jupyter notebook 中使用pandas统计分析基础
一:pandas是基于numpy的数据分析模块,它提供了大量标准数据模型和高效操作大型数据集所需要的工具。可以说pandas时使用pyhton能够成为高效且强大的数据分析环境的重要因素之一。导入的方式:import pandas as pdpandas 有三种数据结构:series,dataframe 和panel series类似与数组,dataframe类似与表格,panel类似excel的多
·
一:
pandas是基于numpy的数据分析模块,它提供了大量标准数据模型和高效操作大型数据集所需要的工具。可以说pandas时使用pyhton能够成为高效且强大的数据分析环境的重要因素之一。
导入的方式:
import pandas as pd
pandas 有三种数据结构:series,dataframe 和panel series类似与数组,dataframe类似与表格,panel类似excel的多表单sheet
以下内容主要是对一个文件的一个数据分析:以下数据可以自己创造一个,此处数据不完整,只截图了一部分,

二:
#导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline#获取数据
fdata = pd.read_excel('F:/anaconda/data/tips.xls')
fdata.head()
#查看数据的描述信息
fdata.describe() 
#修改列名为汉字,并显示前5行数据
fdata.rename(columns={'total_bill':'消费总额','tip':'小费','sex':'性别','smoker':'是否吸烟','day':'星期','time':'聚餐时间段','size':'人数'},inplace = True)
fdata.head()
#人均消费:
fdata['人均消费'] = round(fdata['消费总额']/fdata['人数'],2)
fdata.head()
#查询吸烟男性中人均消费大于15 的数据
#方法一:
fdata[(fdata['是否吸烟']=='Yes')&(fdata['性别']=='Male')&(fdata['人均消费']>15)]
#方法二:
fdata[(fdata.是否吸烟=='Yes')&(fdata.性别=='Male')&(fdata.人均消费>15)]
#方法三:
fdata.query('是否吸烟=="Yes"&性别=="Male"&人均消费>15') 
#分析小费金额和消费总额的关系
fdata.plot(kind='scatter',x='消费总额',y='小费') 
#分析男性顾客和女性顾客谁更慷慨
fdata.groupby('性别')['小费'].mean() 
#分析星期和小费之间的关系
print(fdata['星期'].unique()) #显示星期的取值
r = fdata.groupby('星期')['小费'].mean()
fig = r.plot(kind='bar',x='星期',y='小费',fontsize = 12,rot = 30)
fig.axes.title.set_size(16) 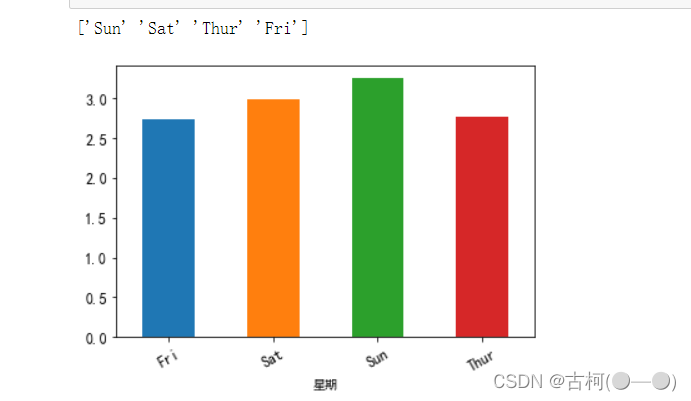
#性别+吸烟的组合因素对慷慨的影响
r = fdata.groupby(['性别','是否吸烟'])['小费'].mean()
fig = r.plot(kind='bar',x=['性别','是否吸烟'],y='小费',fontsize = 12,rot = 30)
fig.axes.title.set_size(16) 
#分析聚餐时间段与小费数额的关系
r = fdata.groupby(['聚餐时间段'])['小费'].mean()
fig = r.plot(kind='bar',x='聚餐时间段',y='小费',fontsize = 15,rot = 30)
fig.axes.title.set_size(16) 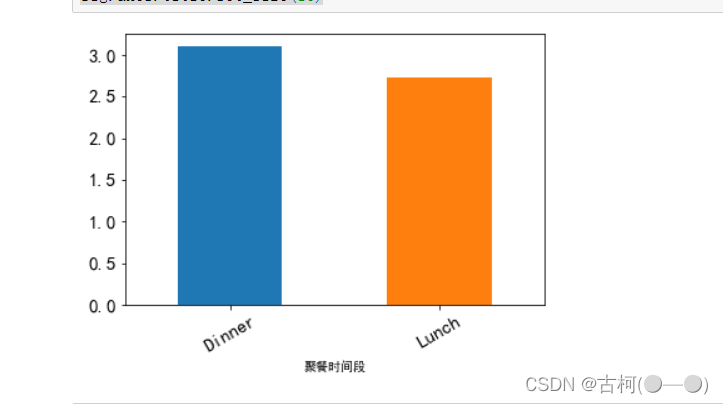

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)