pytorch实现二分类模型
使用的数据集是iris一共150行数据,三种花各有50行数据,这里取了前100行,选两种花进行二分类。import torchimport numpy as npimport pandas as pdimport torch.nn as nnimport matplotlib.pyplot as pltimport torch.nn.functional as Ffrom torch.utils.
·
使用的数据集是iris
一共150行数据,
三种花各有50行数据,
这里取了前100行,
选两种花进行二分类。
数据集地址:https://github.com/hydra-ZD/AI/blob/main/iris.data

import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
from torch.utils.data import TensorDataset
class dataset(Dataset):
def __init__(self):
data = pd.read_csv('c:/Users/Administrator/Desktop/iris/iris.data',names=['sepal_length','sepal_width','petal_length','petal_width','y'])
data['new_y'] = data.iloc[:,[4]].replace(['Iris-setosa','Iris-versicolor','Iris-virginica'],[0,1,2])
self.X = torch.FloatTensor(np.array(data.iloc[:100,[0,1,2,3]]))
self.y = torch.FloatTensor(np.array(data.iloc[:100,[5]]))
self.len = len(self.X)
def __getitem__(self,index):
return self.X[index],self.y[index]
def __len__(self):
return self.len
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
y_pred = self.sigmoid(self.linear(x))
return y_pred
data = dataset()
# 随机分成训练集和测试集,训练集占70%
train_set, test_set = random_split(data, [int(data.len*0.7), data.len-int(data.len*0.7)])
# 加载训练集
train_loader = DataLoader(dataset=train_set,
batch_size=8,
shuffle=True,)
# 加载测试集
test_loader = DataLoader(dataset=test_set,
batch_size=8,
shuffle=True,)
model = Model()
# 使用BCE(Binary Cross Entropy)二元交叉熵损失函数
criterion = nn.BCELoss()
# 使用Adam优化算法
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 用于存放loss
loss_list = []
# 对整个样本训练10次
for epoch in range(10):
# 每次训练一个minibatch
for i, (X, y) in enumerate(train_loader):
# 进行预测,也就是做了一次前向传播
y_pred = model(X)
# 计算损失
loss = criterion(y_pred,y)
# 梯度归0
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 记录损失
loss_list.append(loss.data.item())
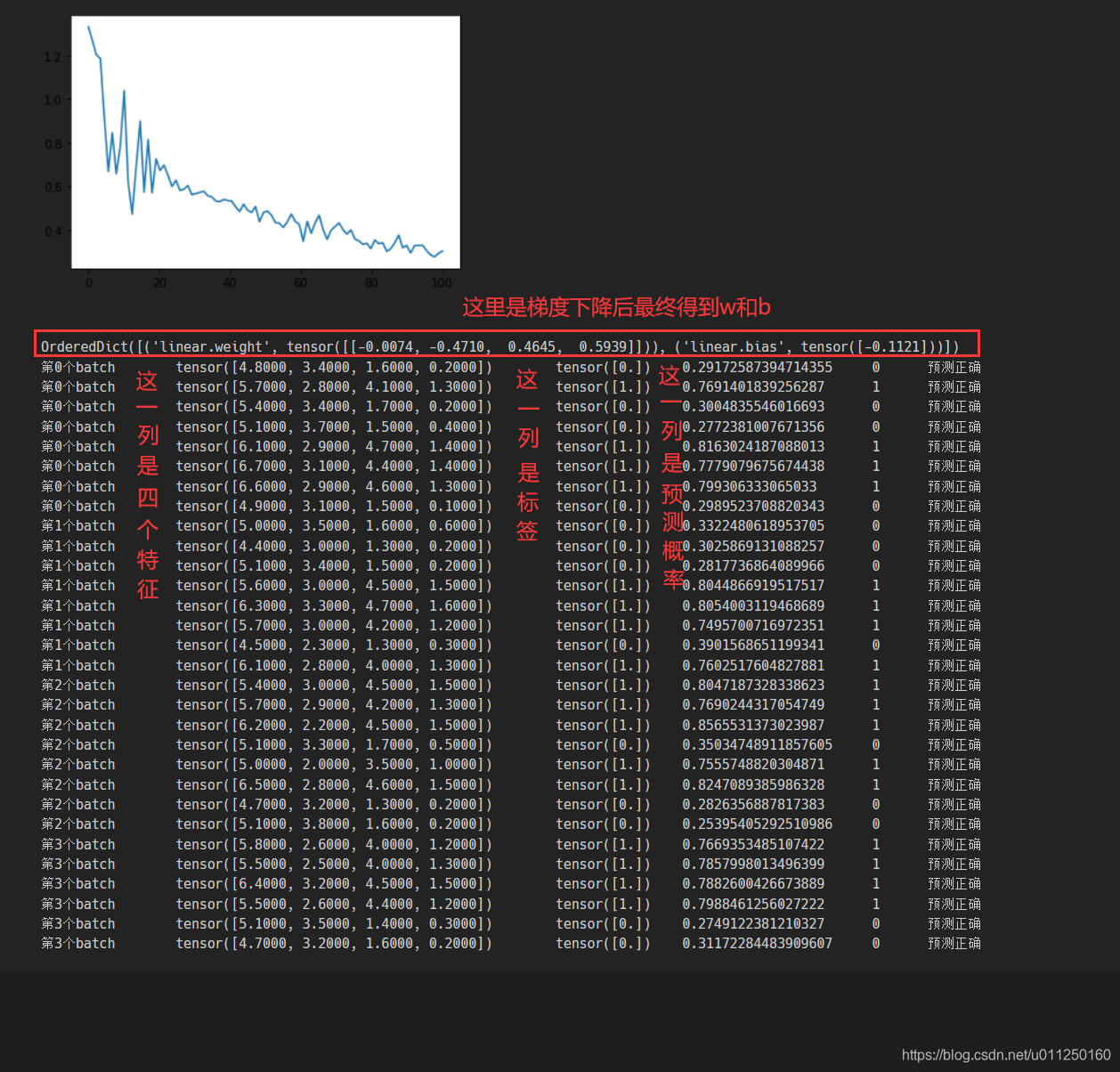
# 画出损失下降的图像
plt.plot(np.linspace(0,100,len(loss_list)),loss_list)
plt.show()
# 查看当前的训练参数,也就是w和b
print(model.state_dict())
# 使用测试集验证
for batch,(X, y) in enumerate(test_loader):
for (XX,yy) in zip(X,y):
# 进行预测,也就是做了一次前向传播
y_pred = model(XX)
y_pred = y_pred.data.item()
if y_pred>=0.5:
yy_pred = 1
else:
yy_pred = 0
print("第%d个batch\t"%batch,XX,'\t',yy,'\t',y_pred,'\t',yy_pred,end='')
if yy_pred == yy:
print('\t预测正确')
else:
print('\t预测错误')

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)