)
data = response.text
soup = BeautifulSoup(data, "html5lib")
for i in range(1, 31):
#获取小区房源详情页url,并爬取共有多少套在售二手房
garden = soup.select('body > div.content > div.leftContent > ul > li:nth-child(' + str(i) + ') > div.xiaoquListItemRight > div.xiaoquListItemSellCount > a')
garden_id = garden[0]['href'].replace('https://gz.lianjia.com/ershoufang/','')
#将网址存进列表
garden_id_list.append(garden_id)
# print(garden)
#将搜索到的小区在售房源套数保存列表
garden_num = garden[0].get_text().replace('套', '').strip()
garden_num_list.append(garden_num)
# print(garden_num)
print('第'+str(a)+'页爬取成功!')
except Exception as e:
print('第' +str(a)+ '页获取失败!正在重启服务获取中!')
ex_list.append(a)
time.sleep(3)
return xiaoqu(a+1)
#重构一个def获取丢失页面
def ex_xiaoqu(x,m):
try:
url_xiaoqu = "https://gz.lianjia.com/xiaoqu/pg" + str(x) + "/?from=rec"
response = requests.get(url_xiaoqu, headers = headers)
data = response.text
soup = BeautifulSoup(data, "html5lib")
print('正在重新爬取第'+str(x)+'页,请耐心等待!')
#重构可能爬不到30条信息,构造一个m=31尝试爬取,如果失败,则m-1,尝试爬取该页面所能爬取小区最大值。后续通过duplicates()函数去重。
for i in range(1, m):
#获取小区房源详情页url,并爬取共有多少套在售二手房
garden = soup.select('body > div.content > div.leftContent > ul > li:nth-child(' + str(i) + ') > div.xiaoquListItemRight > div.xiaoquListItemSellCount > a')
garden_id = garden[0]['href'].replace('https://gz.lianjia.com/ershoufang/','')
#将网址最后的id存进列表
garden_id_list.append(garden_id)
# print(garden_id)
#将搜索到的小区在售房源套数保存列表
garden_num = garden[0].get_text().replace('套', '').strip()
garden_num_list.append(garden_num)
# print(garden_num)
print('第'+str(x)+'页爬取成功!共爬取该页信息'+str(m-1)+'条!')
#爬取到该页面后,删除该编号,防止重复输出。
ex_list.remove(x)
print('剩余未重新爬取列:', ex_list)
return re_xq()
except Exception as e:
print('第' +str(x)+ '页重新获取失败!正在重启服务获取中!')
time.sleep(3)
m -= 1
return ex_xiaoqu(x, m)
#构造一个存储丢失页的列表重爬。
def re_xq():
if len(ex_list) != 0:
for z in ex_list:
ex_xiaoqu(z, 31)
else:
print('全部数据爬取完毕!')
xiaoqu(1)
re_xq()

将爬取的网页和数量转为DataFrame去重后并保存到csv中。
#将爬取到的信息转换为字典,并用DataFrame输出
dict_garden = {'id':garden_id_list,'num':garden_num_list}
d_garden = DataFrame(dict_garden)
d_garden

#删除重复列并重新查看信息
d_garden = d_garden.drop_duplicates()
d_garden.info()
#将小区网址信息保存到csv中
import csv
d_garden.to_csv('小区网址.csv')

四、通过小区URL爬取房源信息
通过导入写入的广州二手房数据,去除没有在售二手房源的小区,然后对小区的房源信息进行爬取,获取楼盘名,楼盘地址,楼盘信息,楼盘总价,楼盘单价和区域。编写的程序进过好几轮修改,总算是达到一个还不错的效果,还算顽强,期间对代码进行了算法优化,勉勉强强爬取了6个小时才爬取到所有的数据。
比较有趣的部分在于区域爬取的优化及小区套数的算法编写,一页只能爬取30条信息,每个小区套数不同,所以需要编写小区套数的算法,以防程序报错,期间还发现比较有趣的现象,因为小区和房源是分开爬取的,期间间隔了一两天,有的房子被卖出了,所以编写程序的时候需要多一个循环,如果爬取的数据列表溢出,则减少一套房重新爬取。
希望大佬看到可以改进的地方可以教一下如何进一步优化算法及改进代码模块,增强爬取的稳定性及速度。
# 导入写入的广州二手房数据
df = pd.read_csv(r'./小区网址.csv')
#查看小区网址中没有二手房源的网址,并剔除
df = df[df['num'] > 0]
df
#删除多余列
df = df.drop('Unnamed: 0', axis = 1)
df

HouseName_list = [] #楼盘名列表
address_list = [] #楼盘地址列表
houseInfo_lise = [] #楼盘详细信息列表
totalPrice_list = [] #楼盘总价格列表
unitPrice_list = [] #楼盘单价(元/平方米)列表
region_list = [] #楼盘区域(区)
# 获取区域,一个小区一个区域即可,可以减少重复爬取次数
def region_xq(x):
url = 'https://gz.lianjia.com/ershoufang/pg1' + df['id'][x]
response = requests.get(url, headers = headers)
data = response.text
soup = BeautifulSoup(data, "html5lib")
#获取区域
#需要先进入详情页
region_web = soup.select('#content > div.leftContent > ul > li:nth-child(1) > div.info.clear > div.title > a')
#爬取详情页网页的<a href>
region_web = region_web[0]['href']
#创建一个url加载网页
region_url = region_web
res = requests.get(region_url, headers = headers)
region_data = res.text
region_soup = BeautifulSoup(region_data, "html5lib")
#爬取房源区域
region = region_soup.select('body > div.overview > div.content > div.aroundInfo > div.areaName > span.info > a:nth-child(1)')
region = region[0].get_text()
# region_list.append(region)
# print(region)
return region
#通过爬取每个id获取该小区房源
def house(x):
try:
for z in range(x, len(df)):
#如果数量大于每页所取的30个房源信息,需要查询需要多少页,最后一页有多少信息。
if df['num'][z] > 30:
if df['num'][z] % 30 == 0:
page = df['num'][z] // 30
else:
page = df['num'][z] // 30 + 1
else:
page = 1
print('第'+str(z+1)+'个小区!需要爬取信息'+str(df['num'][z])+'条!')
#每个小区对应一个区域,所以可以提取出来,避免重复爬取。
url = 'https://gz.lianjia.com/ershoufang/pg1' + df['id'][x]
response = requests.get(url, headers = headers)
data = response.text
soup = BeautifulSoup(data, "html5lib")
#获取区域
#需要先进入详情页
region_web = soup.select('#content > div.leftContent > ul > li:nth-child(1) > div.info.clear > div.title > a')
#爬取详情页网页的<a href>
region_web = region_web[0]['href']
#创建一个url加载网页
region_url = region_web
res = requests.get(region_url, headers = headers)
region_data = res.text
region_soup = BeautifulSoup(region_data, "html5lib")
#爬取房源区域
region = region_soup.select('body > div.overview > div.content > div.aroundInfo > div.areaName > span.info > a:nth-child(1)')
region = region[0].get_text()
# region_list.append(region)
# print(region)
for q in range(0, page):
url = 'https://gz.lianjia.com/ershoufang/pg' + str(q+1) + df['id'][z]
response = requests.get(url, headers = headers)
data = response.text
soup = BeautifulSoup(data, "html5lib")
if df['num'][z] > 30:
if df['num'][z] % 30 == 0:
last_page_num = 30
else:
page_num = page - (q+1)
if page_num == 0:
last_page_num = df['num'][z] % 30
else:
last_page_num = 30
else:
last_page_num = df['num'][z]
# print('第'+str(q+1)+'页!需要爬取信息'+str(last_page_num)+'条!')
for i in range(0, last_page_num):
#获取楼盘名信息
HouseName = soup.select("#content > div.leftContent > ul > li:nth-child(" + str(i+1) + ") > div.info.clear > div.flood > div")
HouseName = HouseName[0].get_text().replace(" ","").split('-')[0]
HouseName_list.append(HouseName)
# print(HouseName)
#获取楼盘地址
address = soup.select("#content > div.leftContent > ul > li:nth-child(" + str(i+1) + ") > div.info.clear > div.flood > div")
address = address[0].get_text().replace(" ","").split('-')[1]
address_list.append(address)
# print(address)
#获取楼盘具体信息
houseInfo = soup.select("#content > div.leftContent > ul > li:nth-child(" + str(i+1) + ") > div.info.clear > div.address > div")
houseInfo = houseInfo[0].get_text()
houseInfo_lise.append(houseInfo)
# print(houseInfo)
#获取楼盘总价格
totalPrice = soup.select('#content > div.leftContent > ul > li:nth-child(' + str(i+1) +') > div.info.clear > div.priceInfo > div.totalPrice')
totalPrice = totalPrice[0].get_text().replace('万','')
totalPrice_list.append(totalPrice)
# print(totalPrice)
#获取楼盘单价(元/平方米)
unitPrice = soup.select('#content > div.leftContent > ul > li:nth-child(' + str(i+1) + ') > div.info.clear > div.priceInfo > div.unitPrice > span')
unitPrice = unitPrice[0].get_text().replace('单价','').replace('元/平米','')
unitPrice_list.append(unitPrice)
# print(unitPrice)
#获取区域
region_list.append(region)
# print(region)
print('第'+str(z+1)+'个爬取完成!爬取信息'+str(df['num'][z])+'条!')
except Exception as e:
#本来可以不用try的,但是调试中发现爬一半的时候有的房子被卖了。。造成错误。
#房源数量未更新,手动减一
df.loc[z, 'num'] = df['num'][z] - 1
print('小区房源有更新,需要重新爬取,正在重新爬取中...')
if df['num'][z] == 0:
print('网址被抓,已保存到第'+str(z)+'页!请更新页码重新爬取!')
else:
return house(z)
# print(e)

共爬取了6w多条数据,对数据进行去重转换后保存进csv。
#将爬取到的信息转换为字典,并用DataFrame输出
from pandas import DataFrame
dict_house = {'HouseName':HouseName_list,'Address':address_list,'houseInfo':houseInfo_lise,'totalPrice':totalPrice_list,'unitPrice':unitPrice_list,'region':region_list}
d_house = DataFrame(dict_house)
d_house
#删除重复列并重新查看信息
d_house = d_house.drop_duplicates()
d_house.info()
#将房源信息保存到csv中
import csv
d_house.to_csv('广州二手房源信息.csv')

以上就是对于广州某家二手房的爬取操作。对于对数据处理过两天有空再继续编写,希望对需要学习这方面的朋友有所帮助。爬取时间为6月13日。希望大佬们看到可以帮忙看看哪里的不足和需要优化的点。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 15
15 2
2- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)