pandas库
pandas库pandas是Python的一个非常强大的数据分析库,提供了高性能易用的数据类型,以及大量能使我们能使我们快速便捷地处理数据地函数和方法。pandas地核心数据结构有两种,即一维数组地Series对象和二维表格型地DataFrame对象,数据分析相关地所有事务都是围绕这两种对象进行的。安装pandaspip install -i https://pypi.tuna.tsinghua.
pandas库
pandas是Python的一个非常强大的数据分析库,提供了高性能易用的数据类型,以及大量能使我们能使我们快速便捷地处理数据地函数和方法。pandas地核心数据结构有两种,即一维数组地Series对象和二维表格型地DataFrame对象,数据分析相关地所有事务都是围绕这两种对象进行的。
安装pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
Series对象
Series对象的创建
Series对象是一维数组结构,与NumPy中的一维数组ndarray类似,二者与Python基本的数据结构list也很相近,其区别是list中的元素可以是不同的数据类型,而一维数组ndarray和Series中则只允许存储同一数据类型的数据。
Series对象的内部结构由两个相互关联的数组组成,一个是数据数组values,用来存放数据,数组values中的每个数据都有一个与之关联的索引(标签),这些索引存储在另外一个叫做index的索引数组中。
创建一个Series对象的最基本语法格式如下
pandas.Series(data=None,index=None,dtype=None,name=None)
返回值:返回一个Series对象
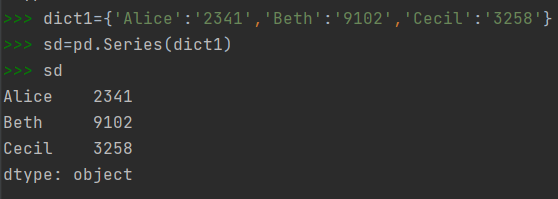
data:可以是一个Python列表,index与列表元素个数一致;也可以是字典,将键值对中的"值"作为Series对象的数据,将"键"作为索引;也可是一个标量值,这种情况下必须设置索引,标量值会重复来匹配索引的长度。
index:为Series对象的每个数据指定索引
dtype:为Series对象的数据指定数据类型
name:为Series对象起个名字
1)用一维ndarray数组创建Series对象

2)用标量值创建Series对象
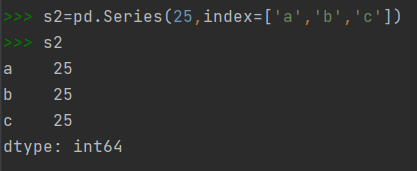
3)用字典创建Series对象
键值对中的"键"是用来作为Series对象的索引,键值对中的"值"作为Series对象的数据。
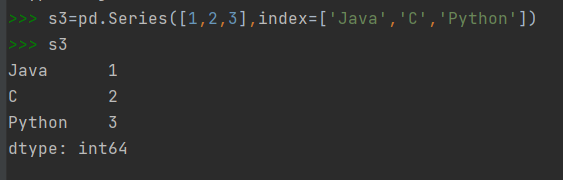
4)用列表创建Series对象
Series对象的属性
1)shape属性获取Series对象的形状。
2)dtype属性获取Series对象的数据数组中的数据的数据类型
3)values属性获取Series对象的数据数组
4)index属性获取Series对象的数据数组的索引
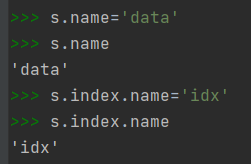
5)Series对象本身及索引的name属性
Series对象的数据的查看和修改
1)通过索引和切片查看Series对象的数据
可以使用数据索引以"Series对象[id]"方式访问Series对象的数据数组中索引为id的数据,也可通过默认索引来读取,也可以通过截取(切片)的方式读取多个元素。

Series对象的数据的查看和修改
使用多个数据对应的索引来一次读取多个元素,注意索引要放在一个列表中。
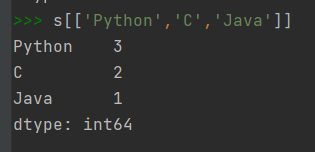
根据筛选条件读取数据
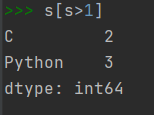
Series对象的基本运算
算术运算与函数运算
1)算数运算
适用于NumPy数组的运算符(+,-,*,/)或其他数学函数,也适用于Series对象。可以将Series对象的数据数组与标量进行+,-,*,/,等算数运算
2)函数运算

Series对象之间的运算
Series对象之间也可进行四则运算,不同Series对象运算的时候,能够通过识别索引进行匹配计算,即只有索引相同的元素才会进行相应的运算操作。

DataFrame对象
DataFrame对象创建
DataFrame是一个表格型的数据结构,既有行索引(保存在index)又有列索引(保存在columns),是Series对象从一维到多维的扩展。DataFrame对象每列相同位置处的元素共用一个行索引,每行相同位置处的元素共用一个列索引。DataFrame对象各列的数据类型可以不相同。
创建DataFrame对象最常用的方法是使用pandas的DataFrame()构造函数,其语法格式如下:
DataFrame(data=None, index=None, columns=None, dtype=None)
返回值:DataFrame对象
参数说明: data:创建DataFrame对象的数据,其类型可以是字典、嵌套列表、元组列表、numpy的ndarray对象、其它DataFrame对象。
index:行索引,创建DataFrame对象的数据时,如果没有提供索引,默认赋值为arange(n)。
columns:列索引,没有提供索引时,默认赋值为arange(n)。
dtype:用来指定元素的数据类型,如果为空,自动推断类型。
1)可将一个字典对象传递给DataFrame()函数来生成一个DataFrame对象,字典的键作为DataFrame对象的列索引,字典的值作为列索引对应的列值,pandas也会自动为其添加一列从0开始的数值作为行索引。

2)可以只选择字典对象的一部分数据来创建DataFrame对象,只需在DataFrame构造函数中,用columns选项指定需要的列即可,新建的DataFrame对象各列顺序与指定的列顺序一致。
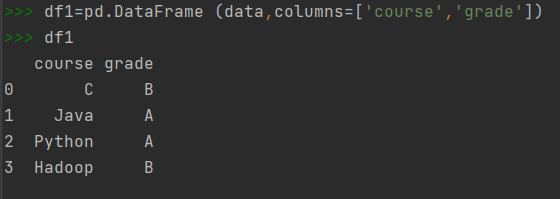
3)创建DataFrame对象时,如果没有用index数组明确指定行索引,pandas也会自动为其添加一列从0开始的数值作为行索引。如果想用自己定义的行索引,则要把定义的索引放到一个数组中,赋值给index选项。
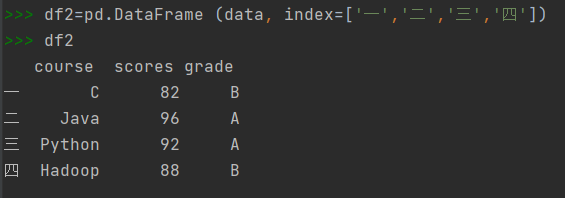
4)创建DataFrame对象时,可以同时指定行索引和列索引,这时候就需要传递三个参数给DataFrame()构造函数,三个参数的顺序是:数据、index选项和columns选项。将存放索引的数值赋给index选项将存放索引的数值赋给columns选项

5)以字典的字典或Series的字典的结构创建DataFrame对象,pandas会将外边的键解释成列名称,将里面的键解释成行索引。

6)用键值为列表的字典构建DataFrame,其中每个列表(list)代表的是一个列,字典的名字则是列索引。这里要注意的是每个列表中的元素数量应该相同,否则会报错。

7)以字典的列表构建DataFrame,其中每个字典代表的是每条记录(DataFrame中的一行),字典中各个键的键值对应的是这条记录的相关属性。

DataFrame对象的属性

查看和修改DataFrame对象的元素
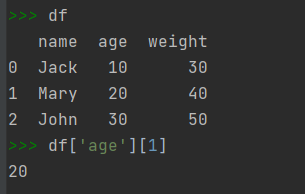
1)查看DataFrame对象中的元素要想获取存储在DataFrame对象中的一个元素,需要依次指定元素所在的列名称、行名称(索引)。
可以通过指定条件筛选DataFrame对象的元素
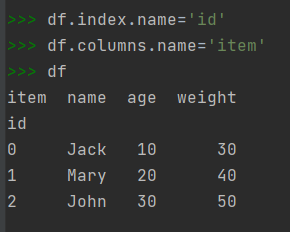
2)修改DataFrame对象中的元素可以用DataFrame对象的name属性为DataFrame对象的列索引columns和行索引index指定别的名称,以便于识别
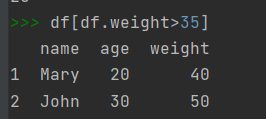
判断元素是否属于DataFrame对象
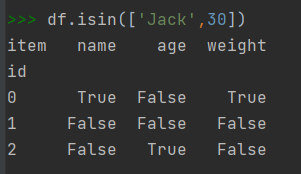
可通过DataFrame对象的方法isin()判断一组元素是否属于DataFrame对象。
DataFrame对象的基本运算
数据筛选

数据预处理
预处理方法非常多,略
具体使用可以查看官网
数据运算与排序
具体使用可以查看官网
数学统计
具体使用可以查看官网
数据分组与聚合
分组
对数据集进行分组并对各分组应用函数是数据分析中的重要环节。在pandas中,分组运算主要通过groupby函数来完成,聚合操作主要通过agg函数来完成。
groupby对数据进行数据分组运算的过程分为三个阶段:分组、用函数处理分组和分组结果合并。
(1)分组。按照键(key)或者分组变量将数据分组。分组键可以有多种形式,且类型不必相同:
1、列表或数组,其长度与待分组的轴一样。
2、DataFrame对象的某个列名。
3、字典或Series,给出待分组轴上的值与分组名之间的对应关系。
4、函数,用于处理轴索引或索引中的各个标签。
(2)用函数处理。对于每个分组应用我们指定的函数,这些函数可以是Python自带函数,可以是自定义的函数。
(3)合并分组处理结果。把每个分组的计算结果合并起来。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
作用:通过指定列索引或行索引,对df的数据元素进行分组。
by:用于指定分组的依据,其数据形式可以是映射、函数、索引以及索引列表。
axis:默认axis=0按行分组,可指定axis=1对列分组。
level:int值,默认为None,如果axis是一个MultiIndex(分层索引),则按特定的级别分组。
sort:排序。boolean值,默认True。
group_keys:当调用apply时,添加group_keys来索引来识别片断。 squeeze:尽可能减少返回类型的维度,否则返回一致的类型。

在df.groupby()所生成的分组上应用size()、sum()、count()、mean()等统计函数,能分别统计分组数量、不同列的分组和、不同列的分组数量、分组不同列的平均值。

聚合
对于聚合,一般指的是从数组产生标量值的数据转换过程,常见的聚合运算都有相关的统计函数快速实现,当然也可以自定义聚合运算。聚合操作主要通过agg函数来完成,agg函数的语法格式如下: DataFrame.agg(func, axis=0)
作用:通过func在指定的轴上进行聚合操作。
func:用来指定聚合操作的方式,其数据形式有函数、字符串、字典以及字符串或函数所构成的列表。
axis:axis=0表示在列上操作,axis=1表示在行上操作。

pandas数据可视化
DataFrame对象df通过调用它的plot()方法,可以快速地将df的数据绘制成各种类型的图,plot()方法的语法格式如下:
df.plot(x=None, y=None, kind='line', figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, alpha)
参数说明:
x:设置x轴标签或位置,默认情况下,plot会将行索引作为x轴标签。
y:设置y轴标签或位置,默认情况下,plot会将列索引作为y轴标签。
kind:所要绘制的图类型,kind=‘line’,绘制折线图;kind=‘bar’,绘制条形图;kind=‘barh’,绘制横向条形图;kind=‘hist’,绘制直方图(柱状图);kind=‘box’,绘制箱线图;kind=‘kde’,绘制Kernel的密度估计图,主要对柱状图添加Kernel概率密度线;kind=‘density’,绘制的图与kind='kde’的图相同;kind=‘area’,绘制区域图;kind=‘pie’,绘制饼图;kind=‘scatter’,绘制散点图。
figsize:图片尺寸大小。
use_index:默认用索引做x轴。
title:图片的标题。
grid:图片是否有网格。
legend:子图的图例。
style:对每列折线图设置线的类型。
xticks:设置x轴刻度值,序列形式(比如列表)。
yticks:设置y轴刻度,序列形式(比如列表)。
xlim:设置x坐标轴的范围,列表或元组形式。
ylim:设置y坐标轴的范围,列表或元组形式。
rot:设置轴标签(轴刻度)的显示旋转度数。
fontsize:设置轴刻度的字体大小。
alpha:设置图表填充的不透明(0-1)度。

pandas读写数据


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)