【时间序列】时序分析之移动平均-python实战
今天给大家讲解一下移动平均,其在时间序列分析中具有重要的作用。1 简介移动平均(moving average)主要应用于时间序列的分析,其能够去除不同时间步长的序列间的微小差异。移动平...
今天给大家讲解一下移动平均,其在时间序列分析中具有重要的作用。
1 简介
移动平均(moving average)主要应用于时间序列的分析,其能够去除不同时间步长的序列间的微小差异。
移动平均的目的是去除噪声。
移动平均需要指定一个窗口大小(window size),称为窗口宽度(window width)。这定义了用于计算移动平均值的原始观测值的数量。
移动是指由窗宽定义的窗口沿时间序列滑动,计算新序列的平均值。
移动平均主要有两种形式:居中和截尾移动平均(Centered and Trailing Moving Average)。
居中移动平均
t 时刻的值计算由原始观测值在 t 时刻、之前和之后的平均值。
假设窗口为3,则:
center_ma(t) = mean(obs(t-1),obs(t),obs(t+1))
这个方法需要用到未来值。可以作为一种从时间序列中去除趋势和季节成分的通用方法,而在预测时通常不能使用这种方法。
截尾移动平均
t 时刻的值计算由原始观测值在 t 时刻以及之前的平均值。
假设窗口为3,则:
trail_ma(t) = mean(obs(t-2),obs(t-1),obs(t))
这个方法只用到历史数据,并可以用于时间序列预测。
本文主要侧重于截尾移动平均。
在应用移动平均时,需要对数据提出一些假设。假设趋势和季节成分已经从时序中去除。意味着数据是平稳的(stationary)或者未显示出明显的趋势(长期增长或下降)和季节性(一致的周期性结构)。
在时序数据预测时,有很多方法可以去除趋势和季节性,主要有差分法(differencing method)和建立行为模型,并显式地从序列中减去它。
接下来从三个面讲解截尾平均移动的应用。
2 移动平均的应用
2.1 数据准备
数据集是总共有365条记录,数据记录的是1959年加州每日出生的女婴数量。
链接:https://pan.baidu.com/s/1SpDi0oT-6jqKmAT4JwC0TA
提取码:6ylx
数据:daily-total-female-births.csv
代码:moving_average.py
显示数据的前5条记录:
Date,Births
1959/1/1,35
1959/1/2,32
1959/1/3,30
1959/1/4,31
1959/1/5,44
移动平均可以作为一种数据准备技术来创建原始数据集的平滑版本。
平滑(smoothing)是一种有用的数据准备技术,因为它可以减少观测中的随机变化。
pandas 中的 rolling() 函数可以自动根据窗口大小对观测数据进行移动平均。
假设窗口大小为3,则 t 时刻的转换值等于前三个观测值(t-2,t-1,t)的均值。
trans_obs(t) = 1/3 * ( obs(t-2) + obs(t-1) + obs(t) )
现在开始正式分析:
# 引入相关的包
import pandas as pd # 表格和数据操作
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import mean_squared_error
# -------------------------------------------------------------------------------------
# 读入数据
birth = pd.read_csv(r'./test/daily-total-female-births.csv', index_col=['Date'], parse_dates=['Date'])
birth.info()
birth.head()
plt.figure(figsize=(15, 7))
plt.plot(birth)
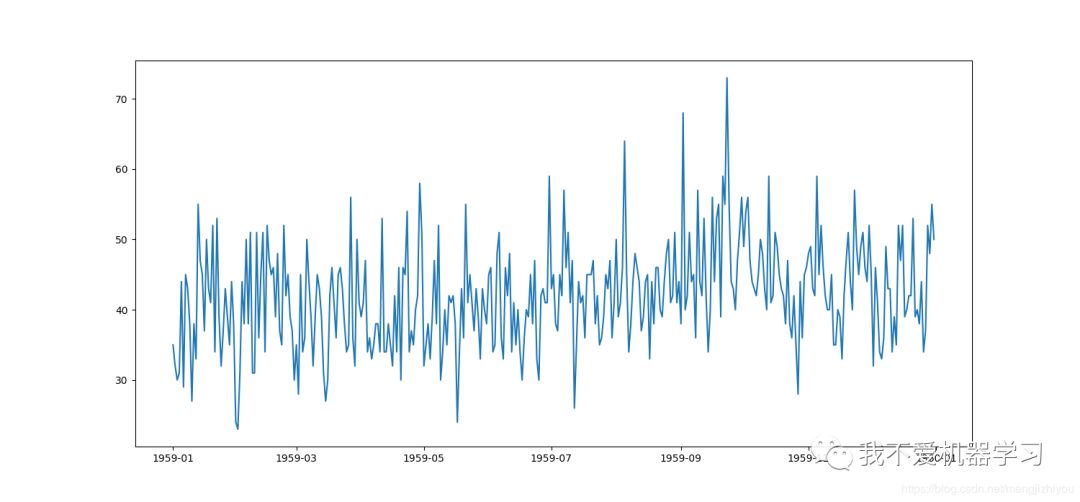
从上图可以看出,这个数据集是研究移动平均方法的一个很好的例子,因为它没有显示任何明显的趋势或季节性。
下面是在窗口大小为3 的情况下的移动平均值。
window = 3
# trail-rolling average transform
rolling = birth.rolling(window=window)
rolling_mean = rolling.mean()
plt.figure(figsize=(15, 7))
plt.plot(birth)
plt.plot(rolling_mean, 'r')
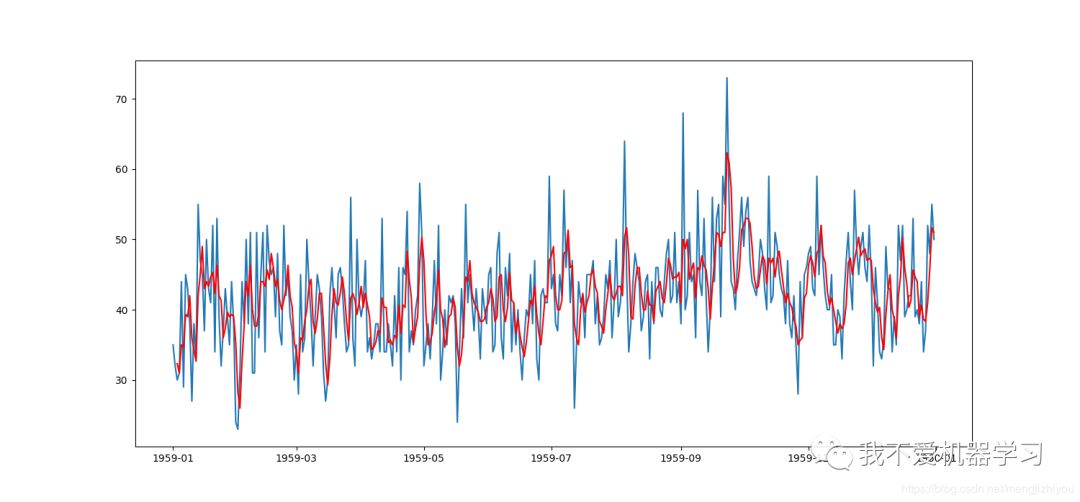
从图中可以看出,原始观测值(蓝色)被移动平均转换值(红色)覆盖。
rolling_mean.head()
Births
Date
1959-01-01 NaN
1959-01-02 NaN
1959-01-03 32.333333
1959-01-04 31.000000
1959-01-05 35.000000
移动平均值的前两个观测值是 NaN,因为前两个观测值的时间点在移动时缺少前面时刻的数据。这两个转换值需被删除。
2.2 特征工程
当建立时序预测模型可以被看做为监督学习问题时,移动平均可以作为新信息的来源。
在本例中移动平均计算得到的值可以作为一个新的特征。
lag1 = birth.shift(1)
lag3 = birth.shift(3)
lag3_mean = lag3.rolling(window=window).mean()
df = pd.concat([lag3_mean, lag1, lag3], axis=1)
df.columns = ['lag3_mean', 't-1', 't-3']
df.head()
这里的 df 相当于是特征,本例中有三个特征,当把时序预测模型看做是监督问题时,此时的 Y 就是原始观测值 (Births):
lag3_mean t-1 t-3 Births
Date
1959-01-01 NaN NaN NaN 35
1959-01-02 NaN 35.0 NaN 32
1959-01-03 NaN 32.0 NaN 30
1959-01-04 NaN 30.0 35.0 31
1959-01-05 NaN 31.0 32.0 44
1959-01-06 32.333333 44.0 30.0 29
在建模时,将有NaN的行删除后再建模。
2.3 预测
移动平均值可以直接看做是预测值。
这是一个最基础的模型,其假设时间序列的趋势和季节性成分已经被删除或调整。
移动平均作为预测模型是直接向前走的形式,当有新的观测值,则这个模型会更新并预测。
# prepare situation
X = birth.values
history = [X[i] for i in range(window)]
test = [X[i] for i in range(window, len(X))]
predictions = []
# walk forward over time steps in test
for t in range(len(test)):
length = len(history)
yhat = np.mean([history[i] for i in range(length - window, length)])
predictions.append(yhat)
history.append(test[t])
print('predicted=%f, excepted=%f' % (yhat, test[t]))
error = mean_squared_error(test, predictions)
print('Test MSE: %3f' % error)
plt.figure(figsize=(15, 7))
plt.plot(test)
plt.plot(predictions, 'r')
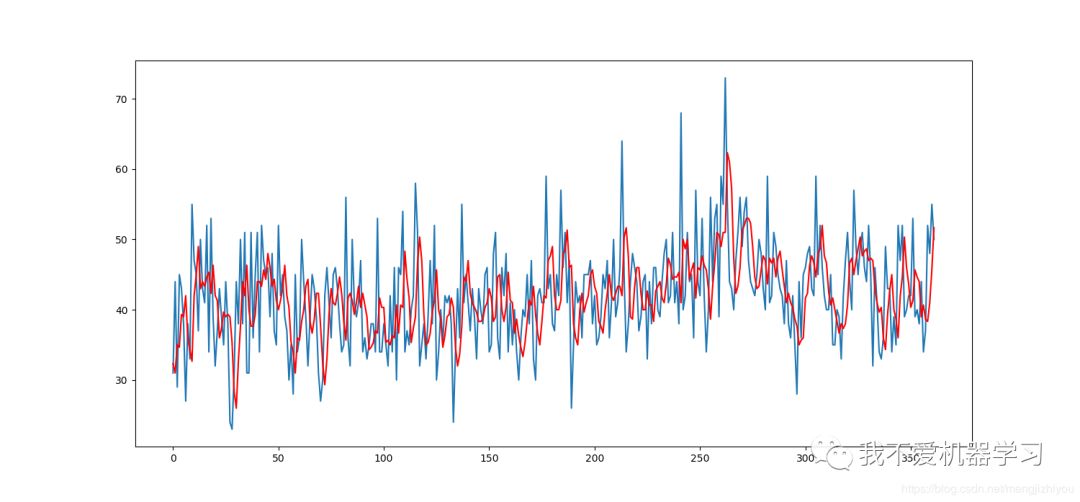
以上就是移动平均的相关知识,希望对你有用。
建议阅读:
【时空序列预测第一篇】什么是时空序列问题?这类问题主要应用了哪些模型?主要应用在哪些领域?
【AI蜗牛车出品】手把手AI项目、时空序列、时间序列、白话机器学习、pytorch修炼
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
个人微信
备注:昵称+学校/公司+方向
如果没有备注不拉群!
拉你进AI蜗牛车交流群

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)