voc数据集格式转coco数据集格式
之前做的目标检测项目都是用的voc数据集格式,为了和其他算法做比较,也需要在coco数据集上进行测试。本文参考了https://blog.csdn.net/c2250645962/article/details/105408547/将voc数据集格式转换为coco数据集格式。1. voc数据集和coco数据集目录结构├── datasets│├── coco││├── annotations││├
之前做的目标检测项目都是用的voc数据集格式,为了和其他算法做比较,也需要在coco数据集上进行测试。本文参考了https://blog.csdn.net/c2250645962/article/details/105408547/
将voc数据集格式转换为coco数据集格式。
1. voc数据集和coco数据集目录结构
├── datasets
│ ├── coco
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
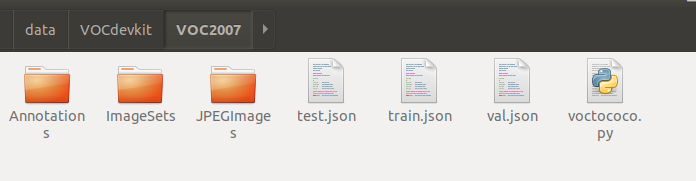
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ ├── VOC2012
coco目录内容如下

annotations目录下内容如下:

首先参考coco数据集目录结构建立文件夹
其中train2017、test2017、val2017文件夹中保存的是用于训练、测试、验证的图片,而annotations文件夹保存的是这些图片对应的标注信息,分别存在instance_train2017、instance_test2017、instance_val2017三个json文件中。
2. 划分训练集验证集,复制图片和标签
为了方便使用,分别将图片和标签复制到对应的images和labels文件夹,images文件夹中又分别有train和val文件夹,labels中也是一样。

代码如下
import xml.etree.ElementTree as ET
import os
from os import listdir,getcwd
from os.path import join
import shutil
sets=[('2012','train'),('2012','val'),('2007','train'),('2007','val'),('2007','test')3
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
list_file.close()
# 合并多个文本文件
def mergeTxt(file_list,outfile):
with open(outfile,'w') as wfd:
for f in file_list:
with open(f,'r') as fd:
shutil.copyfileobj(fd,wfd)
file_list=['2007_train.txt','2007_val.txt','2012_train.txt','2012_val.txt']
outfile='train.txt'
mergeTxt(file_list,outfile)
file_list=['2007_train.txt','2007_val.txt','2007_test.txt','2012_train.txt','2012_val.txt']
outfile='train.all.txt'
mergeTxt(file_list,outfile)
#创建VOC文件夹及子文件夹
wd=os.getcwd()
data_base_dir=os.path.join(wd,"VOC/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
img_dir=os.path.join(data_base_dir,"images/")
if not os.path.isdir(img_dir):
os.mkdir(img_dir)
img_train_dir=os.path.join(img_dir,"train/")
if not os.path.isdir(img_train_dir):
os.mkdir(img_train_dir)
img_val_dir=os.path.join(img_dir,"val/")
if not os.path.isdir(img_val_dir):
os.mkdir(img_val_dir)
label_dir=os.path.join(data_base_dir,"labels/")
if not os.path.isdir(label_dir):
os.mkdir(label_dir)
label_train_dir=os.path.join(label_dir,"train/")
if not os.path.isdir(label_train_dir):
os.mkdir(label_train_dir)
label_val_dir=os.path.join(label_dir,"val/")
if not os.path.isdir(label_val_dir):
os.mkdir(label_val_dir)
print(os.path.exists('train.txt'))
f=open('train.txt','r')
lines=f.readlines()
#使用train.txt中的图片作为训练集
for line in lines:
line=line.replace('\n','')
if(os.path.exists(line)):
shutil.copy(line,"VOC/images/train") #复制图片
print('coping train img file %s' %line +'\n')
line=line.replace('JPEGImages','Annotations') #复制label
line=line.replace('jpg','xml')
if(os.path.exists(line)):
shutil.copy(line,"VOC/labels/train")
print('copying train label file %s' %line +'\n')
# 使用2007_test.txt中的图片作为验证集
print(os.path.exists('2007_test.txt'))
f=open('2007_test.txt','r')
lines=f.readlines()
for line in lines:
line=line.replace('\n','')
if(os.path.exists(line)):
shutil.copy(line,"VOC/images/val") #复制图片
print('coping val img file %s' %line +'\n')
line=line.replace('JPEGImages','Annotations') #复制label
line=line.replace('jpg','xml')
if(os.path.exists(line)):
shutil.copy(line,"VOC/labels/val")
print('copying val img label %s' %line +'\n')
3.转换
json文件中每个字段的含义可以参考:
https://blog.csdn.net/c2250645962/article/details/105367693
上代码
#coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"info":['none'], "license":['none'], "images": [], "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = filename.split('.')[0][-3:]
# print('filename is {}'.format(image_id))
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id':image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print("[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert(xmax > xmin), "xmax <= xmin, {}".format(line)
assert(ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width*o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox':[xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories), all_categories.keys(), len(pre_define_categories), pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# xml标注文件夹
xml_dir_train = './labels/train'
xml_dir_val = './labels/val'
# 训练数据的josn文件
save_json_train = './train.json'
# 验证数据的josn文件
save_json_val = './val.json'
# 类别,如果是多个类别,往classes中添加类别名字即可,比如['dog', 'person', 'cat']
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
only_care_pre_define_categories = True
xml_list_train = glob.glob(xml_dir_train + "/*.xml")
xml_list_train = np.sort(xml_list_train)
xml_list_val = glob.glob(xml_dir_val + "/*.xml")
xml_list_val = np.sort(xml_list_val)
# 对训练数据集对应的xml进行coco转换
convert(xml_list_train, save_json_train)
# 对验证数据集的xml进行coco转换
convert(xml_list_val, save_json_val)

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)