【数据挖掘】频繁模式挖掘及Python实现
1.理论背景在美国,著名的沃尔玛超市发现啤酒与尿布总是共同出现在购物车中,于是沃尔玛超市经过分析发现许多美国年轻的父亲下班之后经常要去购买婴儿的尿布,而在购买尿布的同时,他们往往会顺手购买一些啤酒;因此沃尔玛超市将啤酒与尿布放在相近的位置,方便顾客购买,并明显提高了销售额。这是频繁模式挖掘的一个经典例子——"啤酒和尿布"。简单来说,频繁模式就是当出现物品A时也经常出现物品B,比如在分析超市的购物清
1.理论背景
在美国,著名的沃尔玛超市发现啤酒与尿布总是共同出现在购物车中,于是沃尔玛超市经过分析发现许多美国年轻的父亲下班之后经常要去购买婴儿的尿布,而在购买尿布的同时,他们往往会顺手购买一些啤酒;因此沃尔玛超市将啤酒与尿布放在相近的位置,方便顾客购买,并明显提高了销售额。这是频繁模式挖掘的一个经典例子——"啤酒和尿布"。简单来说,频繁模式就是当出现物品A时也经常出现物品B,比如在分析超市的购物清单时,发现买啤酒的人经常也买尿布。
购物篮分析(或是亲密性分析)是介绍频繁模式挖掘的最佳案例,它是众所周知的频繁模式挖掘应用之一。购物篮分析试图从消费者加入购物篮的商品中挖掘出某种模式或者关联,可以是真实的购物篮,也可以是虚拟的,并且给出支持度或是置信度。这一方法在用户行为分析中存在巨大的价值。将购物篮分析推而广之就成了频繁模式挖掘,实际上它与分类非常类似,只是通过相互的关联来预测属性或是属性的组合(不仅仅是预测类别)。因为关联不需要有标签的数据集,所以它属于无监督式学习。

2.基本概念
2.1频繁模式定义
频繁模式指的就是频繁出现在数据集中的模式,比如子序列、项集、子结果。研究频繁模式的目的是得到关联规则和其他的联系,并在实际中应用这些规则和联系。比如,频繁地同时出现在交易数据集中的商品(比如牛奶和面包)的集合是频繁项集;频繁的出现的一个购买顺序(先买笔记本,再买杀毒软件)是频繁子序列。
2.2相关概念定义
频繁项集一般是指频繁地在事务数据集中一起出现的商品的集合,如小卖部中被许多顾客频繁地一起购买的牛奶和面包。
频繁子序列,如顾客倾向于先购买便携机,再购买数码相机,然后再购买内存卡这样的模式就是一个(频繁)序列模式。
频繁子结构是指从图集合中挖掘频繁子图模式。子结构可能涉及不同的结构形式(例如,图、树或格),可以与项集或子序列结合在一起。如果一个子结构频繁地出现,则称它为(频繁)子结构模式。
关联规则是形如的蕴含式,其中
l且
,则X称为规则的条件,Y称为规则的结果。如果事务数据库D中有s%的事务包含
,则称关联规则
的支持度为s%。例如 牛奶=>鸡蛋【支持度=2%,置信度=60%】。关联规则意味着元素项之间“如果…那么…”的关系。
事务是由一组物品组成,可看作一个订单中的物品集合。
支持度是某几个物品一起出现在事物中的次数或在数据库中所占的比例。
置信度是在出现A时出现B的概率,就是P(B|A) = P(A B) / P(A)
![]()
频繁项集是满足最小支持度要求的项集,它给出经常在一起出现的元素项。
项集表示包含0个或者多个项的集合。如果一个项集包含k个项,则称为k项集 。
强关联规则表示同时满足最小支持度和最小置信度阈值要求的所有关联规则。
例如:假设最小置信度阈值为30%,最小置信度阈值为70%,而关联规则:购买面包⇒购买牛奶[支持度=50%,置信度=100%]的支持度和置信度都满足条件,则该规则为强关联规则。
2.3先验性质
- 关联规则挖掘的任务
①根据最小支持度阈值,找出数据集中所有的频繁项集;
②挖掘出频繁项集中满足最小支持度和最小置信度阈值要求的规则,得到强关联规则;
③对产生的强关联规则进行剪枝,找出有用的关联规则。
- 频繁项集的先验性质
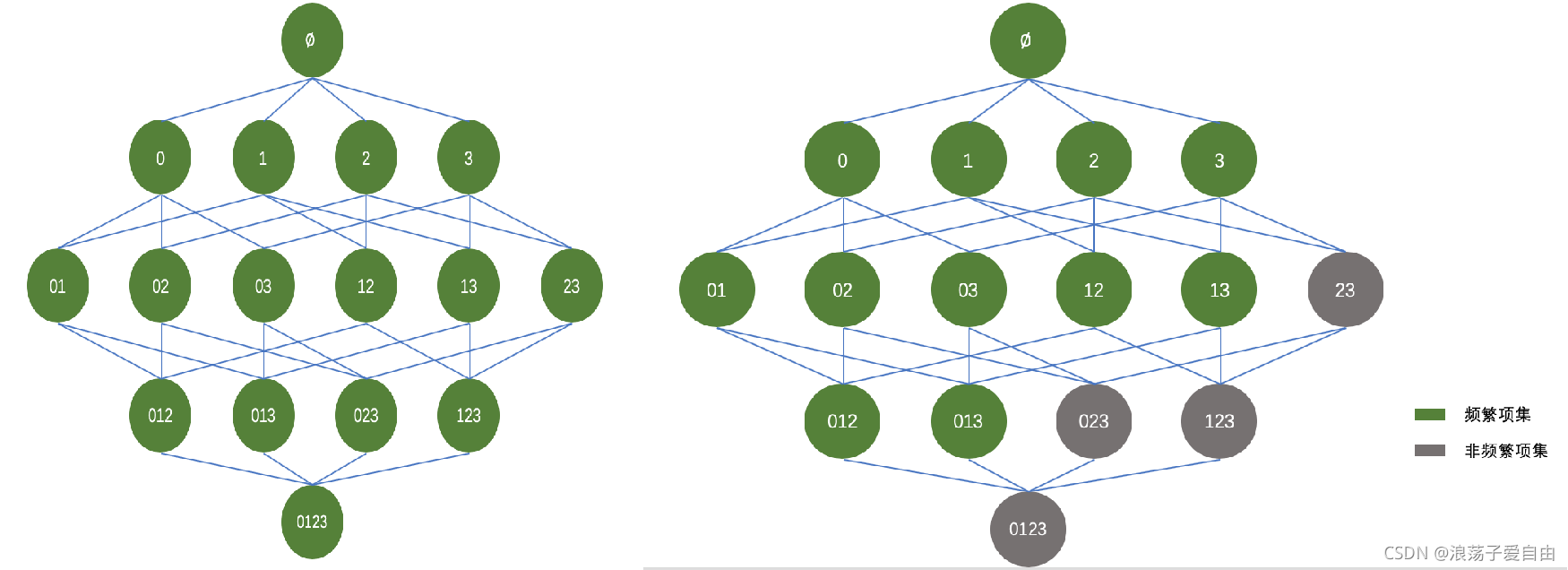
1.如果某个项集是频繁的,那么它的所有子集也是频繁的。例如如果{B,C}是频繁的,那么{B},{C}也一定是频繁的。
2.如果一个项集是非频繁集,那么它的所有超集(包含该非频繁集的父集)也是非频繁的。如果{A, B}是非频繁的,那么{A, B, C},{A, B, C, D}也一定是频繁的。
2.4 关联规则挖掘的步骤
- 找出所有频繁项集,即大于或等于最小支持度阈值的项集。
- 由频繁项集产生强关联规则,这些规则必须大于或等于最小支持度阈值和最小置信度阈值。
3 Apriori算法
3.1算法概述
Apriori算法是布尔关联规则挖掘频繁项集的原创性算法,该算法使用频繁项集性质的先验知识。Apriori使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描数据库,累积每个项(数据集不重复的元素)的计数,并收集满足最小支持度的项,找出频繁1项集的集合,并将集合记作L1。然后,L1用于找频繁2项集的集合L2,L2用于找L3,如此迭代,直到不能再找到频繁k项集。找每个Lk需要一次数据库全扫描。
3.2实现原理
算法实现过程分为两步,一步是连接,一步是剪枝。
输入:项集I,事务数据集D,最小支持度计数阈值Min_sup
输出:D中的所有频繁项集的集合L。
实现步骤:
(1)求频繁1项集L1 首先通过扫描事务数据集D,找出所有1项集并计算其支持度,作为候选1项集C1 然后从C1中删除低于最小支持度阈值Min_sup的项集,得到所有频繁1项集的集合L1 。
(2)For k=2,3,4,分别得到L2、L3、L4...Lk。
(3)连接:将Lk-1进行自身连接生成候选k项集的集合Ck,连接方法如下:对于任意p,q∈Lk-1,若按字典序有p={p1,p2,…,pk-2,pk-1}, q={p1,p2,…,pk-2,qk-1},且满足pk-1<qk-1,则把p和q连接成k项集 {p1,p2,…,pk-2,pk-1,qk-1}作为候选k项集Ck中的元素。
(4)剪枝:删除Ck中的非频繁k项集,即当Ck中一个候选k项集的某个k-1项子集不是Lk-1中的元素时,则将它从Ck中删除。
(5)计算支持数:通过扫描事务数据集D,计算Ck中每个k项集的支持数。
(6)求Lk:删除Ck中低于最小支持度阈值Min_sup的k项集,得到所有频繁k项集的集合Lk。 (7)若Lk=Ø,则转第(9)步
(8)END FOR
(9)另L=L1∪L2∪…∪Lk,并输出L。
强关联规则的生成过程包括两个步骤:
①对于所有频繁项集的集合L中的每个频繁项集X,生成X所有的非空真子集Y;
②对于X中的每一个非空真子集Y,构造关联规则Y⇒(X−Y) 。 构造出关联规则后,计算每一个关联规则的置信度,如果大于最小置信度阈值,则该规则为强关联规则。
--------------------------------------------------------------------------------------------------------------------------------
【注意】可以通过枚举频繁项集生成所有的关联规则,并通过计算关联规则的置信度来判断该规则是否为强关联规则。但当一个频繁项集包含的项很多时,就会生成大量的候选关联规则,1个频繁项集X能够生成个(即除去空集及自身之外的子集)候选关联规则。
3.3案例分析
假设使用表中的事务数据,该数据库具有9个事务,设最小支持度为2,试使用Apriori算法挖掘表1的事务数据中的频繁项集。
| TID | Items |
| 1 | 面包、可乐、麦片 |
| 2 | 牛奶、可乐 |
| 3 | 牛奶、面包、麦片 |
| 4 | 牛奶、可乐 |
| 5 | 面包、鸡蛋、麦片 |
| 6 | 牛奶、面包、可乐 |
| 7 | 牛奶、面包、鸡蛋、麦片 |
| 8 | 牛奶、面包、可乐 |
| 9 | 面包、可乐 |
实现过程:

对于上述例子中L中的频繁3项集{牛奶,面包,麦片},可以推导出非空子集:
{{牛奶},{面包},{麦片},{牛奶,面包},{牛奶,麦片},{面包,麦片}}。
可以构造的关联规则及置信度如下:
{牛奶} ⇒ {面包,麦片},置信度=2/6=33%
{面包} ⇒{牛奶,麦片},置信度=2/7=29%
{麦片} ⇒ {牛奶,面包},置信度=2/4=50%
{牛奶,面包} ⇒ {麦片},置信度=2/4=50%
{牛奶,麦片} ⇒ {面包},置信度=2/2=100%
{面包,麦片} ⇒ {牛奶},置信度=2/4=50%
如果令最小置信度为70%,则得到的强关联规则有:
{牛奶,麦片} ⇒ {面包},置信度=2/2=100%
3.4算法特点

3.5算法Python实现
可以通过模块efficient_apriori实现apriori算法,需要另外安装,输入如下命令安装,模块链接
pip install efficient-apriori- 案例1
from efficient_apriori import apriori
transactions = [('eggs', 'bacon', 'soup'),
('eggs', 'bacon', 'apple'),
('soup', 'bacon', 'banana')]
itemsets, rules = apriori(transactions, min_support=0.5, min_confidence=1)
print(rules) # [{eggs} -> {bacon}, {soup} -> {bacon}]【注意】在每笔有鸡蛋的交易中,也有培根。 因此,规则 {eggs} -> {bacon} 以 100% 的置信度返回。
- 案例2
from efficient_apriori import apriori
transactions = [('eggs', 'bacon', 'soup'),
('eggs', 'bacon', 'apple'),
('soup', 'bacon', 'banana')]
itemsets, rules = apriori(transactions, min_support=0.2, min_confidence=1)
# Print out every rule with 2 items on the left hand side,
# 1 item on the right hand side, sorted by lift
rules_rhs = filter(lambda rule: len(rule.lhs) == 2 and len(rule.rhs) == 1, rules)
for rule in sorted(rules_rhs, key=lambda rule: rule.lift):
print(rule) # Prints the rule and its confidence, support, lift, ...可以对返回的关联规则列表进行筛选和排序。
- 案例3
rom efficient_apriori import apriori
transactions = [('eggs', 'bacon', 'soup'),
('eggs', 'bacon', 'apple'),
('soup', 'bacon', 'banana')]
itemsets, rules = apriori(transactions, output_transaction_ids=True)
print(itemsets)
# {1: {('bacon',): ItemsetCount(itemset_count=3, members={0, 1, 2}), ...可以自己编写apriori算法实现过程,参考代码如下:
# -*- coding: utf-8 -*-
#加载数据集
def loadDataSet():
return [[1,3,4],[1,3,5],[2,3,4,5],[3,5],[2,3,5],[1,2,3,5],[2,5]]
#选取数据集的非重复元素组成候选集的集合C1
def createC1(dataSet):
C1=[]
for transaction in dataSet: #对数据集中的每条购买记录
for item in transaction: #对购买记录中的每个元素
if [item] not in C1: #注意,item外要加上[],便于与C1中的[item]对比
C1.append([item])
C1.sort()
return list(map(frozenset,C1)) #将C1各元素转换为frozenset格式,注意frozenset作用对象为可迭代对象
#由Ck产生Lk:扫描数据集D,计算候选集Ck各元素在D中的支持度,选取支持度大于设定值的元素进入Lk
def scanD(D,Ck,minSupport):
ssCnt={}
for tid in D: #对数据集中的每条购买记录
for can in Ck: #遍历Ck所有候选集
if can.issubset(tid): #如果候选集包含在购买记录中,计数+1
ssCnt[can]=ssCnt.get(can,0)+1
numItems=float(len(D)) #购买记录数
retList=[] #用于存放支持度大于设定值的项集
supportData={} #用于记录各项集对应的支持度
for key in ssCnt.keys():
support=ssCnt[key]/numItems
if support>=minSupport:
retList.insert(0,key)
supportData[key]=support
return retList,supportData
#由Lk产生Ck+1
def aprioriGen(Lk,k): #Lk的k和参数k不是同一个概念,Lk的k比参数k小1
retList=[]
lenLk=len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk): #比较Lk中的每一个元素与其他元素
L1=list(Lk[i])[:k-2];L2=list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1==L2: #若前k-2项相同,则合并这两项
retList.append(Lk[i]|Lk[j])
return retList
#Apriori算法主函数
def apriori(dataSet,minSupport=0.5):
C1=createC1(dataSet)
D=list(map(set,dataSet))
L1,supportData=scanD(D,C1,minSupport)
L=[L1]
k=2
while len(L[k-2])>0: #当L[k]为空时,停止迭代
Ck=aprioriGen(L[k-2],k) #L[k-2]对应的值是Lk-1
Lk,supK=scanD(D,Ck,minSupport)
supportData.update(supK)
L.append(Lk)
k+=1
return L,supportData
# 主函数,由频繁项集以及对应的支持度,得到各条规则的置信度,选择置信度满足要求的规则为关联规则
# 为了避免将所有数据都对比一遍,采用与上述相同的逻辑减少计算量——一层一层计算筛选
def generateRules(L,supportData,minConf=0.7):
bigRuleList=[]
for i in range(1,len(L)):
for freqSet in L[i]:
H1=[frozenset([item]) for item in freqSet] # H1是频繁项集单元素列表,是关联规则中a->b的b项
if i>1:
rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf)
else:
calConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
# 置信度计算函数
def calConf(freqSet,H,supportData,brl,minConf=0.7):
prunedH=[] # 用于存放置信度满足要求的关联规则的b项,即“提纯后的H”
for conseq in H:
conf=supportData[freqSet]/supportData[freqSet-conseq]
if conf>=minConf:
print (freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append([freqSet-conseq,conseq,conf])
prunedH.append(conseq)
return prunedH
# 关联规则合并函数
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m=len(H[0])
if len(freqSet)>(m+1): #查看频繁项集freqSet是否大到可以移除大小为m的子集
Hmp1=aprioriGen(H,m+1) # 从Hm合并Hm+1
Hmp1=calConf(freqSet,Hmp1,supportData,brl,minConf)
if len(Hmp1)>1: #若合并后的Hm+1的元素大于1个,则继续合并
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
dataset=loadDataSet()
C1=createC1(dataset)
D=list(map(set,dataset))
L1,supportData0=scanD(D,C1,0.5)
L,supportData=apriori(dataset,minSupport=0.5)
print(L)
L,supportData=apriori(dataset,minSupport=0.5)
rules=generateRules(L,supportData,minConf=0.5)4 FP-growth算法
4.1 算法概述
作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈。FP-growth算法是基于Apriori原理的,通过将数据集存储在FP(Frequent Pattern)树上发现频繁项集,但不能发现数据之间的关联规则。FP树是一种存储数据的树结构,如右图所示,每一路分支表示数据集的一个项集,数字表示该元素在某分支中出现的次数。如下图所示:

于是FP-Growth算法发现频繁项集的过程是:
(1)项头表的建立;
(2)构建FP树;
(3)从FP树中挖掘频繁项集。
【注意】无论多少数据,只需要扫描两次数据集,因此提高了算法运行的效率。
4.2 算法描述

4.3实现过程
第1步:项头表的建立。
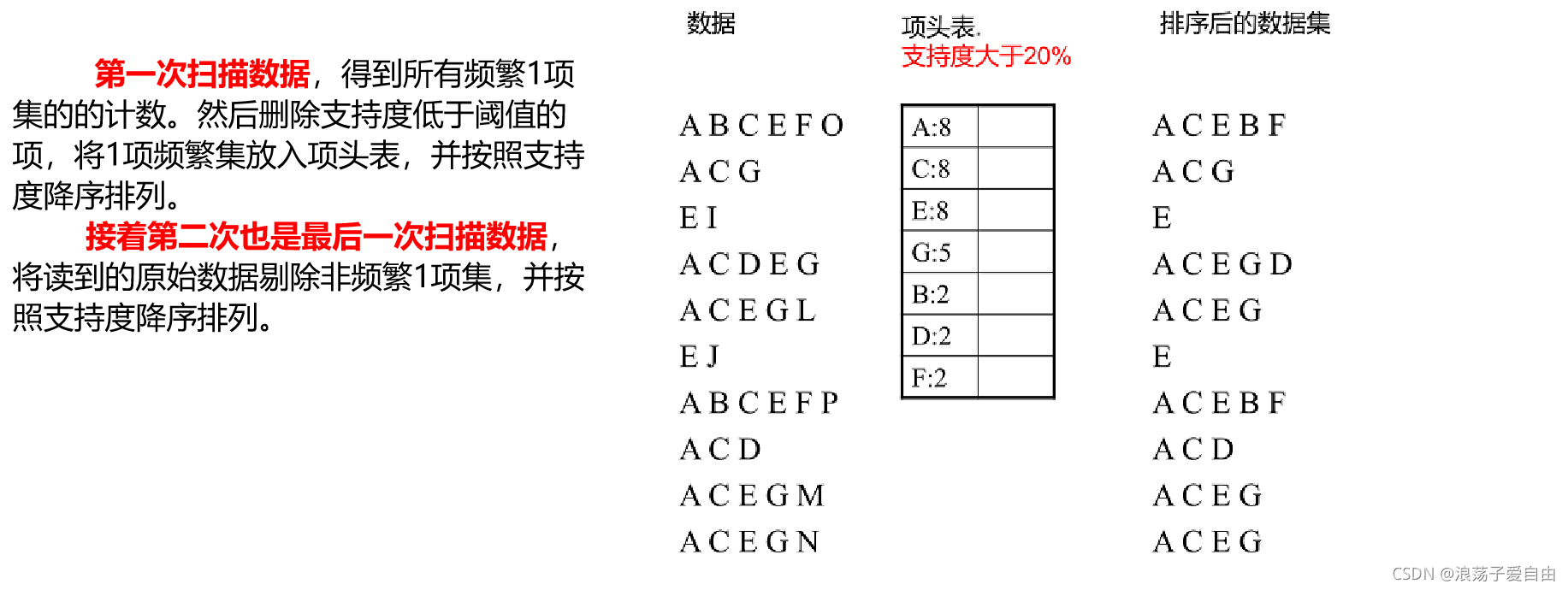
第2步:FP 树的建立。
有了项头表和排序后的数据集,就可以开始FP树的建立。
开始时FP树没有数据,建立FP树时我们一条条的读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。
如果有共用的祖先,则对应的共用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
详细的实现过程如下:






第3步:从FP树里挖掘频繁项集。
得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集。
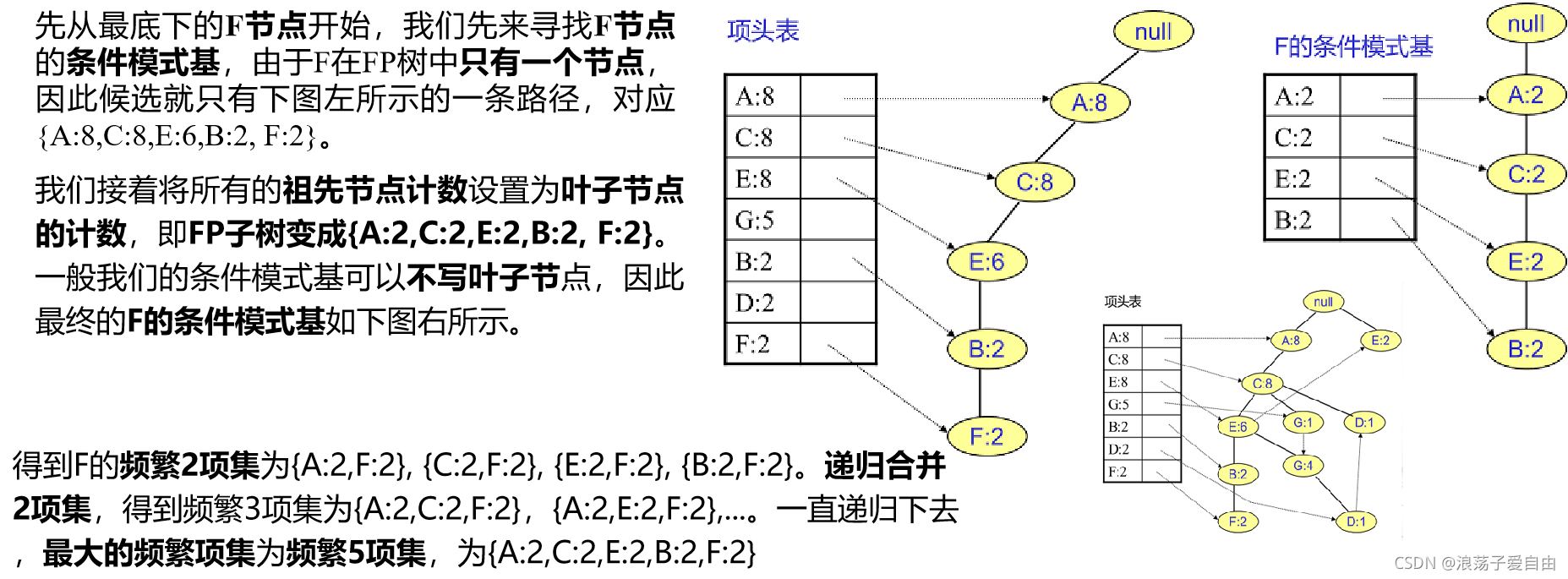



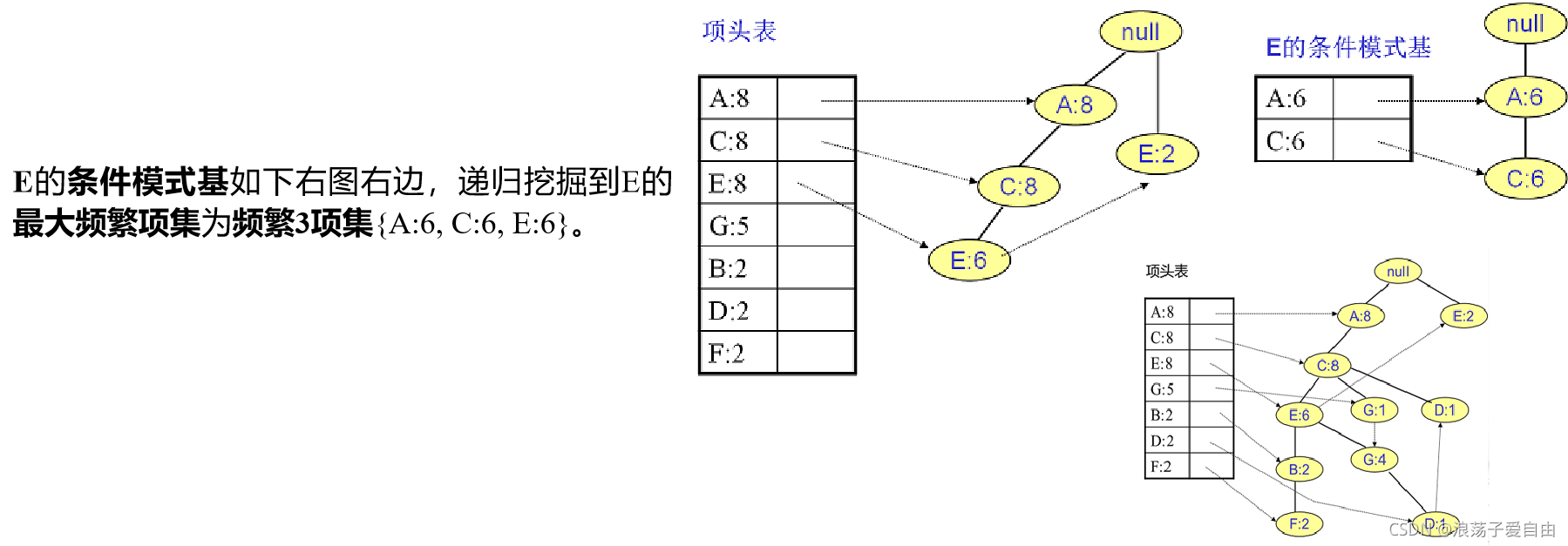

FP-growth算法实现步骤:

4.4案例分析
该数据集具有9个事务,设最小支持度为2,频繁项集的极大长度为3。试使用FP-growth算法挖掘表2的事务数据中的频繁项集。
| TID | Items |
| 1 | 面包、可乐、麦片 |
| 2 | 牛奶、可乐 |
| 3 | 牛奶、面包、麦片 |
| 4 | 牛奶、可乐 |
| 5 | 面包、鸡蛋、麦片 |
| 6 | 牛奶、面包、可乐 |
| 7 | 牛奶、面包、鸡蛋、麦片 |
| 8 | 牛奶、面包、可乐 |
| 9 | 面包、可乐 |







4.5算法特点

4.6 FP-Growth算法Python实现
根据算法实现步骤,不调用模块实现Fp-growth算法参考代码:
# -*- coding: utf-8 -*-
import operator
class treeNode:
def __init__(self,nameValue,numOccur,parentNode):
self.name=nameValue #节点名
self.count=numOccur #节点元素出现次数
self.nodeLink=None #存放节点链表中,与该节点相连的下一个元素
self.parent=parentNode
self.children={} #用于存放节点的子节点,value为子节点名
def inc(self,numOccur):
self.count+=numOccur
def disp(self,ind=1):
print(" "*ind,self.name,self.count) #输出一行节点名和节点元素数,缩进表示该行节点所处树的深度
for child in self.children.values():
child.disp(ind+1) #对于子节点,深度+1
# 构造FP树
# dataSet为字典类型,表示探索频繁项集的数据集,keys为各项集,values为各项集在数据集中出现的次数
# minSup为最小支持度,构造FP树的第一步是计算数据集各元素的支持度,选择满足最小支持度的元素进入下一步
def createTree(dataSet,minSup=1):
headerTable={}
#遍历各项集,统计数据集中各元素的出现次数
for key in dataSet.keys():
for item in key:
headerTable[item]=headerTable.get(item,0)+dataSet[key]
#遍历各元素,删除不满足最小支持度的元素
for key in list(headerTable.keys()):
if headerTable[key]<minSup:
del headerTable[key]
freqItemSet=set(headerTable.keys())
#若没有元素满足最小支持度要求,返回None,结束函数
if len(freqItemSet)==0:
return None,None
for key in headerTable.keys():
headerTable[key]=[headerTable[key],None] #[元素出现次数,**指向每种项集第一个元素项的指针**]
retTree=treeNode("Null Set",1,None) #初始化FP树的顶端节点
for tranSet,count in dataSet.items():
localD={} #存放每次循环中的频繁元素及其出现次数,便于利用全局出现次数对各项集元素进行项集内排序
for item in tranSet:
if item in freqItemSet:
localD[item]=headerTable[item][0]
if len(localD)>0:
orderedItems=[v[0] for v in sorted(localD.items(),key=operator.itemgetter(1),reverse=True)] #根据元素全局出现次数对每个项集(tranSet)中的元素进行排序
updateTree(orderedItems,retTree,headerTable,count) #使用排序后的项集对树进行填充
return retTree,headerTable
#树的更新函数
#items为按出现次数排序后的项集,是待更新到树中的项集;count为items项集在数据集中的出现次数
#inTree为待被更新的树;headTable为头指针表,存放满足最小支持度要求的所有元素
def updateTree(items,inTree,headerTable,count):
#若项集items当前最频繁的元素在已有树的子节点中,则直接增加树子节点的计数值,增加值为items[0]的出现次数
if items[0] in inTree.children:
inTree.children[items[0]].inc(count)
else:#若项集items当前最频繁的元素不在已有树的子节点中(即,树分支不存在),则通过treeNode类新增一个子节点
inTree.children[items[0]]=treeNode(items[0],count,inTree)
#若新增节点后表头表中没有此元素,则将该新增节点作为表头元素加入表头表
if headerTable[items[0]][1]==None:
headerTable[items[0]][1]=inTree.children[items[0]]
else:#若新增节点后表头表中有此元素,则更新该元素的链表,即,在该元素链表末尾增加该元素
updateHeader(headerTable[items[0]][1],inTree.children[items[0]])
#对于项集items元素个数多于1的情况,对剩下的元素迭代updateTree
if len(items)>1:
updateTree(items[1::],inTree.children[items[0]],headerTable,count)
#元素链表更新函数
#nodeToTest为待被更新的元素链表的头部
#targetNode为待加入到元素链表的元素节点
def updateHeader(nodeToTest,targetNode):
#若待被更新的元素链表当前元素的下一个元素不为空,则一直迭代寻找该元素链表的末位元素
while nodeToTest.nodeLink!=None:
nodeToTest=nodeToTest.nodeLink #类似撸绳子,从首位一个一个逐渐撸到末位
#找到该元素链表的末尾元素后,在此元素后追加targetNode为该元素链表的新末尾元素
nodeToTest.nodeLink=targetNode
#加载简单数据集
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
#将列表格式的数据集转化为字典格式
def createInitSet(dataSet):
retDict={}
for trans in dataSet:
retDict[frozenset(trans)]=1
return retDict
#由叶节点回溯该叶节点所在的整条路径
#leafNode为叶节点,treeNode格式;prefixPath为该叶节点的前缀路径集合,列表格式,在调用该函数前注意prefixPath的已有内容
def ascendTree(leafNode,prefixPath):
if leafNode.parent!=None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent,prefixPath)
#获得指定元素的条件模式基
#basePat为指定元素;treeNode为指定元素链表的第一个元素节点,如指定"r"元素,则treeNode为r元素链表的第一个r节点
def findPrefixPath(basePat,treeNode):
condPats={} #存放指定元素的条件模式基
while treeNode!=None: #当元素链表指向的节点不为空时(即,尚未遍历完指定元素的链表时)
prefixPath=[]
ascendTree(treeNode,prefixPath) #回溯该元素当前节点的前缀路径
if len(prefixPath)>1:
condPats[frozenset(prefixPath[1:])]=treeNode.count #构造该元素当前节点的条件模式基
treeNode=treeNode.nodeLink #指向该元素链表的下一个元素
return condPats
#有FP树挖掘频繁项集
#inTree: 构建好的整个数据集的FP树
#headerTable: FP树的头指针表
#minSup: 最小支持度,用于构建条件FP树
#preFix: 新增频繁项集的缓存表,set([])格式
#freqItemList: 频繁项集集合,list格式
def mineTree(inTree,headerTable,minSup,preFix,freqItemList):
#按头指针表中元素出现次数升序排序,即,从头指针表底端开始寻找频繁项集
bigL=[v[0] for v in sorted(headerTable.items(),key=lambda p:p[1][0])]
for basePat in bigL:
#将当前深度的频繁项追加到已有频繁项集中,然后将此频繁项集追加到频繁项集列表中
newFreqSet=preFix.copy()
newFreqSet.add(basePat)
print("freqItemList add newFreqSet",newFreqSet)
freqItemList.append(newFreqSet)
#获取当前频繁项的条件模式基
condPatBases=findPrefixPath(basePat,headerTable[basePat][1])
#利用当前频繁项的条件模式基构建条件FP树
myCondTree,myHead=createTree(condPatBases,minSup)
#迭代,直到当前频繁项的条件FP树为空
if myHead!=None:
mineTree(myCondTree,myHead,minSup,newFreqSet,freqItemList)
simpDat=loadSimpDat()
dataSet=createInitSet(simpDat)
myFPtree1,myHeaderTab1=createTree(dataSet,minSup=3)
myFPtree1.disp(),myHeaderTab1
freqItems=[]
mineTree(myFPtree1,myHeaderTab1,3,set([]),freqItems)
freqItems5 压缩频繁项集
5.1 真超集与真子集
如果一个集合S2中的每个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S1就是S2的一个超集,反过来,S2是S1的子集。 S1是S2的超集,若S1中一定有S2中没有的元素,则S1是S2的真超集,反过来S2是S1的真子集。
5.2 频繁闭项集
如果在数据集中不存在频繁项集X的真超项集Y,使得X、Y的支持度相等,那么称项集X是这个数据集的频繁闭项集。
5.3极大(最大)频繁项集
如果在数据集中不存在频繁项集X的真超项集Y,使得X属于 Y并且Y也是频繁项集,那么称项集X是这个数据集的极大(最大)频繁项集。
可以推导出极大频繁项集是闭频繁项集,而闭频繁项集不一定是极大频繁项集。
6关联模式评
6.1支持度与置信度
支持度用于筛选出频繁项集,但是该度量有一个缺点,一些支持度较低、但让人感兴趣的模式会被忽略掉,模式毕竟是只出现在部分数据中的,因此使用支持度度量可能会出现这种情况。
置信度用于评估规则的可信程度,但是该度量有一个缺点,没有考虑规则后件的支持度问题。
6.2相关性分析





5.3模式评估度量



【参考资料】

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)