
【Python数据分析与可视化】关于星巴克数据分析与制图的九道题
我们留的作业。作业:本实训针对一组关于全球星巴克门店的统计数据,分析在不同国家和地区以及中国不同城市的星巴克门店的数量。获取数据打印出星巴克旗下有多少个品牌打印出全世界一共有多少个国家开设了星巴克门店,显示门店数量排名前10和后10的国家。用柱状图绘制排名前10的分布情况,横坐标有国家名,纵坐标为数量。显示拥有星巴克门店数量排名前10的城市。绘制星巴克门店数前10的城市分布柱状图,横坐标有城市名,
我们留的作业。
作业:本实训针对一组关于全球星巴克门店的统计数据,分析在不同国家和地区以及中国不同城市的星巴克门店的数量。
获取数据
打印出星巴克旗下有多少个品牌
打印出全世界一共有多少个国家开设了星巴克门店,显示门店数量排名前10和后10的国家。
用柱状图绘制排名前10的分布情况,横坐标有国家名,纵坐标为数量。
显示拥有星巴克门店数量排名前10的城市。
绘制星巴克门店数前10的城市分布柱状图,横坐标有城市名,纵坐标为数量。
按照星巴克门店在中国的分布情况,统计排名前10的城市。
绘制柱状图,横坐标有城市名,纵坐标为数量。
用饼状图显示星巴克门店的经营方式有几种。(ownership)
源文件保存至桌面吧
源代码在后面。
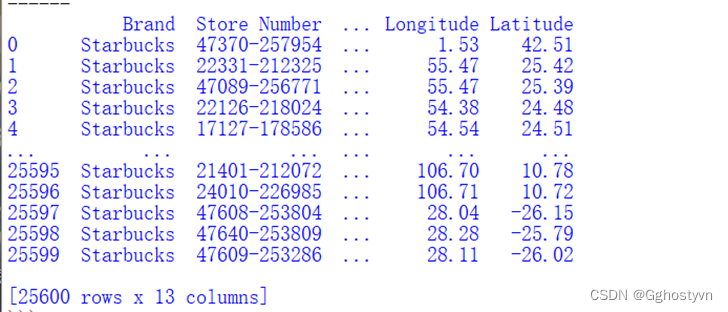
1.获取数据

结果:
2.打印出星巴克旗下有多少个品牌

结果:

3.打印出全世界一共有多少个国家开设了星巴克门店,显示门店数量排名前10和后10的国家
结果:
|
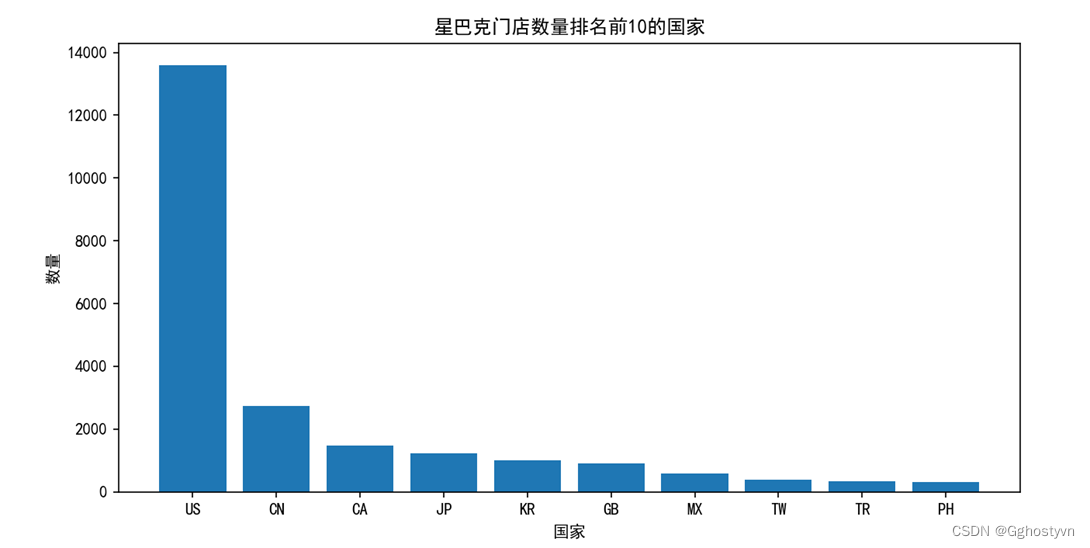
4. 用柱状图绘制排名前10的分布情况,横坐标有国家名,纵坐标为数量。

结果:
5、显示拥有星巴克门店数量排名前10的城市。

结果:
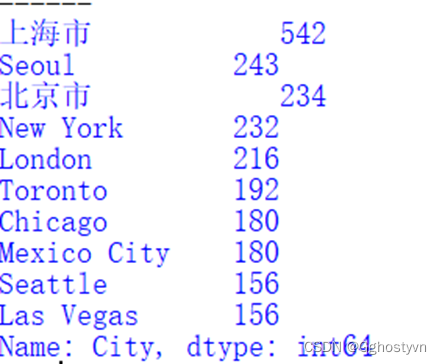
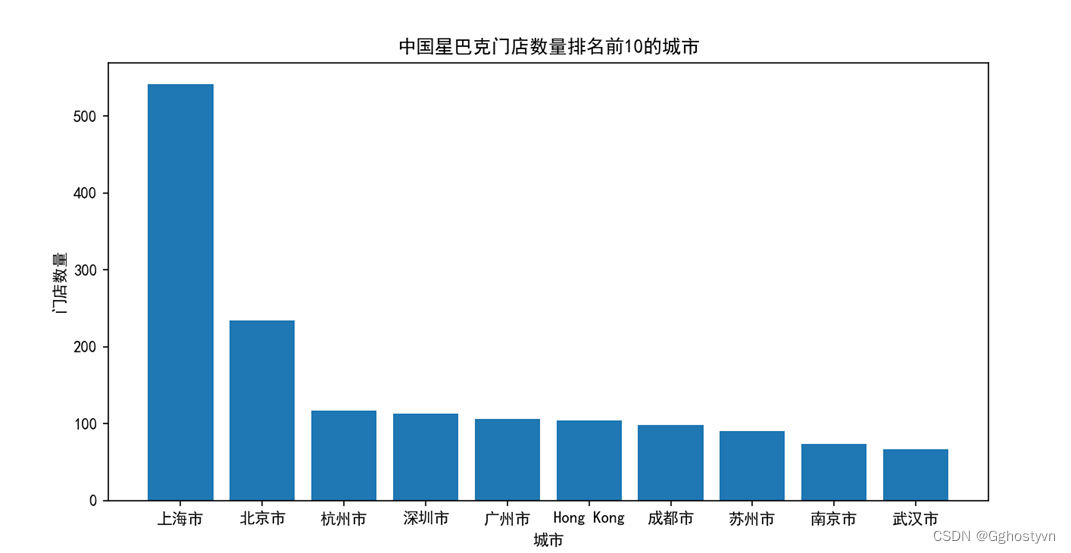
6.绘制星巴克门店数前10的城市分布柱状图,横坐标有城市名,纵坐标为数量。
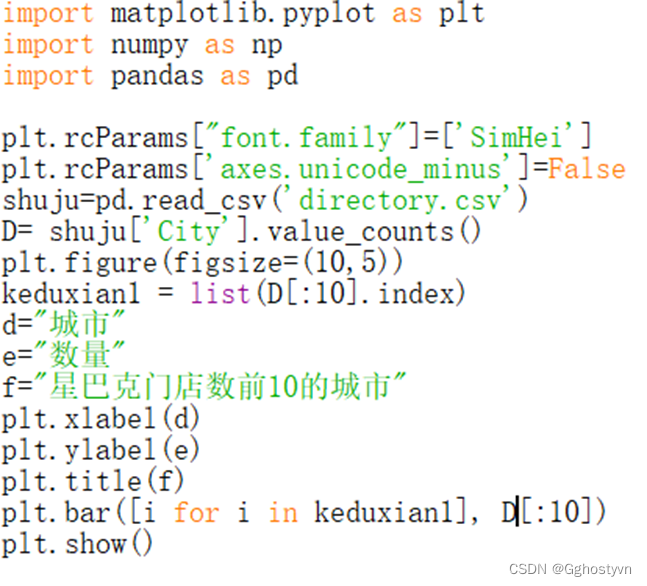
结果:
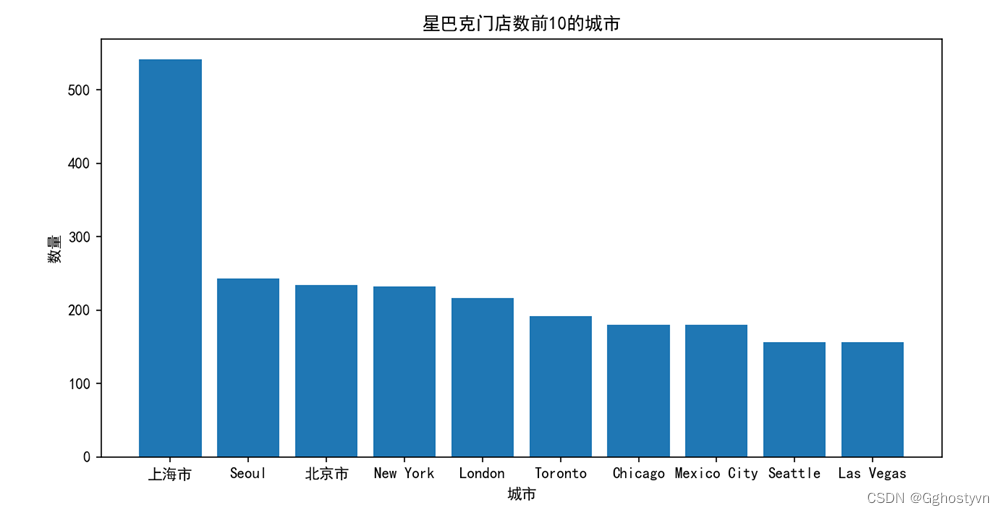
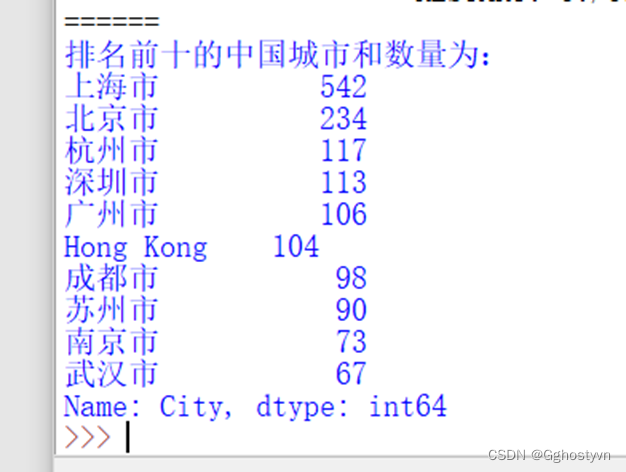
7.按照星巴克门店在中国的分布情况,统计排名前10的城市。
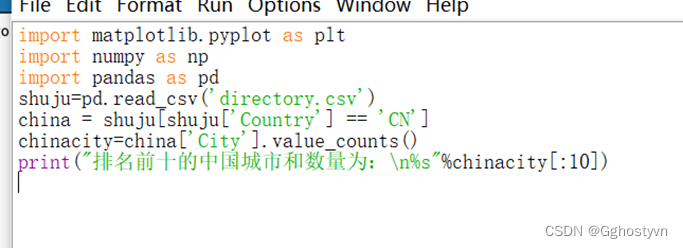
结果:
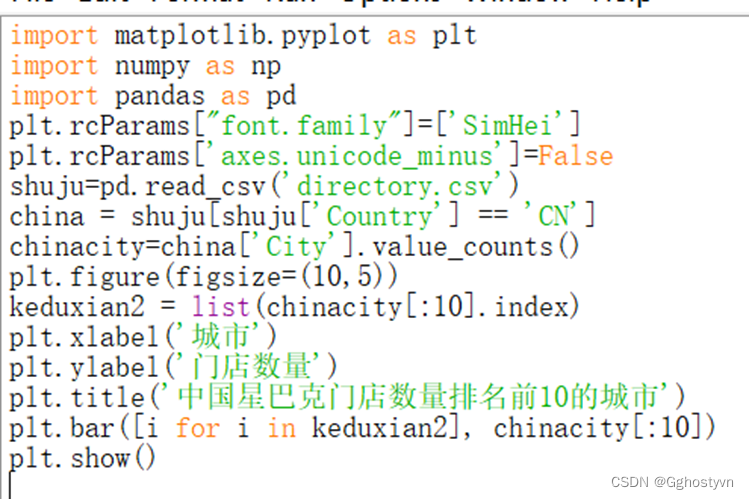
8.绘制柱状图,横坐标有城市名,纵坐标为数量。
结果 :
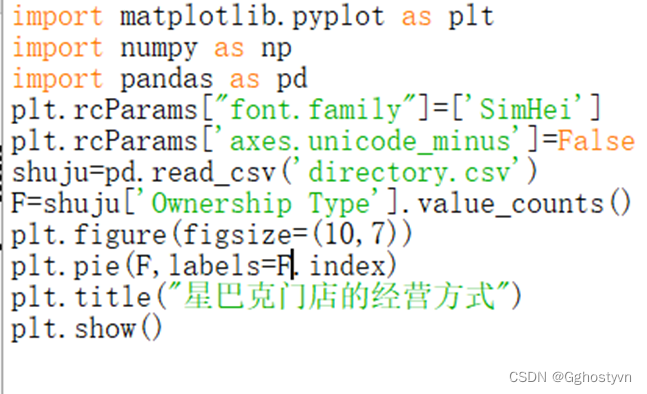
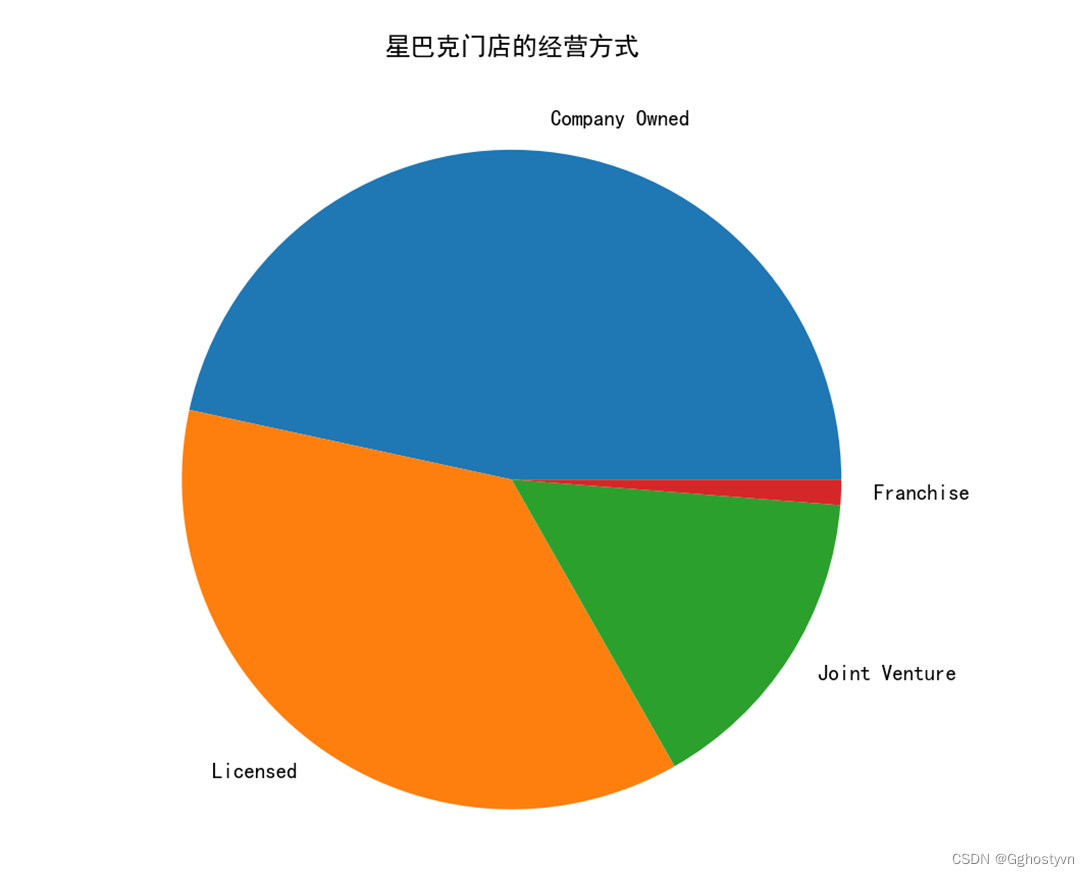
9、用饼状图显示星巴克门店的经营方式有几种。(ownership)
结果:
源文件:
1.
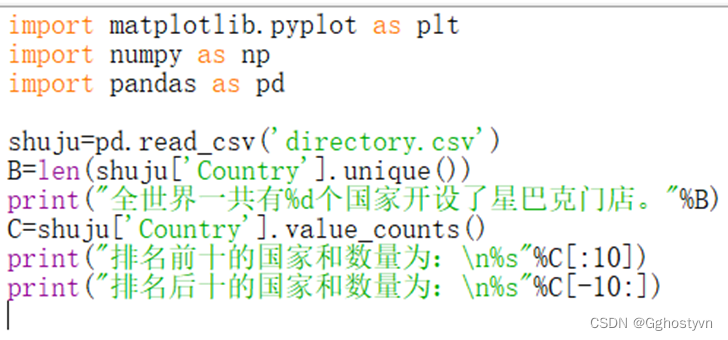
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
shuju=pd.read_csv('directory.csv')
print(shuju)
2.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
shuju=pd.read_csv('directory.csv')
A=shuju['Brand'].value_counts()
print("星巴克旗下品牌有:\n%s"%A)
3.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
shuju=pd.read_csv('directory.csv')
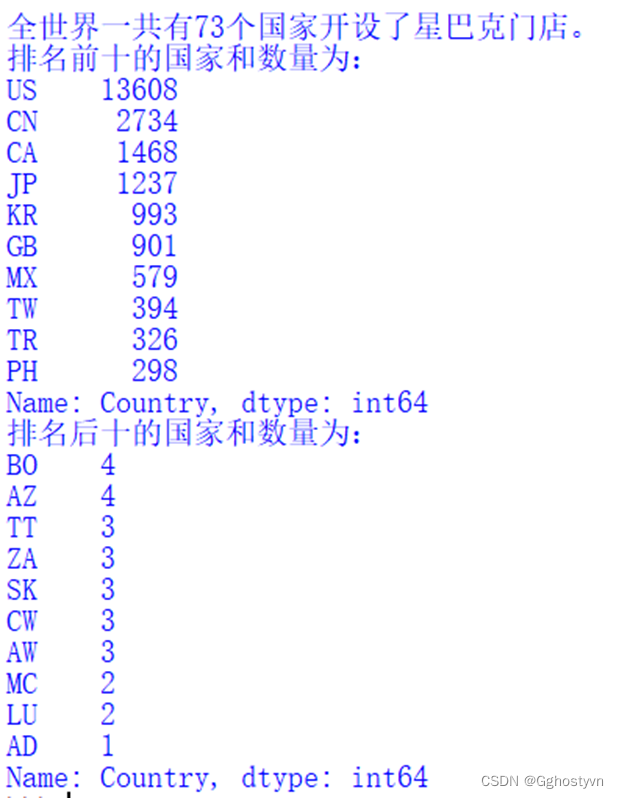
B=len(shuju['Country'].unique())
print("全世界一共有%d个国家开设了星巴克门店。"%B)
C=shuju['Country'].value_counts()
print("排名前十的国家和数量为:\n%s"%C[:10])
print("排名后十的国家和数量为:\n%s"%C[-10:])
4.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['axes.unicode_minus']=False
shuju=pd.read_csv('directory.csv')
C=shuju['Country'].value_counts()
plt.figure(figsize=(10,5))
keduxian = list(C[:10].index)
a="国家"
b="数量"
c="星巴克门店数量排名前10的国家"
plt.xlabel(a)
plt.ylabel(b)
plt.title(c)
plt.bar([i for i in keduxian], C[:10])
plt.show()
5.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
shuju=pd.read_csv('directory.csv')
D= shuju['City'].value_counts()
print(D[:10])
6.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['axes.unicode_minus']=False
shuju=pd.read_csv('directory.csv')
D= shuju['City'].value_counts()
plt.figure(figsize=(10,5))
keduxian1 = list(D[:10].index)
d="城市"
e="数量"
f="星巴克门店数前10的城市"
plt.xlabel(d)
plt.ylabel(e)
plt.title(f)
plt.bar([i for i in keduxian1], D[:10])
plt.show()
7.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
shuju=pd.read_csv('directory.csv')
china = shuju[shuju['Country'] == 'CN']
chinacity=china['City'].value_counts()
print("排名前十的中国城市和数量为:\n%s"%chinacity[:10])
8.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['axes.unicode_minus']=False
shuju=pd.read_csv('directory.csv')
china = shuju[shuju['Country'] == 'CN']
chinacity=china['City'].value_counts()
plt.figure(figsize=(10,5))
keduxian2 = list(chinacity[:10].index)
plt.xlabel('城市')
plt.ylabel('门店数量')
plt.title('中国星巴克门店数量排名前10的城市')
plt.bar([i for i in keduxian2], chinacity[:10])
plt.show()
9.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams["font.family"]=['SimHei']
plt.rcParams['axes.unicode_minus']=False
shuju=pd.read_csv('directory.csv')
F=shuju['Ownership Type'].value_counts()
plt.figure(figsize=(10,7))
plt.pie(F,labels=F.index)
plt.title("星巴克门店的经营方式")
plt.show()
自己也是新手,英语不好,名称定义中文拼音。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)